RAG Evaluation with Langchain and RAGAS
Building and evaluating Q&A Application using Knowledge Bases for Amazon Bedrock using RAG Assessment (RAGAS) framework
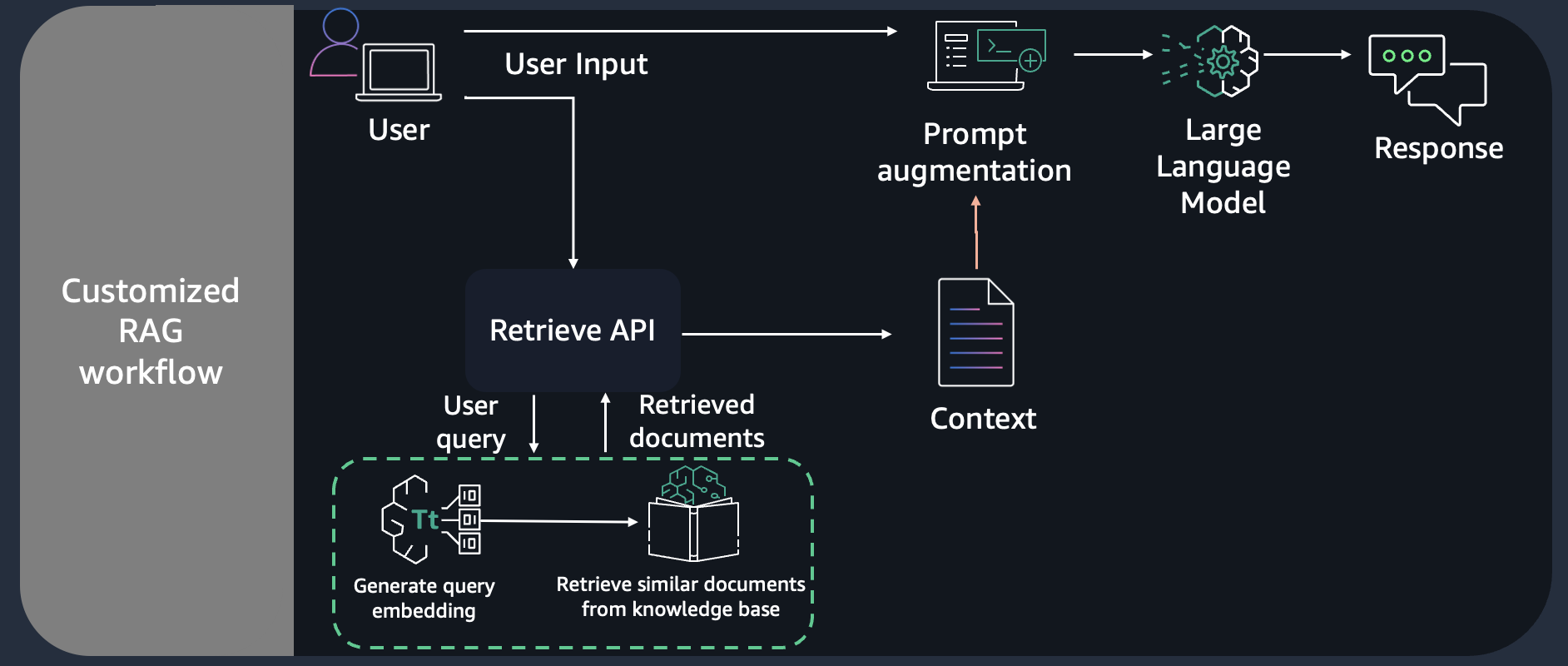
Context
In this notebook, we will dive deep into building Q&A application using Retrieve API provide by Knowledge Bases for Amazon Bedrock, along with LangChain and RAGAS for evaluating the responses. Here, we will query the knowledge base to get the desired number of document chunks based on similarity search, prompt the query using Anthropic Claude, and then evaluate the responses effectively using evaluation metrics, such as faithfulness, answer_relevancy, context_recall, context_precision, context_entity_recall, answer_similarity, answer_correctness, harmfulness, maliciousness, coherence, correctness and conciseness.
Knowledge Bases for Amazon Bedrock Introduction
With knowledge bases, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for Retrieval Augmented Generation (RAG). Access to additional data helps the model generate more relevant, context-specific, and accurate responses without continuously retraining the FM. All information retrieved from knowledge bases comes with source attribution to improve transparency and minimize hallucinations. For more information on creating a knowledge base using console, please refer to this post.
Pattern
We can implement the solution using Retreival Augmented Generation (RAG) pattern. RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context. Here, we are performing RAG effectively on the knowledge base created in the previous notebook or using console.
Pre-requisite
Before being able to answer the questions, the documents must be processed and stored in a knowledge base. For this notebook, we use a synthetic dataset for 10K financial reports to create the Knowledge Bases for Amazon Bedrock.
- Upload your documents (data source) to Amazon S3 bucket.
- Knowledge Bases for Amazon Bedrock using 01_create_ingest_documents_test_kb_multi_ds.ipynb
- Note the Knowledge Base ID

Notebook Walkthrough
For our notebook we will use the Retreive API provided by Knowledge Bases for Amazon Bedrock which converts user queries into embeddings, searches the knowledge base, and returns the relevant results, giving you more control to build custom workflows on top of the semantic search results. The output of the Retrieve API includes the the retrieved text chunks, the location type and URI of the source data, as well as the relevance scores of the retrievals.
We will then use the text chunks being generated and augment it with the original prompt and pass it through the anthropic.claude-3-haiku-20240307-v1:0 model.
Finally we will evaluate the generated responses using RAGAS on using metrics such as faithfulness, answer relevancy,and context precision. For evaluation, we will use anthropic.claude-3-sonnet-20240229-v1:0.
Ask question
Evaluation
- Utilize RAGAS for evaluation on:
- Faithfulness: This measures the factual consistency of the generated answer against the given context. It is calculated from answer and retrieved context. The answer is scaled to (0,1) range. Higher the better.
- Answer Relevance: The evaluation metric, Answer Relevancy, focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information and higher scores indicate better relevancy. This metric is computed using the question, the context and the answer. Please note, that eventhough in practice the score will range between 0 and 1 most of the time, this is not mathematically guaranteed, due to the nature of the cosine similarity ranging from -1 to 1.
- Context Precision: Context Precision is a metric that evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Ideally all the relevant chunks must appear at the top ranks. This metric is computed using the question, ground_truth and the contexts, with values ranging between 0 and 1, where higher scores indicate better precision.
- Context Recall: Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on the ground truth and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance.
- Context entities recall: This metric gives the measure of recall of the retrieved context, based on the number of entities present in both ground_truths and contexts relative to the number of entities present in the ground_truths alone. Simply put, it is a measure of what fraction of entities are recalled from ground_truths. This metric is useful in fact-based use cases like tourism help desk, historical QA, etc. This metric can help evaluate the retrieval mechanism for entities, based on comparison with entities present in ground_truths, because in cases where entities matter, we need the contexts which cover them.
- Answer Semantic Similarity: The concept of Answer Semantic Similarity pertains to the assessment of the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth and the answer, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth.
- Answer Correctness: The assessment of Answer Correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness. Answer correctness encompasses two critical aspects: semantic similarity between the generated answer and the ground truth, as well as factual similarity. These aspects are combined using a weighted scheme to formulate the answer correctness score. Users also have the option to employ a ‘threshold’ value to round the resulting score to binary, if desired.
- Aspect Critique: This is designed to assess submissions based on predefined aspects such as harmlessness and correctness. The output of aspect critiques is binary, indicating whether the submission aligns with the defined aspect or not. This evaluation is performed using the ‘answer’ as input.
USE CASE:
Dataset
In this example, you will use Octank's financial 10k reports (sythetically generated dataset) as a text corpus to perform Q&A on. This data is already ingested into the knowledge base. You will need the knowledge base id to run this example. In your specific use case, you can sync different files for different domain topics and query this notebook in the same manner to evaluate model responses using the retrieve API from knowledge bases.
Python 3.10
⚠ For this lab we need to run the notebook based on a Python 3.10 runtime. ⚠
Setup
To run this notebook you would need to install dependencies, langchain and RAGAS and the updated boto3, botocore whls.
%pip install --force-reinstall -q -r ../requirements.txt
Restart the kernel with the updated packages that are installed through the dependencies above
<h2>restart kernel</h2>
from IPython.core.display import HTML
HTML("<script>Jupyter.notebook.kernel.restart()</script>")
Follow the steps below to set up necessary packages
- Import the necessary libraries for creating
bedrock-runtimefor invoking foundation models andbedrock-agent-runtimeclient for using Retrieve API provided by Knowledge Bases for Amazon Bedrock. - Import Langchain for:
- Initializing bedrock model
anthropic.claude-3-haiku-20240307-v1:0as our large language model to perform query completions using the RAG pattern. - Initializing bedrock model
anthropic.claude-3-sonnet-20240229-v1:0as our large language model to perform RAG evaluation. - Initialize Langchain retriever integrated with knowledge bases.
- Later in the notebook we will wrap the LLM and retriever with
RetrieverQAChainfor building our Q&A application.
%store -r kb_id
<h2>kb_id = "<<knowledge_base_id>>" # Replace with your knowledge base id here.</h2>
import boto3
import pprint
from botocore.client import Config
from langchain.llms.bedrock import Bedrock
from langchain_community.chat_models.bedrock import BedrockChat
from langchain.embeddings import BedrockEmbeddings
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
from langchain.chains import RetrievalQA
pp = pprint.PrettyPrinter(indent=2)
bedrock_config = Config(connect_timeout=120, read_timeout=120, retries={'max_attempts': 0})
bedrock_client = boto3.client('bedrock-runtime')
bedrock_agent_client = boto3.client("bedrock-agent-runtime",
config=bedrock_config
)
llm_for_text_generation = BedrockChat(model_id="anthropic.claude-3-haiku-20240307-v1:0", client=bedrock_client)
llm_for_evaluation = BedrockChat(model_id="anthropic.claude-3-sonnet-20240229-v1:0", client=bedrock_client)
bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0",client=bedrock_client)
Retrieve API: Process flow
Create a AmazonKnowledgeBasesRetriever object from LangChain which will call the Retreive API provided by Knowledge Bases for Amazon Bedrock which converts user queries into embeddings, searches the knowledge base, and returns the relevant results, giving you more control to build custom workflows on top of the semantic search results. The output of the Retrieve API includes the the retrieved text chunks, the location type and URI of the source data, as well as the relevance scores of the retrievals.
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=kb_id,
retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 5}},
# endpoint_url=endpoint_url,
# region_name="us-east-1",
# credentials_profile_name="<profile_name>",
)
score: You can view the associated score of each of the text chunk that was returned which depicts its correlation to the query in terms of how closely it matches it.
Model Invocation and Response Generation using RetrievalQA chain
Invoke the model and visualize the response
Question = Provide a list of few risks for Octank financial in numbered list without description."
Ground truth answer =
1. Commodity Prices
2. Foreign Exchange Rates
3. Equity Prices
4. Credit Risk
5. Liquidity Risk
...
...
query = "Provide a list of few risks for Octank financial in numbered list without description."
qa_chain = RetrievalQA.from_chain_type(
llm=llm_for_text_generation, retriever=retriever, return_source_documents=True
)
response = qa_chain.invoke(query)
print(response["result"])
Preparing the Evaluation Data
As RAGAS aims to be a reference-free evaluation framework, the required preparations of the evaluation dataset are minimal. You will need to prepare question and ground_truths pairs from which you can prepare the remaining information through inference as shown below. If you are not interested in the context_recall metric, you don’t need to provide the ground_truths information. In this case, all you need to prepare are the questions.
from datasets import Dataset
questions = [
"What was the primary reason for the increase in net cash provided by operating activities for Octank Financial in 2021?",
"In which year did Octank Financial have the highest net cash used in investing activities, and what was the primary reason for this?",
"What was the primary source of cash inflows from financing activities for Octank Financial in 2021?",
"Calculate the year-over-year percentage change in cash and cash equivalents for Octank Financial from 2020 to 2021.",
"Based on the information provided, what can you infer about Octank Financial's overall financial health and growth prospects?"
]
ground_truths = [
["The increase in net cash provided by operating activities was primarily due to an increase in net income and favorable changes in operating assets and liabilities."],
["Octank Financial had the highest net cash used in investing activities in 2021, at $360 million, compared to $290 million in 2020 and $240 million in 2019. The primary reason for this was an increase in purchases of property, plant, and equipment and marketable securities."],
["The primary source of cash inflows from financing activities for Octank Financial in 2021 was an increase in proceeds from the issuance of common stock and long-term debt."],
["To calculate the year-over-year percentage change in cash and cash equivalents from 2020 to 2021: \
2020 cash and cash equivalents: $350 million \
2021 cash and cash equivalents: $480 million \
Percentage change = (2021 value - 2020 value) / 2020 value * 100 \
= ($480 million - $350 million) / $350 million * 100 \
= 37.14% increase"],
["Based on the information provided, Octank Financial appears to be in a healthy financial position and has good growth prospects. The company has consistently increased its net cash provided by operating activities, indicating strong profitability and efficient management of working capital. Additionally, Octank Financial has been investing in long-term assets, such as property, plant, and equipment, and marketable securities, which suggests plans for future growth and expansion. The company has also been able to finance its growth through the issuance of common stock and long-term debt, indicating confidence from investors and lenders. Overall, Octank Financial's steady increase in cash and cash equivalents over the past three years provides a strong foundation for future growth and investment opportunities."]
]
answers = []
contexts = []
for query in questions:
answers.append(qa_chain.invoke(query)["result"])
contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])
<h2>To dict</h2>
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truths": ground_truths
}
<h2>Convert dict to dataset</h2>
dataset = Dataset.from_dict(data)
Evaluating the RAG application
First, import all the metrics you want to use from ragas.metrics. Then, you can use the evaluate() function and simply pass in the relevant metrics and the prepared dataset.
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
context_entity_recall,
answer_similarity,
answer_correctness
)
from ragas.metrics.critique import (
harmfulness,
maliciousness,
coherence,
correctness,
conciseness
)
#specify the metrics here
metrics = [
faithfulness,
answer_relevancy,
context_precision,
context_recall,
context_entity_recall,
answer_similarity,
answer_correctness,
harmfulness,
maliciousness,
coherence,
correctness,
conciseness
]
result = evaluate(
dataset = dataset,
metrics=metrics,
llm=llm_for_evaluation,
embeddings=bedrock_embeddings,
)
df = result.to_pandas()
Below, you can see the resulting RAGAS scores for the examples:
import pandas as pd
pd.options.display.max_colwidth = 800
df
Note: Please note the scores above gives a relative idea on the performance of your RAG application and should be used with caution and not as standalone scores. Also note, that we have used only 5 question/answer pairs for evaluation, as best practice, you should use enough data to cover different aspects of your document for evaluating model.
Based on the scores, you can review other components of your RAG workflow to further optimize the scores, few recommended options are to review your chunking strategy, prompt instructions, adding more numberOfResults for additional context and so on.