Accessing Amazon Neptune from AWS Lambda Functions
Amazon Neptune runs inside your private VPC and its endpoints can be accessed only by resources inside the VPC. To expose the endpoints outside the VPC you can use a load balancer - either an Application Load Balancer or a Network Load Balancer.
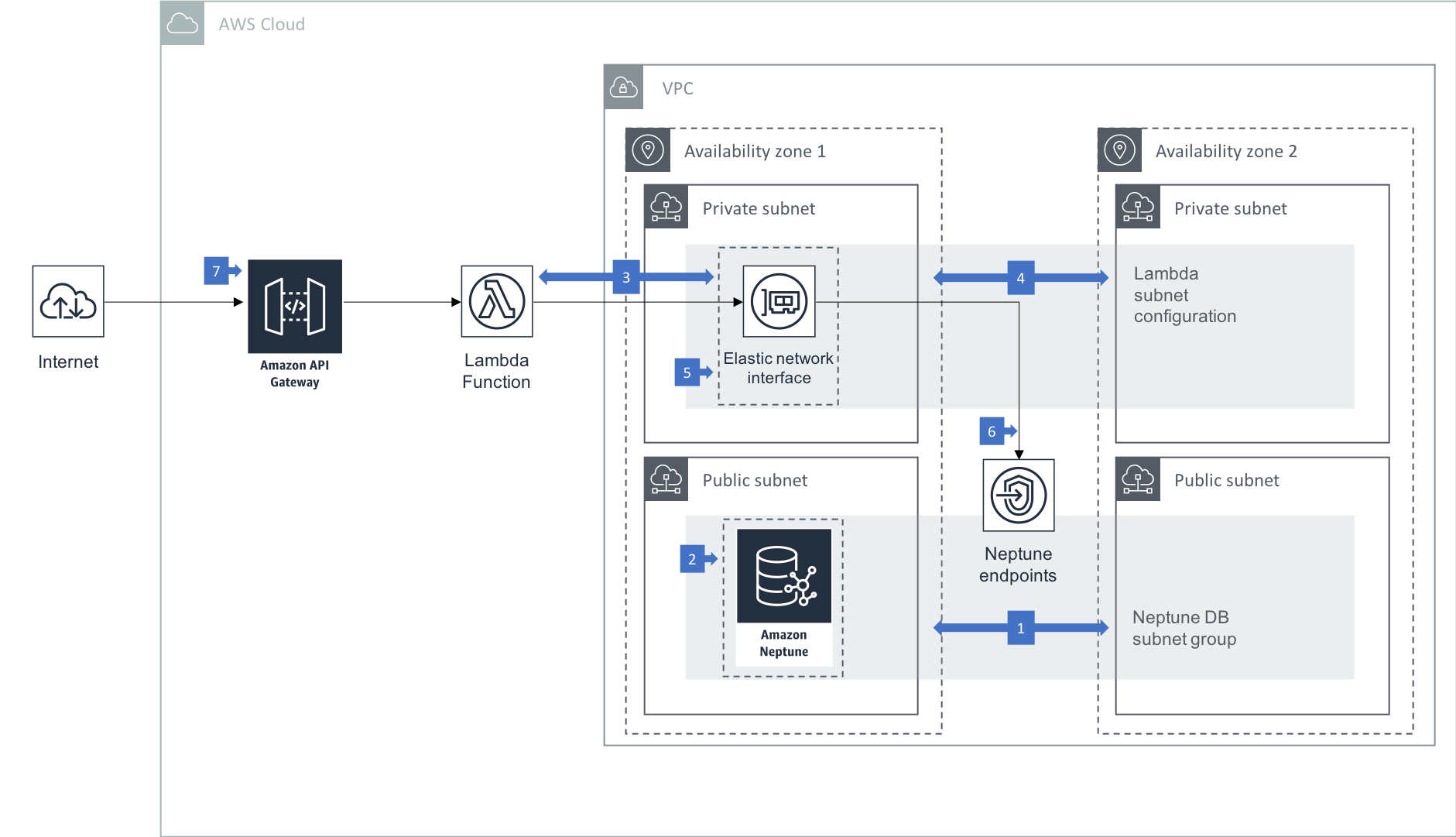
If you are building an application or service on Amazon Neptune, you may choose to expose an API to your clients, rather than offer direct access to the database. AWS Lambda allows you to build and run application logic without provisioning or managing servers. Amazon API Gateway allows you to publish secure APIs that access code running on AWS Lambda.
This architecture shows you how to connect AWS Lambda functions to Amazon Neptune.
Walkthrough of the Architecture
- In this architecture your Neptune cluster is run in at least two subnets in two Availability Zones, with each subnet in a different Availability Zone. By distributing your cluster instances across at least two Availability Zones, you help ensure that there are instances available in your DB cluster in the unlikely event of an Availability Zone failure.
- Neptune’s VPC security group is configured to allow access from the AWS Lambda security group on the Neptune cluster’s port.
- AWS Lambda is configured to access resources in your VPC. Doing so allows Lambda to create elastic network interfaces (ENIs) that enable your function to connect securely to Neptune.
- The Lambda VPC configuration information includes at least 2 private subnets, allowing Lambda to run in high availability mode.
- The VPC security group that Lambda uses is permitted to access Neptune via an inbound rule on the Neptune VPC security group.
- Code running in your Lambda function uses a Gremlin or SPARQL client to submit queries to the Neptune cluster’s cluster, reader and/or instance endpoints.
- API Gateway exposes API operations that accept client requests and execute your backend Lambda functions.
Best Practices
- If you require external internet access for your function, configure your Lambda security group to allow outbound connections and route outbound internet traffic via a NAT gateway attached to your VPC.
- Lambda functions that are configured to run inside a VPC incurs an additional ENI start-up penalty. This means address resolution may be delayed when trying to connect to network resources. As an alternative to running inside a VPC, you can run your Lambda functions outside your VPC and connect to the Neptune endpoints via a load balancer. If you do this, you should consider enabling IAM database authentication on your Neptune cluster, and configuring the Lambda execution role with an IAM policy that grants access to the database.
- Use a single connection and graph traversal source for the entire lifetime of the Lambda execution context. If the Gremlin driver you’re using has a connection pool, configure it to use a single connection. Hold the connection in a member variable so that it can be resued across invocations. Concurrent client requests to the function will be handled by different function instances running in separate execution contexts – each with its own member variable connection.
- Handle connection issues and retry connections in your function code. While the goal is to maintain a single connection for the lifetime of an execution context, unexpected network events can cause this connection to be terminated abruptly. Connection failures will manifest as different errors depending on the driver you’re using. You should code your function to handle these connection issues and attempt a reconnection if necessary.
- If your Lambda function modifies data in Neptune, you should consider adopting a backoff-and-retry strategy to handle
ConcurrentModificationExceptionandReadOnlyViolationExceptionerrors.ConcurrentModificationExceptionerrors occur when multiple concurrent requests attempt to modify the same elements in the graph – see the documentation on Neptune transaction semantics for more details.ReadOnlyViolationExceptionerrors can occur if the client attempts to write to a database instance that is no longer the primary. - Deprecated December 2020
If your Lambda functions connect to Neptune using WebSockets, ensure they close their connections at the end of each invocation. Do not try to maintain a connection pool across invocations. While this adds some additional latency opening a connection per function invocation, it avoids your functions exceeding the Neptune WebSocket connection limit of 60,000 connections. If you use the Java Gremlin client to query Neptune, initialize aClusterobject in a static member variable, and then inside your handler method explicitly create aClientobject, which your code then closes at the end of the method. - Deprecated December 2020
Because a connection pool will last only for the duration of a single Lambda invocation, and will often service only one request, consider reducing the size of the connection pool. Alternatively, if you are using Gremlin, consider submitting requests to the Gremlin HTTP REST endpoint rather than the WebSockets endpoint, thereby avoiding the need to create and manage the lifetime of a connection pool. The downside of this approach is that you must write string-based queries, rather than take advantage of the strongly-typed Gremlin Language Variants (GLV) that allow you to write Gremlin directly in your programming language of choice.
Learn More
- Using AWS Lambda functions in Amazon Neptune contains examples of AWS Lambda fucntions written in Java, JavaScript and Python.
- Load balance graph queries using the Amazon Neptune Gremlin Client contains a section on ‘Using the Neptune Gremlin client in an AWS Lambda function’.
- Find recommendations for using Amazon Neptune and maximizing performance in Best Practices: Getting the Most Out of Neptune.
- Building Serverless Calorie tracker application with AWS AppSync and Amazon Neptune workshop.