Graph Data Modelling
When you build a graph database application you will have to design and implement an application graph data model, together with graph queries that address that model. The application graph data model should express the application domain; the queries should answer the questions you would have to pose to that domain in order to satisfy your application use cases.
You build the application graph data model from graph primitives – vertices, edges, labels and properties in the case of a property graph, subject-predicate-object triples for RDF. You name these primitives to express the semantics of the application domain. You structure them to facilitate the path traversals or graph patterns contained in your queries.
Think of your application graph model and your queries as being two sides of the same coin. The graph is the superset of paths or graph patterns expressed in your queries. In order to achieve this degree of alignment between model and queries, employ a ‘design for queryability’ approach, whereby you drive out the model and the queries on a use-case-by-use-case basis.
Overview of the Design Process
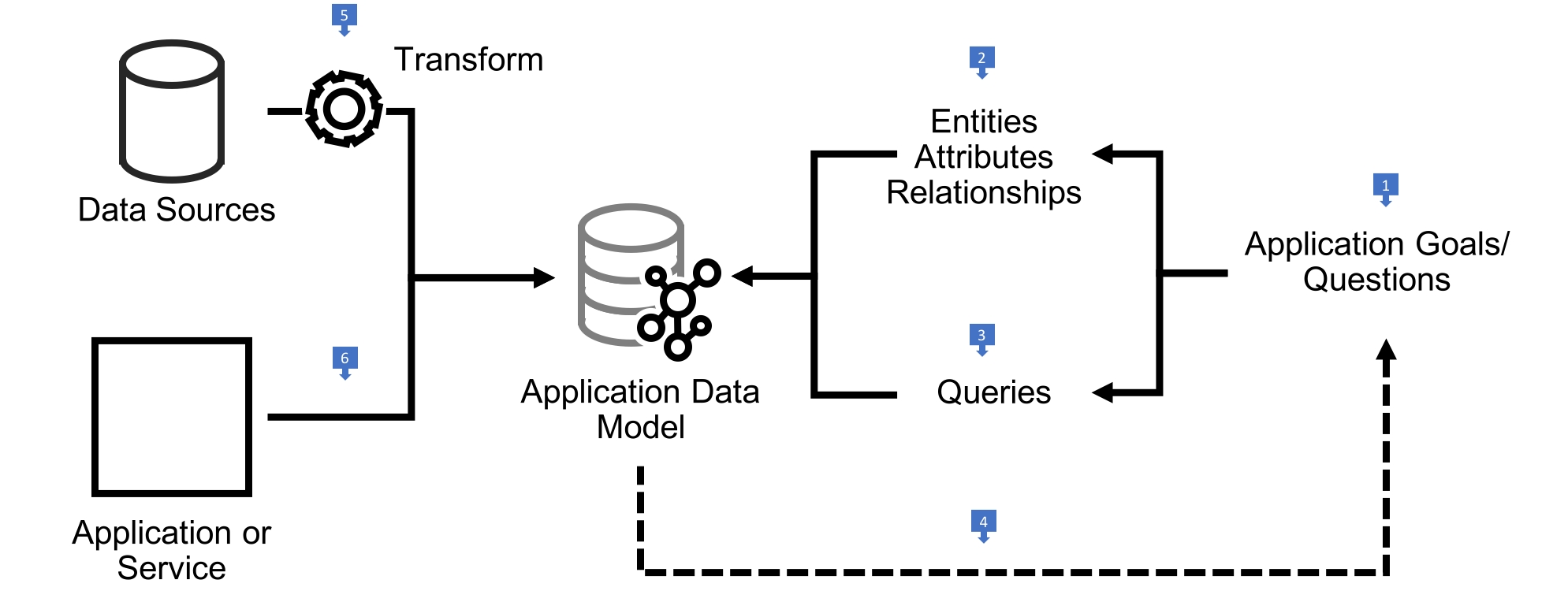
- Work backwards from your application or end-user goals. These goals are typically expressed as a backlog of feature requests, use cases or agile user stories. For each use case write down the questions you would have to put to the domain in order to facilitate the outcomes that motivate the use case. What would you need to know, find, or compute?
- Review these questions and identify candidate entities, attributes and relationships. These become the basis of your graph model, implemented using the primitives particular to either the property graph or RDF.
- Review these questions and your prototype application graph model to determine how you would answer each question by traversing paths through the graph or matching structural patterns in the graph. Adjust the model until you are satisfied it faciliatates querying in an efficient and expressive manner.
- Continue to iterate over your use cases, refining your candidate model and queries as you introduce new features.
- Once you have a candidate application graph data model you can treat this as a target for any necessary data migration and integration scenarios. Identify existing sources of data and implement extract, transform and load (ETL) processes that ingest data into the target model.
- If you are building an application or service on top of a graph database, design and implement write operations that insert, modify and if necessary delete data in the target application graph model.
Best Practices
- Develop your model and queries in a test-driven fashion. Create test fixtures that install a sample dataset in a known state, and write unit tests for your queries (or the parts of your application that encapsulate queries) that assert query results based on a fixed set of inputs.
- As you evolve your model and add new queries, rerun your tests to identify broken queries that need revising in line with the updated model.
Learn More
- For a worked example of deriving a property graph model from a set of use cases in a test-driven fashion, see the Property Graph Data Modelling sample
- For guidance on converting a relational, key-value or document data model to a property graph model, see Converting Other Data Models to a Graph Model
Property Graph Data Modelling
- Graph Data Modelling
- Property Graph Data Modelling
Learn More
- For a worked example of deriving a property graph model from a set of use cases, see the Property Graph Data Modelling sample
- For guidance on converting a relational, key-value or document data model to a property graph model, see Converting Other Data Models to a Graph Model
Building an Application Graph Data Model
An application-specific property graph data model describes how your graph data is structured both to express your domain and to make it easy and efficient to query for your most important use cases:
- What types of vertices do you have in your graph, as represented by vertex labels?
- What properties are attached to each type of vertex?
- How are different vertices connected?
- What edge labels do you use to represent different types of edges?
- What properties are attached to these edges?
By answering these questions you describe an application property graph data model that is specialized for your specific application or set of uses cases.
In the relational world we’d express an application-specific relational model using schema and constraints. In the property graph world, however, there are very few commonly-adopted formal constructs for doing the same. Some graph databases advertise themselves as being schema-free, others allow for optional schema or constraints to be layered on top of the data, while a few require an upfront schema to be defined using a product-specific schema language.
Neptune is a schema-free graph database. No two vertices, even those with the same labels, need share the exact same set of properties. No two values of a particular property need use the same datatype. No two pairs of vertices need be connected in the exact same way. The only constraints that Neptune asserts are:
- Every edge must have a start vertex and an end vertex. These can be the same vertex: that is, Neptune allows self edges.
- All vertex IDs must be unique, and all edge IDs must be unique. However, Neptune does allow a vertex and an edge to have the same ID.
You can use traditional data and application modelling techniques, including entity relationship diagrams (ERD) and the Unified Modelling Language (UML) to model your graph, but many graph application designs begin by illustrating a small, representative example of the graph, with specific vertices, labels, properties and edges showing how instances of things in the application domain are attributed and connected to one another. These specifications by example can then be easily turned into representative datasets against which you can develop and test your queries.
Vertices
Use vertices to represent instances of a thing (an entity, concept, event, etc). You can think of a vertex as being equivalent to a row in a relational table.
Vertex IDs
Some graph databases automatically assign IDs to vertices when they are created, others allow you to supply your own. If the database allows it, consider supplying your own IDs when creating vertices. These could be a stable domain attribute that uniquely identifies an entity – an employee number, for example, or a product SKU – or an ID derived from an original source for the data, such as a primary key in a relational table.
Neptune allows you to supply your own IDs when you create a vertex. If you don’t supply an ID, Neptune will create a string-based UUID for you.
Vertex labels
Use a vertex label to indicate the entity type or the role that the vertex plays in your dataset. People, users, customers, products, jobs, policies – in the singular, person, user, customer, product, job and policy: all good candidate vertex labels.
Try to limit each vertex to having just one label. Entities can sometimes play multiple roles in your dataset: if that’s the case, it’s fine to attach multiple labels to a vertex. But avoid using labels as flags or enumerated tags that group entities of a particular type. Better to use a property to perform this partitioning. For example, if you wanted to version vertices in your graph, it would be best to do this by attaching a version property containing a numeric property value to each vertex, rather than labelling each vertex v1, v2, v3, etc.
Vertex properties
Use vertex properties to represent the attributes of an entity: first name, last name, invoice number, height, width, colour, ISBN, price, etc. One of the modelling benefits of the property graph is that it allows you to ‘chunk up’ entity attributes into a discrete, easily understood record-like structure: that is, to represent a ‘thing’ as a labelled vertex with multiple properties.
As well as using vertex properties to model entity attributes, you can also use them to store vertex metadata such as a version number, last updated timestamp, or access control list.
Gremlin supports single, set and list cardinality for vertex properties. Neptune, however, supports only single and set cardinality, not list, with set cardinality the default. Set cardinality allows you to model multi-value vertex properties containing unique values: an
emailAddressproperty, for example, could contain a set such as[john.smith@example.com,j.smith@example.org,johnsmith@example.net].If you need to model a list with Neptune – either to maintain list order or to store duplicate values – you have a couple of choices:
- If there’s no requirement to filter the list’s contents at query time, you can store the list as a delimited string representation. To modify the contents of the list, you’ll need to implement some logic in your application to retrieve the current representation of the list, parse it into a list type to which you can apply any necessary modifications, and then update the property with a string representation of the new list value.
- If you need to filter on the list’s contents during a traversal, you’ll have to pull the list values out as properties on separate vertices. You can connect these list value vertices either directly to the ‘parent’ vertex, or to a ‘list’ vertex that is attached to the parent. You can then use additional properties, either on the edges or on the value vertices themselves, to store metadata, such as item order. While this solution allows for filters or predicates to be applied to list values during a traversal, it introduces more complexity into both the data model and the queries that apply these filters. It may also increase both query latencies and storage costs (every value has the storage overhead of its being a vertex).
When should I model an attribute as a property versus a label?
Use a label to type a vertex or to describe the role a vertex plays in your dataset. Use properties to capture the instance-based attributes of a thing in your domain. Labels help answer the question: What does this vertex represent? Properties help answer the question: What are the attributes of this particular thing?
When should I model an attribute as a property and when should I pull it out into its own vertex?
Model an attribute as its own vertex when:
- the attribute value is a complex value type and/or
- the attribute value is part of a value structure, such as a hierarchy and/or
- the attribute value will be used to relate entities at query time.
Complex value types
Complex value types – attribute values that contain more than one field – are best represented as their own vertices. Address is a good example: model address as a separate vertex with line1, line2, city, and zipcode properties.
With some applications, you may want to attach metadata such as a timestamp or access control list to a specific attribute (rather than the vertex representing the entity to which the attribute belongs). If your graph database and its data model and query language support metaproperties then you can take advantage of these features to implement your use case.
Neptune doesn’t support metaproperties. To attach attribute-specific metadata, you will have to model the attribute as its own vertex, and add additional properties to this vertex (and/or to the edge connecting this attribute vertex to the entity with which it is associated) to represent your metadata.
Value structures
Some value types are part of a set that has its own internal structure. As an example, take the classification hierarchy in an online product catalogue. Treasure Island might be classified as both ‘Classic Children’s Literature’ and as ‘Action and Adventure’, both of which are subcategories of ‘Fiction’ in the ‘Books’ part of the catalogue. Such hierarchical or multi-hierarchical structures are best represented using the subgraph structures enabled by pulling each classification value out into its own vertex.
Relating entities through their attributes at query time
If an attribute value will be used to create paths through the network that relate entities at query time, consider pulling it out into its own vertex.
Social security number is a good example. Normally, we’d model social security number by attaching a socialSecurityNumber property to a User vertex. But in a fraud detection graph, where individuals in a fraud ring share bits of identity information, things are more complicated. Here we might have a connected data query of the form:
Given individual X, can we find other people in the graph who have opened accounts using the same social security number as person X?
In other words, we have a starting point, person X, but need thereafter to find other people who have something in common with person X based on a specific attribute – the social security number used by person X.
Note that this connected data query is very different from the kind of query that asks:
Find everyone who has used social security number ‘123-45-6789’.
This latter query could be satisfied simply by filtering User vertices based on a socialSecurityNumber value that is known to us at the time the query is formulated. It’s the equivalent of a simple key-value lookup. In the connected data query, in contrast, we don’t necessarily know the social security number at query time. What we do know is how to identify person X. Having found person X, the connected data query then needs to find other people who are connected to X by way of some shared attribute – the social security number.
If you are considering modelling an attribute as its own vertex in order to facilitate connected data queries, apply good judgement based on your understanding of the domain. The new vertex should probably represent a significant concept in the domain. In the fraud detection example, bits of identity information are meaningful domain entities that can exist independent of the users with which they are associated. In other domains, the same might not be true of these same attributes.
Edges
Use edges to represent the relationships between things in your domain.
The performance of a graph query depends on how much of the graph the query has to ‘touch’ in order to generate a set of results. The larger the working set, the longer it will take to get from storage and then traverse once it has been cached in main memory.

You can ensure your queries touch the minimum amount of data by naming edges in a way that allows the query engine to follow only those relationships relevant to the query being executed.

Edges compose and partition the graph. By connecting vertices, they structure the whole, creating a complex composite from what would otherwise be simple islands of data. At the same time they serve to partition the graph, differentiating connections between elements based on name, direction and property values so that queries can identity specific subgraphs within a larger, more variably connected structure. By focussing your queries on certain edge labels and directions, and the paths they form, you allow the query engine to exclude irrelevant parts of the graph from consideration, effectively materializing a particular view of the graph dedicated to addressing a specific query need.
Edge IDs
Every edge has an ID. Some graph databases automatically assign IDs to edges when they are created, others allow you to supply your own. Because every edge has its own identity, the property graph allows you to create multiple edges with the same labels (and properties) between any given pair of vertices.
Neptune allows you to supply your own IDs when you create an edge. If you don’t supply an ID, Neptune will create a string-based UUID for you.
Edge labels
Derive your edge labels from your use cases. Doing so helps structure and partition your data so that queries ignore vertices and edges that have no bearing on the working set necessary to satisfy the query.

If your queries need only find relationships with a particular name drawn from a family of names (for example, of all the addresses in the dataset, one query needs only find work addresses, another only home addresses), then consider using fine-grained edge labels or predicates.
If some or all of your queries need to find all relationships belonging to a particular family (for example, all addresses, irrespective of whether they are work or home addresses), use a more general name qualified with an edge property. The tradeoff here is that queries that require only specific relationship types (for example, work addresses) will touch more of the graph and will have to filter based on the edge property, but the design provides for both finding all edges with a particular name, and finding specific types of edges belonging to that family.
Bi-directional relationships
If you need to model bi-directional relationships, in which relationship direction is of no consequence to the model, you can use a single, directed relationship, but ignore its direction in your Gremlin queries using the both() or bothE() steps.
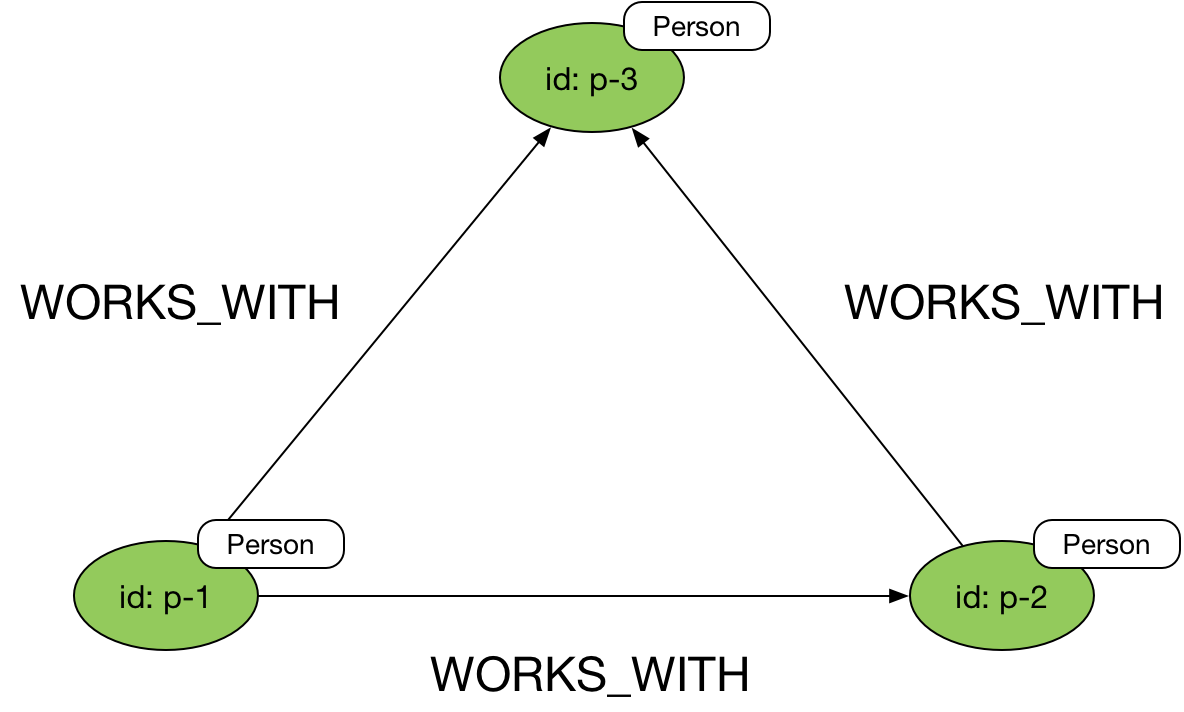
Here’s an example query that ignores edge direction:
g.V('p-1').both('WORKS_WITH')
Uni-directional relationships
Edges in a property graph are always directed: ideal for expressing uni-directional relationships.
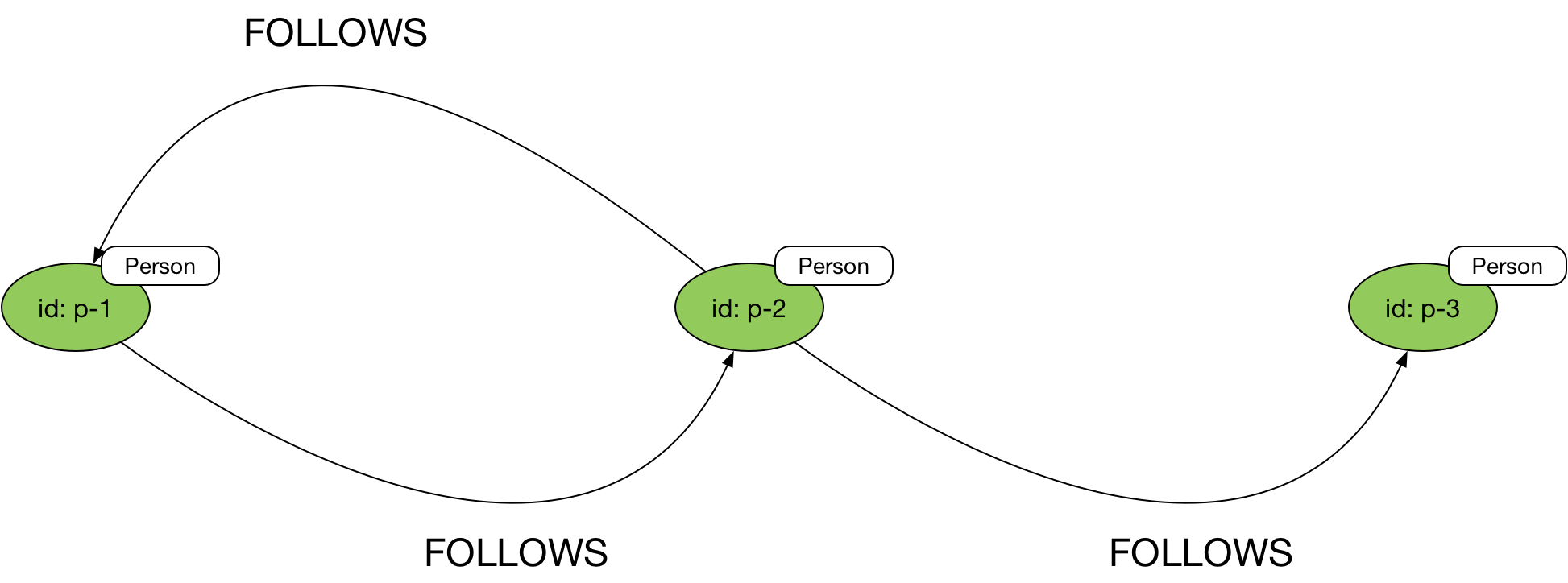
In Gremlin you then explicitly state the direction you wish to follow in your queries using the in(), out(), inE() and outE() steps:
g.V('p-1').in('FOLLOWS')
or
g.V('p-1').out('FOLLOWS')
Favour outgoing edges
Neptune is optimized for traversing outgoing edges. Therefore, if possible, design your model so that your performance-critical queries follow mostly outgoing edges.
If a query has to traverse an incoming edge, always specify the edge label as part of the query, even if there is only one type of edge label that the traversal could possibly follow. For example, for a vertex that has only
CREATEDincoming edges, we would recommend usingin('CREATED')andinE('CREATED')rather thanin()andinE()to traverse those edges.
Multiple relationships between vertices
You can connect any pair of vertices with multiple edges. These edges can all have the same name, or they can have different names. Each edge represents an instance of a connection between the start and end vertices. In many cases, such edges will be attributed with one or more distinguishing properties, such as timestamps.

Edge properties
Use edge properties to represent the strength, weight or quality of a relationship. Using edge properties, you can further filter which edges a traversal follows – following only KNOWS edges in a social graph whose strength property is greater than 5, for example – or compute a cumulative result along a path – calculating the shortest, or cheapest, or quickest route through a logistics network, for example.
You can also use edge properties to store metadata such as a version number, last updated timestamp, or access control list.
A note on predicates
In RDF terms, both edge labels and edge and vertex property names are considered predicates. Neptune is optimized for datasets containing a relatively small number of unique predicates – in the order of several thousand at most. A dataset containing 100,000
Uservertices, each with 5 properties, and 1 millionFOLLOWSedges has 6 unique predicates (5 vertex properties and 1 edge label).Keep the number of predicates in your data model relatively small. Databases with many tens of thousands or even millions of unique predicates can experience a drop in performance.
The Hub-and-Spoke Pattern
One of the most common patterns in property graph data modelling is the hub-and-spoke structure, comprising a central vertex connected to several neighbouring vertices. This central vertex often represents a fact or event, the neighbouring vertices contextual information that helps explain or enrich our understanding of this hub vertex. An example would be a Purchase hub vertex, representing a purchasing event, connected to the User who made the purchase, the several Product items in the user’s shopping basket, and the Shop where the items were bought.
The hub-and-spoke subgraph structure is similar to the star schema or facts and dimensions model employed in data warehousing. Each hub node represents an instance of a fact or event (or other entity). A hub vertex is connected to one or more spoke or dimension vertices. These dimension vertices in turn are often connected to multiple other fact vertices: a User makes many purchases; a Product appears in multiple shopping baskets. The subgraph structure may occur thousands or millions of times in a dataset, with the dimension vertices acting as contextual intermediaries through which facts or events can be related.
Sometimes this pattern will emerge as a straightforward representation of your domain. At other times, you may find yourself moving to this pattern to accomodate several different use cases and the queries associated with them, or to provide for the longterm evolvability of your model. Your overall goal is to design an application graph data model that is expressive of your domain, easy to query on behalf of your most important use cases, and easy to evolve as you discover new use cases and introduce new features into your application. If your data model is too simple, it can become difficult to add new use cases and queries. If it is too complex, it can become difficult to maintain, and may impose a performance penalty of some of your more important queries. Aim to be as simple as you can given the needs of your application, and no simpler.
Hub-and-spoke example
Consider how we might represent a person’s employment details in an application graph data model. If all we need to know, given our current and anticipated new use cases, is the company where a person worked, the following will suffice:

We can even add properties to the WORKED_AT edge to describe Alice’s role, and the period during which she worked for Example Corp (e.g. from and to properties, with data values):

But if our application use cases require us to ask deeper questions of Alice’s employment history – In which office was she located? How did her role relate to other roles in the company? – then we’ll need to adopt a more complex model based on the hub-and-spoke pattern:
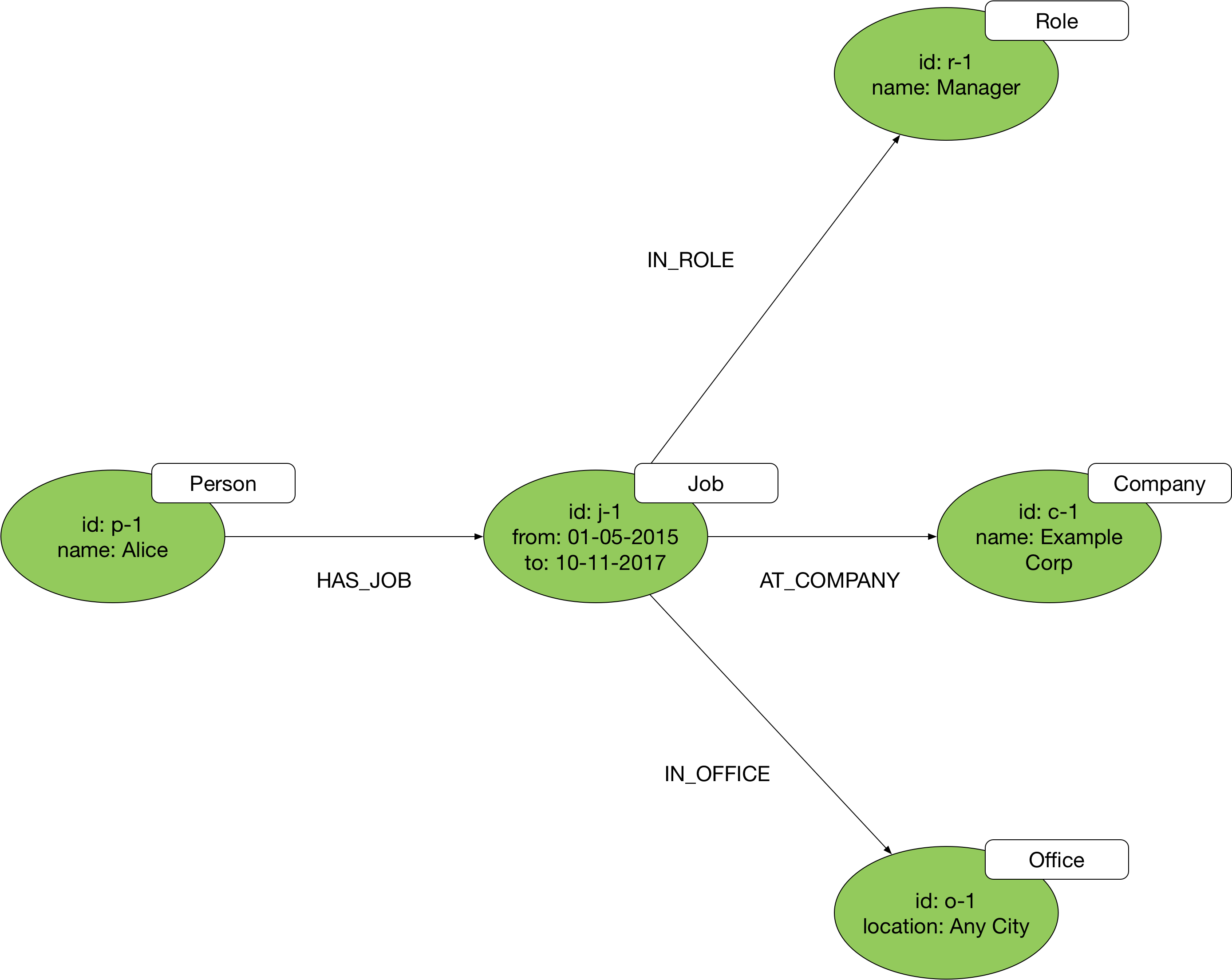
Here we’ve taken the action encoded in the WORKED_AT edge (‘working’ or ‘worked’, a verb) and turned it into a vertex labelled Job (a noun) that acts as a hub connected by way of HAS_JOB and AT_COMPANY edges to the vertices representing Alice and Example Corp. You’ll find that most edges can be decomposed in this way into a more complex vertex-and-two-edges structure. The trick is in identifying when this is necessary.
The advantage of this model is that it allows for the longterm evolvability of your application. You can always add new types of dimension nodes as you learn more about your domain and introduce new features. If a new use case emerges that requires us to capture details of the department to which Alice belonged (an organisational hierarchy worthy of its own subgraph structure), for example, we can easily add a new Department vertex to the model:
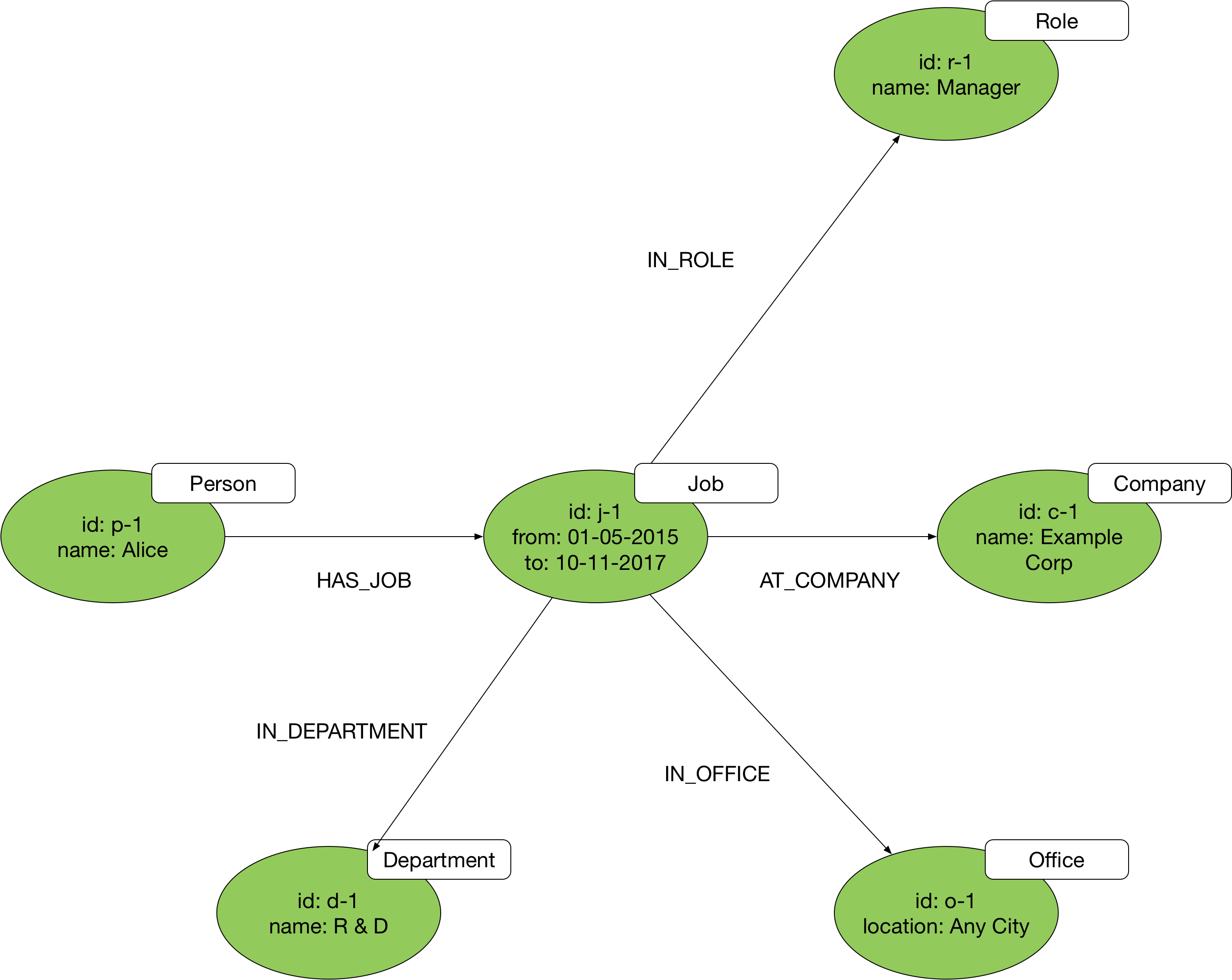
When to use hub-and-spoke
It’s tempting to apply this pattern everywhere, transforming every edge in your ‘naive’ model into a vertex-and-two-edges structure. But if you don’t need the richness and flexibility of this subgraph structure, don’t use it: you’ll end up increasing storage overheads and query latencies (more data to store, fetch and traverse) for no appreciable benefit.
Conversely, you may be struggling with an overly simplistic model derived from your first natural language description of your domain. Problems often present themselves when you find yourself wanting to add an edge to an edge – to annotate one relationship with another. This can sometimes be the result of verbing – the language habit whereby a noun is transformed into a verb. For example, instead of saying X SENT an Email TO Y, we might verb the noun, and say X EMAILED Y. If this is the basis of our model, problems emerge when we want to indicate who was CCd on the mail, or describe one email as being a reply to another. By pulling out the domain entity inherent in the verb – Email from EMAILED – we can introduce a hub node that allows for far more expressive structuring of entities and relationships.
If you’re struggling to come up with a graph structure that captures the complex interdependencies between several things in your domain, look for the nouns, and hence the domain concepts, hidden inside of some of the verb phrases you’ve used to describe the structuring of your domain.
While some hub vertices lie hidden in verbs, other hub-and-spoke structures can be found in adverbial phrases – those additional parts of a sentence that describe how, when or where an action was performed. Adverbial phrases result in what entity-relational modelling calls n-ary relationships; that is, complex, multi-dimensional relationships that bind together several things and concepts. The hub-and-spoke pattern is ideal for these kinds of n-ary relationships. While it may sometimes feel as though you’re encumbering your model with another vertex just to accomodate the need for multiple relationships, you can invariably find a good, domain-meaningful term for this hub vertex that helps make the model more expressive.
RDF Data Modelling
- The Graph Development Lifecycle
- Graph Development Lifecycle Tutorial
- Using Edges to Facilitate Efficient Graph Queries
- Predicate names
- Bi-directional relationships
- Uni-directional relationships
- Multiple relationships between nodes
The Graph Development Lifecycle
Introduction
Designing, building and testing RDF graph models is an iterative process, which we refer to here as The Graph Development Lifecycle. The Graph Development Lifecycle starts by describing the features you want your graph to address in natural language, followed by a visual design, encoding the model as RDF using OWL (Web Ontology Language), and then testing your ability do answer the features with some sample data and SPARQL queries.
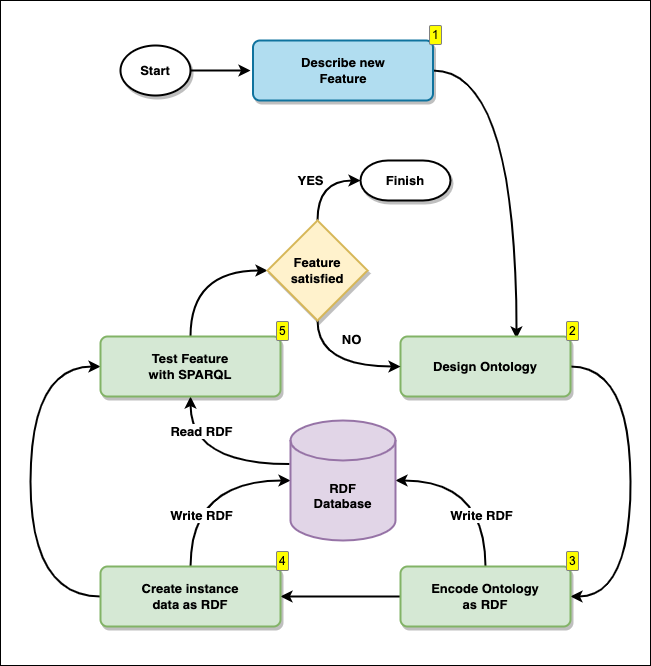
Here we describe each step in the process, and below we give a full example of iterating over the Graph Development Lifecycle multiple times.
Step 1: Describing new features
Here we describe the features we want our graph to address, in plain natural language.
Feature example: “In my social graph, I want to list all the people, by name, that are not my direct friends, but that are friends with my friends”
Step 2: Designing the Ontology
The term “Ontology”, originally used in the study of Metaphysiscs, is the philosophical study of being. It investigates what types of entities exist, how they are grouped into categories, and how they are related to one another on the most fundamental level. When we design a schema or logical model for RDF, we call it an “Ontology”.
Visit Wikipedia to further understand the differences between the philosophical definition of an Ontology and the Information Science definition of an Ontology.
Using the features described in natural language from Step 1, we draw the Ontology described by the features. We take all the concepts and relationships described as natural language and display them in an easy to digest diagram. Any diagramming tool is usually suitable, a whiteboard is ideal.
Step 3: Encoding the Ontology as RDF-OWL
Once you have designed an Ontology in step 2, we record the model as data, in the graph. The Ontology we use to record the schema definition is called OWL (Web Ontology Language), it is encoded in RDF.
This activity does not enforce a schema, but describe the Ontological model as data, and gives you the ability to query the Ontology along side the actual data. Although it may look daunting at first, there are various tools available to help you with this process, and it is easy thing to do manually with practice. We show a full example below.
N.B. Designing and encoding an Ontology is not a requirement for an RDF database (like Amazon Neptune) to work. Some pactitioners do not design OR encode their Ontologies at all. It is, however, highly recommended, for the following reasons:
- The ability to query the logical model, schema and entity definitions just like any other data.
- Compatibility with tooling that understands the OWL standard
- When creating Software componenets that use the graph, they can be engineered to understand the model, to, for example, dynamically create React componenets for specific types.
Step 4: Create instance data as RDF
Now that you have an Ontology defined, you can create or source some data to fit the Ontology, as you need some sample data to test whether your Feature can be satisfied. We call this the Instance data. The data is recored in RDF, and stored in the database alongside the OWL data.
The distinction between Instance RDF data and Ontological RDF/OWL data is sometimes referred to as Description Logic. Where the instance data belongs in the ABox(assertional box), and the Ontology (OWL) data belonging in the TBox (terminological data). ||| |-|-| | Tbox (Ontology) | Every employee is a person | | ABox (Instance data) | Bob is an employee |
Step 5: Test features with SPARQL
Now you have some RDF instance data and your OWL Ontology, you can test whether or not you can satisfy your feature requirements by running SPARQL queries.
Once you have completed the cycle, if you can satisfy your feature request, you can consider this journey around the cycle complete. If you cannot satisfy the feature, you can start the cycle again from step 1/2, with the new knowledge you have learnt, and try again with a new model to satisfy your features requirements.
We show a full example around the lifecycle below.
Graph Development Lifecycle Tutorial
Designing RDF Graph models (Ontologies)
When designing a model for an RDF graph (or Ontology), first we describe in natural language the features that we want from our Ontology, then we design and document it, by drawing the concepts which your model describes, their properties, and the relationships between them; this process is called designing an Ontology.
You can design an Ontology simply by drawing it somewhere/anywhere. Ontologies can be drawn on paper, on a white board, or on any graphical design environment where you can draw concepts, relationships between concepts and properties of those concepts. There are third party tools that are dedicated to the design of Ontologies, but we will not describe them here, as they are not needed for this guide.
Once designed, the Ontology can be stored as RDF in a graph database, and so can be queried like any other data. Experienced Ontologists may often write Ontology RDF data (known as OWL), either by hand or using third party tooling, sometimes skipping some steps described here, but in this guide we describe a more complete and well documented process, as described in the diagram above.
Now we demonstrate iterating around the Graph Development Lifecycle 3 times, for three new features.
Iteration 1: adding the first feature to the solution
1. Describe new features
We descibe what we want to find out from the graph, in natural language.
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
2. Design the Ontology
We draw concepts/objects such as ‘Department’ and ‘Employee’ in a different style to data properties such a string for a name, in order to differentiate between literal values of core data types and domain specific concepts.
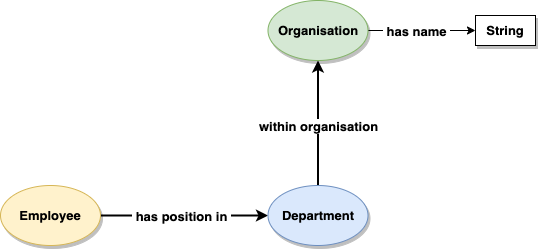
3. Encode the ontology as RDF (OWL)
Here is a complete example of the Ontology RDF (OWL) to match the diagram from step 2. The RDF shown here is in the format of Turtle, to load this data into Neptune, see the documentation on Loading data into Amazon Neptune.
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix awso: <http://aws.amazon.com/ontology/> .
awso:withinOrganisation rdf:type owl:ObjectProperty ;
rdfs:domain awso:Department ;
rdfs:range awso:Organisation ;
rdfs:label "within organisation" .
awso:hasPositionIn rdf:type owl:ObjectProperty ;
rdfs:domain awso:Employee ;
rdfs:range awso:Department ;
rdfs:label "has a position within" .
awso:hasName rdf:type owl:DatatypeProperty ;
rdfs:domain awso:Organisation ;
rdfs:range xsd:string .
awso:Department rdf:type owl:Class ;
rdfs:label "Department" .
awso:Employee rdf:type owl:Class ;
rdfs:label "Employee" .
awso:Organisation rdf:type owl:Class ;
rdfs:label "Organisation" .
4. Create instance data as RDF
Create sample data, to be loaded into Neptune, which fits to the Ontology. We create RDF in the Turtle format that describes:
- 6 Employees
- 3 Departments
- 2 Organisations
- 6 statements showing which departments the employees work in
- 3 statements showing which organisations the departments are in
@prefix awso: <http://aws.amazon.com/ontology/> .
@prefix awsr: <http://aws.amazon.com/resource#> .
awsr:Employee2 a awso:Employee .
awsr:Employee1 a awso:Employee .
awsr:Employee3 a awso:Employee .
awsr:Employee4 a awso:Employee .
awsr:Employee5 a awso:Employee .
awsr:Employee6 a awso:Employee .
awsr:Employee7 a awso:Employee .
awsr:Department1 a awso:Department .
awsr:Department2 a awso:Department .
awsr:Department3 a awso:Department .
awsr:Department4 a awso:Department .
awsr:Org1 a awso:Organisation ;
awso:hasName "ACME Corp" .
awsr:Org2 a awso:Organisation ;
awso:hasName "NORMCO LTD" .
awsr:Employee1 awso:hasPositionIn awsr:Department1 .
awsr:Employee2 awso:hasPositionIn awsr:Department1 .
awsr:Employee3 awso:hasPositionIn awsr:Department2 .
awsr:Employee4 awso:hasPositionIn awsr:Department2 .
awsr:Employee5 awso:hasPositionIn awsr:Department3 .
awsr:Employee6 awso:hasPositionIn awsr:Department3 .
awsr:Employee7 awso:hasPositionIn awsr:Department4 .
awsr:Department1 awso:withinOrganisation awsr:Org1 .
awsr:Department2 awso:withinOrganisation awsr:Org1 .
awsr:Department3 awso:withinOrganisation awsr:Org2 .
awsr:Department4 awso:withinOrganisation awsr:Org2 .
5. Test features with SPARQL
Write a SPARQL query which tests that our Feature meets the requirements.
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
prefix awso: <http://aws.amazon.com/ontology/>
prefix awsr: <http://aws.amazon.com/resource#>
SELECT * WHERE {
?employee a awso:Employee .
?employee awso:hasPositionIn ?department .
?department awso:withinOrganisation awsr:Org1 .
}
The response to the query proves that our feature is satisfied, showing in a table a list of employees and the departments they work for, filtered by only one of the organisations.
| Employee | Department |
|---|---|
| http://aws.amazon.com/resource#Employee1 | http://aws.amazon.com/resource#Department1 |
| http://aws.amazon.com/resource#Employee2 | http://aws.amazon.com/resource#Department1 |
| http://aws.amazon.com/resource#Employee3 | http://aws.amazon.com/resource#Department2 |
| http://aws.amazon.com/resource#Employee4 | http://aws.amazon.com/resource#Department2 |
Iteration 2: adding a second feature
1. Describe new Features
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
| 2 | and I want to list all the names of the employees in the organisation ACME CORP |
2. Design the Ontology
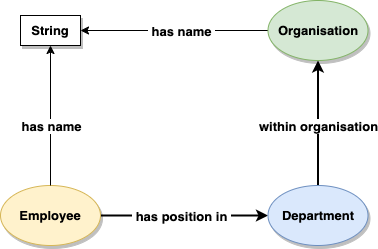
We can now update our diagram to fulfil the requirement of the new feature, by adding the ‘has name’ property to the Employee. We re-use the same property “has name” that we first used for ‘Organisation’. This is because they are conceptually the same. In other words, the following statement is true: “both Employees and Organisations have a name.” Because it is the same property conceptually and in reality, you can choose to visualise this in multiple ways. How you draw the diagram of the Ontology is up to you, here are 3 different approaches:
Ontology design option 1: Replicate an element
Replicating the element ‘has name’ on the diagram gives a lot of flexibility when drawing the model, as you can position the elements anywhere near their respective domain. It does however mean that you have more elements on your diagram, so can use up more of the canvas available to you.
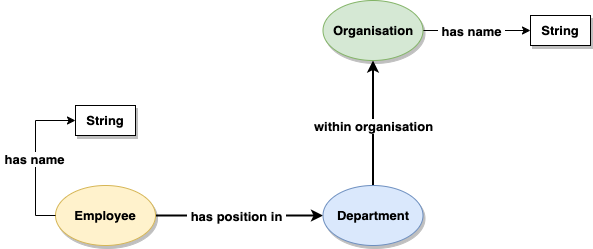
Ontology design option 2: Re-using elements
Pointing the relationship ‘has name’ to the same element means you use less of the canvas, but it may be more difficult to lay out and visualisae later on, especially if lots of entities have a name.
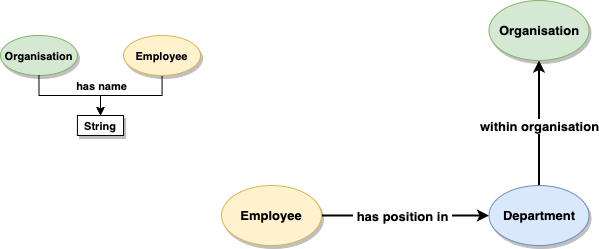
Ontology design option 3: Multiple diagrams and replicating elements
Splitting the diagram into two, and duplicating the elements Employee and Organisation, means you can manage your canvases seperately, and allow for much more expansion later on, for example if every class ‘has a name’, the diagram will still be very easy to understand. However, this does mean maintaining multiple diagrams.
3. Encode the ontology as RDF (OWL)
We add the new entities to our OWL file in RDF Turtle format:
(We predict that we will also want names for Departments, so we can load that too.)
You can write the same RDF to Neptune as many times as you want, you will never get duplicate statements. Understand an RDF graph as a SET of statemets.
We add the following RDF/OWL into Neptune, which overwrites the previous definition of the ‘has name’ datatype property.
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix awso: <http://aws.amazon.com/ontology/> .
awso:hasName rdf:type owl:DatatypeProperty ;
rdfs:domain awso:Organisation ,
awso:Employee ,
awso:Department ;
rdfs:range xsd:string ;
rdfs:label "has name" .
4. Create instance data as RDF
We already have ‘has name’ sample data for the Organisations, so we just add the missing sample RDF instance data: the ‘has name’ datatype properties for Employees and Departments.
@prefix awso: <http://aws.amazon.com/ontology/> .
@prefix awsr: <http://aws.amazon.com/resource#> .
awsr:Employee1 awso:hasName "John Smith".
awsr:Employee2 awso:hasName "Jane Doe".
awsr:Employee3 awso:hasName "Mike Jones".
awsr:Employee4 awso:hasName "Callum McAllister".
awsr:Employee5 awso:hasName "Allison Hunter".
awsr:Employee6 awso:hasName "Sanjay Singh".
awsr:Employee7 awso:hasName "Lars Anderson".
awsr:Department1 awso:hasName "Sales & Marketing".
awsr:Department2 awso:hasName "I.T.".
awsr:Department3 awso:hasName "Human Resources".
awsr:Department4 awso:hasName "Information Technology".
5. Test features with SPARQL
We write a new SPARQL query to satisfy both features
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
| 2 | and I want to list all the names of the employees in the organisation ACME CORP |
prefix awso: <http://aws.amazon.com/ontology/>
prefix awsr: <http://aws.amazon.com/resource#>
SELECT ?employeeName ?departmentName ?orgName WHERE {
?employee a awso:Employee ;
awso:hasName ?employeeName ;
awso:hasPositionIn ?department .
?department awso:withinOrganisation awsr:Org1 ;
awso:hasName ?departmentName .
awsr:Org1 awso:hasName ?orgName .
}
The response to the query proves that both features are satisfied, showing in a table with a list of employees names and the departments they work for, filtered by only one of the organisations. Now that we have names for everything, we can use them.
| employeeName | departmentName | orgName |
|---|---|---|
| John Smith | Sales & Marketing | ACME Corp |
| Jane Doe | Sales & Marketing | ACME Corp |
| Mike Jones | I.T. | ACME Corp |
| Callum McAllister | I.T. | ACME Corp |
Iteration 3: adding a breaking change
1. Descibe new Features
We describe a third feature.
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
| 2 | and I want to list all the names of the employees in the organisation ACME CORP |
| 3 | and I want to list all the workers that work in IT departments across all organisations |
2. Design the Ontology
This new third feature presents us with a problem. We cannot write a SPARQL query will collect together all the people that work in any IT department regardless of Organisation. You can see this within our existing Ontology diagram. In the existing Ontology, we have different IT departments for different organisations. We do not have a way of recognising that they are both IT departments, but in different Organisations:
...
awsr:Department2 a awso:Department ;
awso:hasName "I.T.".
awsr:Department4 a awso:Department ;
awso:hasName "Information Technology".
...
awsr:Department2 awso:withinOrganisation awsr:Org1 .
awsr:Department4 awso:withinOrganisation awsr:Org2 .
...
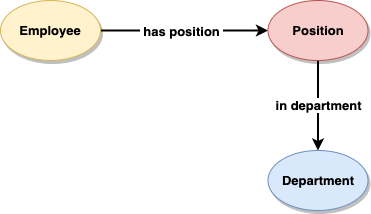
Reification
We need to expand the model to recognise that the departments are both the same kind of departments, but in different organisations. To do this, we need to expand the relationship ‘has position in’. This process is called Reification.
We start with the relationship …

… and reify(expand) it, so that we can recognise when Employees work for the same Department, but in different Positions for different organisations.
Our new complete Ontology looks like this:
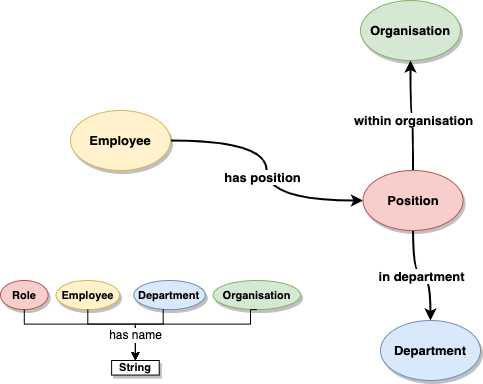
3. Encode the ontology as RDF (OWL)
Lots of our Ontology has changed after reification, so first we delete everything from before in a simple SPARQL clear-all query:
CLEAR ALL
…and we create a new complete RDF/OWL file and load it:
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix awso: <http://aws.amazon.com/ontology/> .
awso:hasPosition rdf:type owl:ObjectProperty ;
rdfs:domain awso:Employee ;
rdfs:range awso:Position ;
rdfs:label "has position" .
awso:withinOrganisation rdf:type owl:ObjectProperty ;
rdfs:domain awso:Department ;
rdfs:range awso:Organisation ;
rdfs:label "within organisation" .
awso:inDepartment rdf:type owl:ObjectProperty ;
rdfs:domain awso:Position ;
rdfs:range awso:Department ;
rdfs:label "for department" .
awso:hasName rdf:type owl:DatatypeProperty ;
rdfs:domain awso:Organisation ,
awso:Department ,
awso:Employee ,
awso:Position ;
rdfs:range xsd:string ;
rdfs:label "has name" .
awso:Department rdf:type owl:Class ;
rdfs:label "Department" .
awso:Employee rdf:type owl:Class ;
rdfs:label "Employee" .
awso:Organisation rdf:type owl:Class ;
rdfs:label "Organisation" .
awso:Position rdf:type owl:Class ;
rdfs:label "Position" .
4. Create instance data as RDF
As we have started wit a new Ontology in step 3, and deleted everything, we load a full new sample RDF dataset.
@prefix awso: <http://aws.amazon.com/ontology/> .
@prefix awsr: <http://aws.amazon.com/resource#> .
awsr:Employee1 a awso:Employee ;
awso:hasName "John Smith".
awsr:Employee2 a awso:Employee ;
awso:hasName "Jane Doe".
awsr:Employee3 a awso:Employee ;
awso:hasName "Mike Jones".
awsr:Employee4 a awso:Employee ;
awso:hasName "Callum McAllister".
awsr:Employee5 a awso:Employee ;
awso:hasName "Allison Hunter".
awsr:Employee6 a awso:Employee ;
awso:hasName "Sanjay Singh".
awsr:Employee7 a awso:Employee ;
awso:hasName "Lars Anderson".
awsr:Department1 a awso:Department ;
awso:hasName "Sales & Marketing".
awsr:Department2 a awso:Department ;
awso:hasName "I.T.".
awsr:Department3 a awso:Department ;
awso:hasName "Human Resources".
awsr:Org1 a awso:Organisation ;
awso:hasName "ACME Corp" .
awsr:Org2 a awso:Organisation ;
awso:hasName "NORMCO LTD" .
# Employee 1
awsr:Employee1 awso:hasPosition awsr:Pos1 .
awsr:Pos1 a awso:Position .
awsr:Pos1 awso:hasName "John Smith in Sales&Marketing for ACME Corp" .
awsr:Pos1 awso:inDepartment awsr:Department2 .
awsr:Pos1 awso:withinOrganisation awsr:Org1 .
# Employee 2
awsr:Employee2 awso:hasPosition awsr:Pos2 .
awsr:Pos2 a awso:Position .
awsr:Pos2 awso:hasName "Jane Doe in Sales&Marketing for ACME Corp" .
awsr:Pos2 awso:inDepartment awsr:Department1 .
awsr:Pos2 awso:withinOrganisation awsr:Org1 .
# Employee 3
awsr:Employee3 awso:hasPosition awsr:Pos3 .
awsr:Pos3 a awso:Position .
awsr:Pos3 awso:hasName "Mike Jones in I.T. for ACME Corp" .
awsr:Pos3 awso:inDepartment awsr:Department2 .
awsr:Pos3 awso:withinOrganisation awsr:Org1 .
# Employee 4
awsr:Employee4 awso:hasPosition awsr:Pos4 .
awsr:Pos4 a awso:Position .
awsr:Pos4 awso:hasName "Callum McAllister in I.T. for ACME Corp" .
awsr:Pos4 awso:inDepartment awsr:Department2 .
awsr:Pos4 awso:withinOrganisation awsr:Org1 .
# Employee 5
awsr:Employee5 awso:hasPosition awsr:Pos5 .
awsr:Pos5 a awso:Position .
awsr:Pos5 awso:hasName "Allison Hunter in H.R. for ACME Corp" .
awsr:Pos5 awso:inDepartment awsr:Department3 .
awsr:Pos5 awso:withinOrganisation awsr:Org1 .
# Employee 6
awsr:Employee6 awso:hasPosition awsr:Pos6 .
awsr:Pos6 a awso:Position .
awsr:Pos6 awso:hasName "Sanjay Singh in H.R. for ACME Corp" .
awsr:Pos6 awso:inDepartment awsr:Department3 .
awsr:Pos6 awso:withinOrganisation awsr:Org1 .
# Employee 7
awsr:Employee7 awso:hasPosition awsr:Pos7 .
awsr:Pos7 a awso:Position .
awsr:Pos7 awso:hasName "Lars Anderson in I.T. for NORMCO LTD" .
awsr:Pos7 awso:inDepartment awsr:Department2 .
awsr:Pos7 awso:withinOrganisation awsr:Org2 .
5. Test features with SPARQL
We write a new SPARQL query to satisfy all three features:
| Feature | Description |
|---|---|
| 1 | I want to know which employees work for which departments in the ACME CORP |
| 2 | and I want to list all the names of the employees in the organisation ACME CORP |
| 3 | and I want to list all the workers that work in IT departments across all organisations |
prefix awso: <http://aws.amazon.com/ontology/>
prefix awsr: <http://aws.amazon.com/resource#>
SELECT ?employeeName ?departmentName ?orgName WHERE {
?employee a awso:Employee ;
awso:hasName ?employeeName ;
awso:hasPosition/awso:inDepartment ?department ;
awso:hasPosition/awso:withinOrganisation ?org .
?department awso:hasName ?departmentName .
?org awso:hasName ?orgName .
}
The result shows that we can now satisfy all three features, with the Department URI being the same for every employee that works in I.T.
| employeeName | departmentName | orgName |
|---|---|---|
| John Smith | I.T. | ACME Corp |
| Mike Jones | I.T. | ACME Corp |
| Callum McAllister | I.T. | ACME Corp |
| Jane Doe | Sales & Marketing | ACME Corp |
| Allison Hunter | Human Resources | ACME Corp |
| Sanjay Singh | Human Resources | ACME Corp |
| Lars Anderson | I.T. | NORMCO LTD |
Testing features with multiple SPARQL queries
You could also satisfy your features with seperate SPARQL queries.
For example, here is a SPARQL query designed to satisfy only Feature 3:
| Feature | Description |
|---|---|
| 3 | and I want to list all the workers that work in IT departments across all organisations |
prefix awso: <http://aws.amazon.com/ontology/>
prefix awsr: <http://aws.amazon.com/resource#>
SELECT ?employeeName ?orgName WHERE {
BIND(<http://aws.amazon.com/resource#Department2> as ?ITDepartment)
?employee a awso:Employee ;
awso:hasName ?employeeName ;
awso:hasPosition/awso:inDepartment ?ITDepartment ;
awso:hasPosition/awso:withinOrganisation ?org .
?ITDepartment awso:hasName ?departmentName .
?org awso:hasName ?orgName .
}
Take note of the ‘BIND’ variable in the query, which explicitly sets the Department to be I.T. | employeeName | orgName | |-|-| | John Smith | ACME Corp | | Mike Jones | ACME Corp | | Callum McAllister | ACME Corp | | Lars Anderson | NORMCO LTD |
Using Edges to Facilitate Efficient Graph Queries
The performance of a graph query depends on how much of the graph the query has to ‘touch’ in order to generate a set of results. The larger the working set, the longer it will take to get from storage and then traverse once it has been cached in main memory.
You can ensure your queries touch the minimum amount of data by naming predicates in a way that allows the query engine to follow only those relationships relevant to the query being executed.
Predicate compose and partition the graph. By connecting vertices, they structure the whole, creating a complex composite from what would otherwise be simple islands of data. At the same time they serve to partition the graph, differentiating connections between elements based on name, direction and property values so that queries can identity specific subgraphs within a larger, more variably connected structure. By focussing your queries on certain predicates and the paths they form, you allow the query engine to exclude irrelevant parts of the graph from consideration, effectively materializing a particular view of the graph dedicated to addressing a specific query need.
Predicate names
Derive your predicates from your use cases. Doing so helps structure and partition your data so that queries ignore triples that have no bearing on the working set necessary to satisfy the query.
Bi-directional relationships
If you need to model bi-directional relationships, you will have to add pairs of predicates.
PREFIX j: <http://www.example.com/jobs#>
INSERT
{
j:p-1 j:worksWith j:p-2 .
j:p-2 j:worksWith j:p-1 .
}
WHERE {}
Uni-directional relationships
The directed nature of edges naturally lends itself to expressing uni-directional relationships.
In SPARQL:
PREFIX s: <http://www.example.com/social#>
SELECT ?followees WHERE {
s:p-1 s:follows ?followees
}
and:
PREFIX s: <http://www.example.com/social#>
SELECT ?followers WHERE {
?followers s:follows s:p-1
}
Multiple relationships between nodes
With RDF you can connect any pair of nodes with multiple relationships with different names. Connecting a pair of nodes with multiple relationships with the same name is slightly more complicated. RDF does not have a concept of relationship identity that would serve to distinguish predicate instances. To connect a pair of nodes with multiple relationships with the same name you will have to introduce intermediate nodes, one per instance of the relationship. This is another example of Reification.