Multi-Cluster Multi-Region Monitoring
Architecture¤
The following figure illustrates the architecture of the pattern we will be deploying for Multi-Account Multi-Region Mixed Observability (M3) Accelerator using both AWS native tooling such as: CloudWatch ContainerInsights, CloudWatch logs and Open source tooling such as AWS Distro for Open Telemetry (ADOT), Amazon Managed Service for Prometheus (AMP), Amazon Managed Grafana :
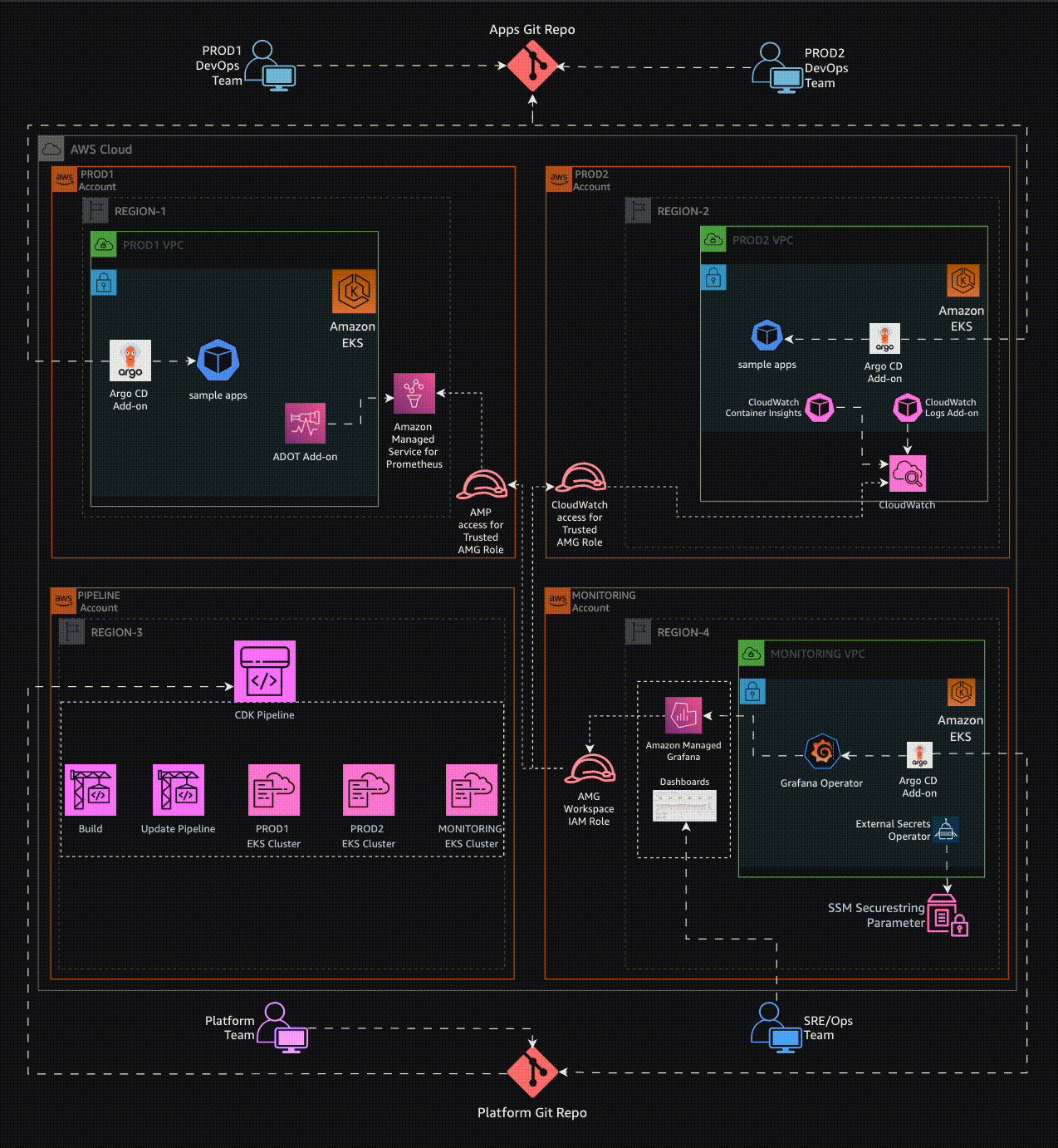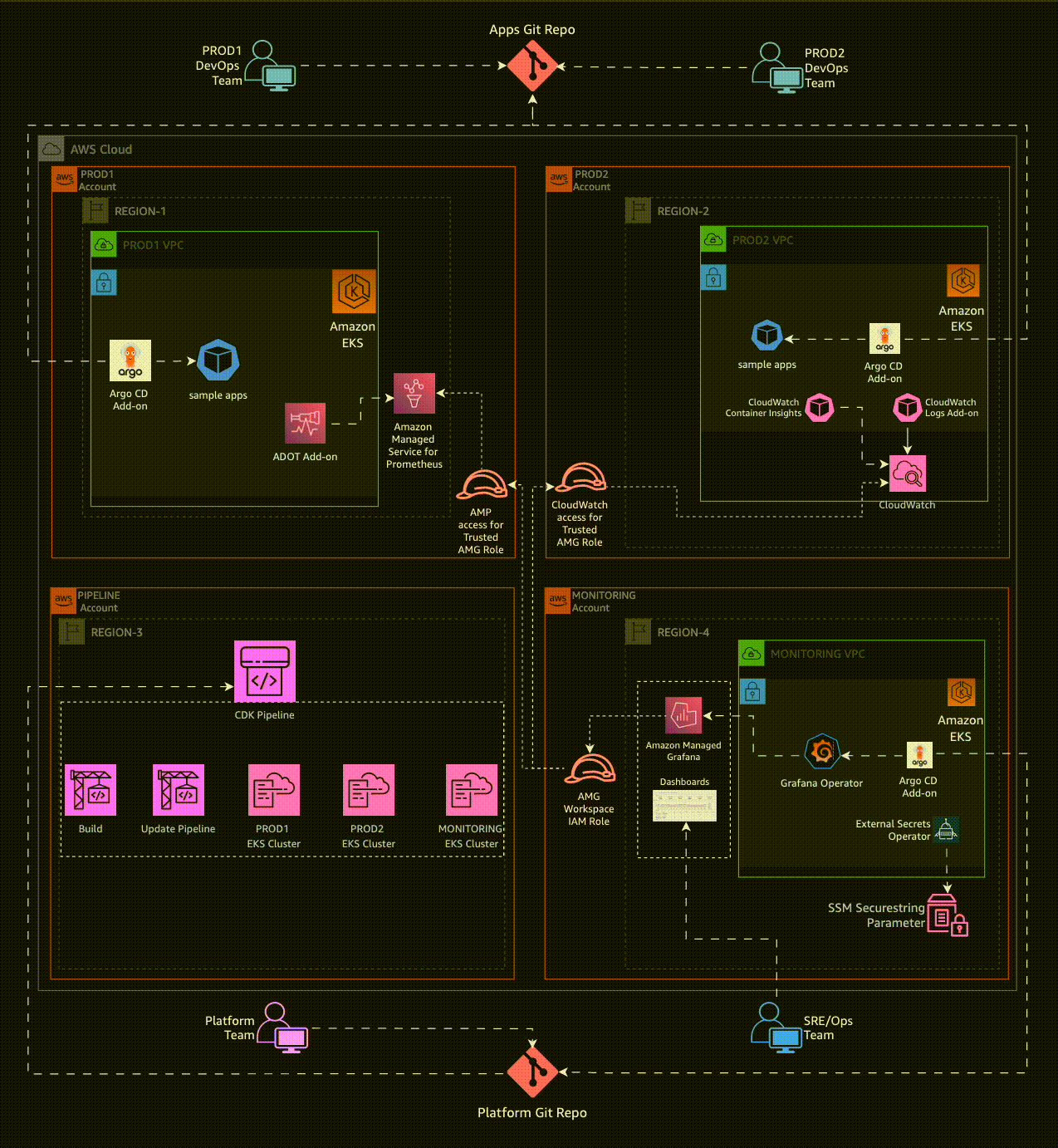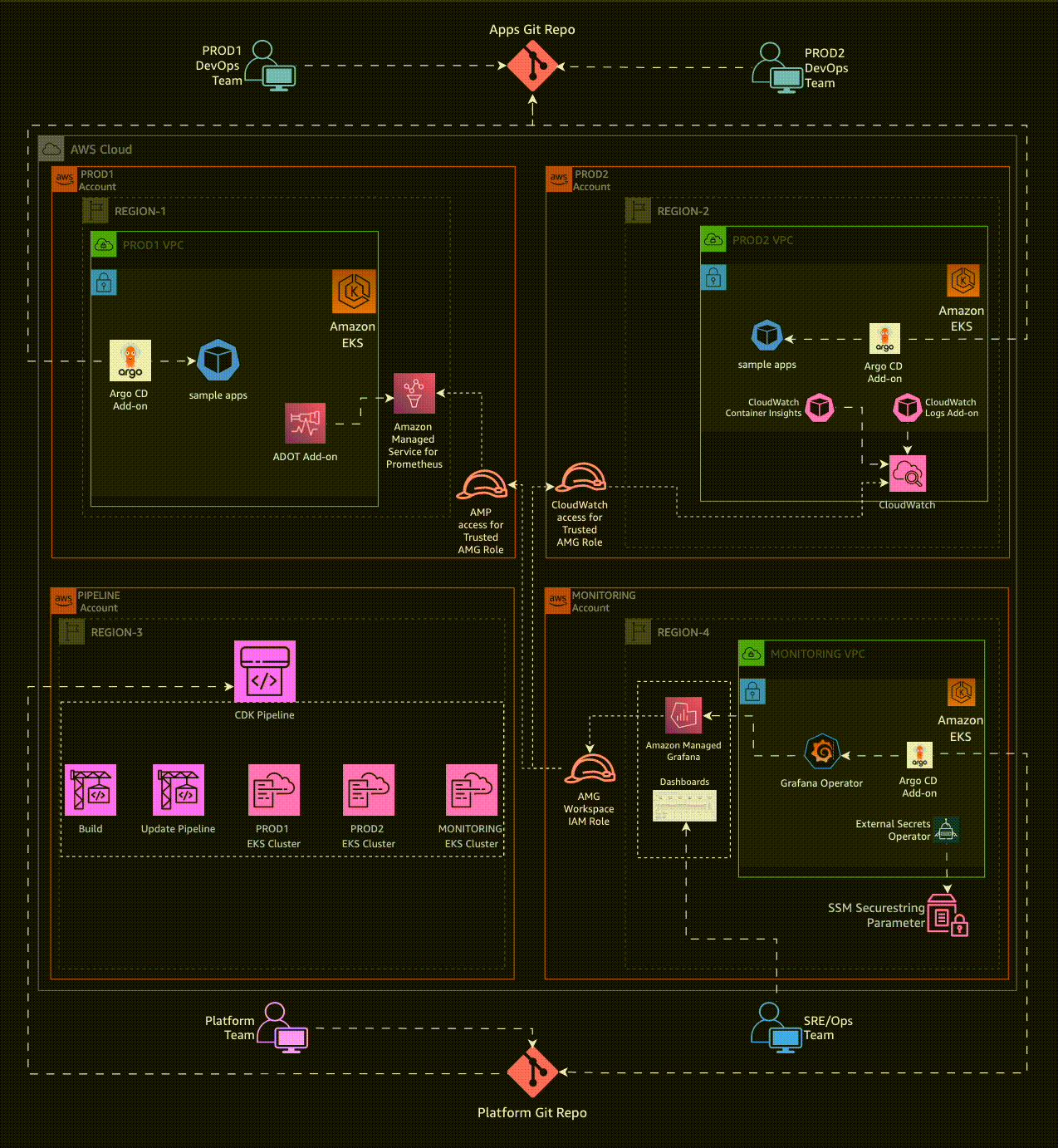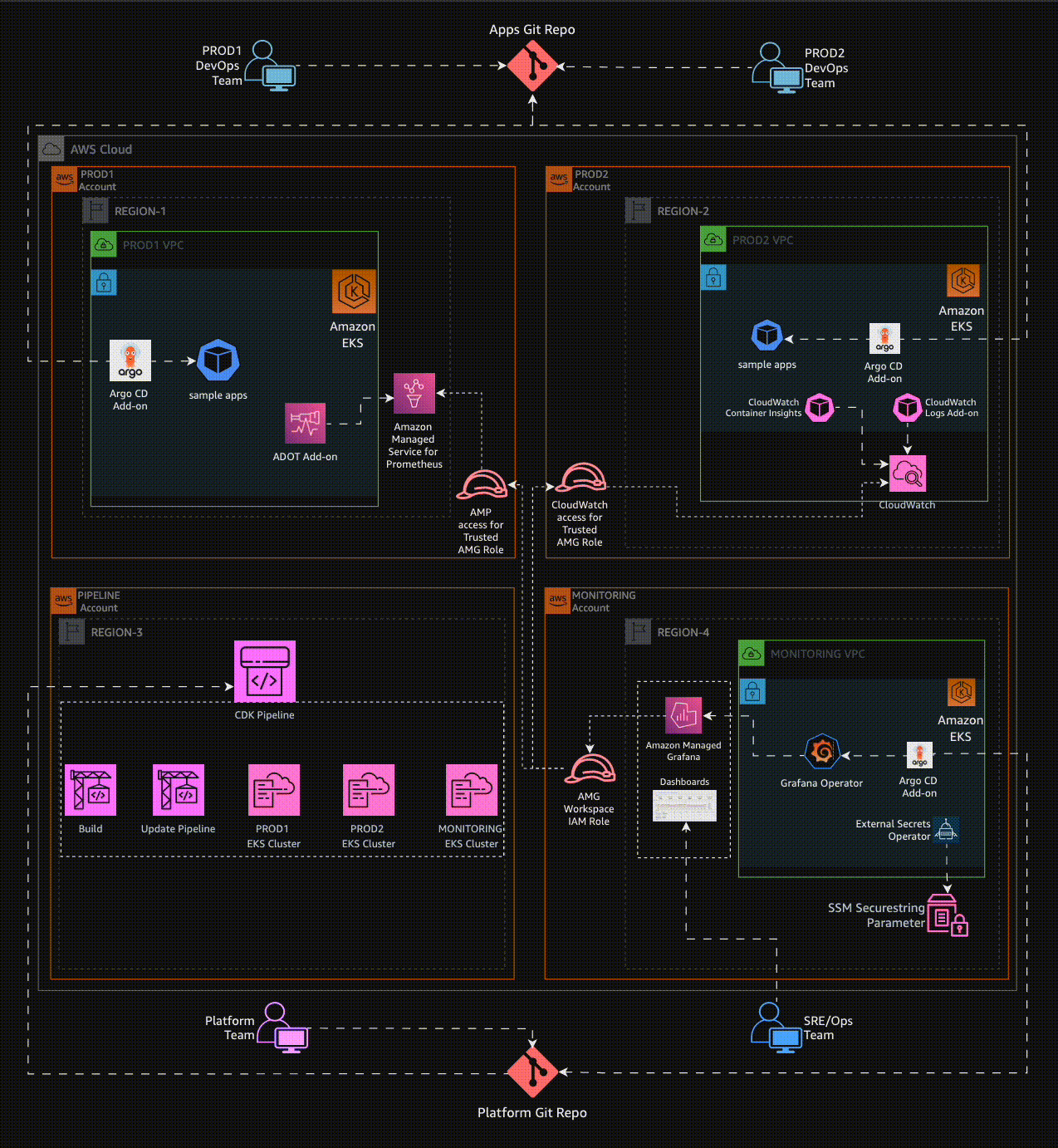
Objective¤
- Deploying two production grade Amazon EKS cluster with control plane logging across two AWS Accounts (Prod1, Prod2 account) in two different regions through a Continuous Deployment infrastructure pipeline triggered upon a commit to the repository that holds the pipeline configuration in another AWS account (pipeline account).
- Deploying ADOT add-on, AMP add-on to Prod 1 Amazon EKS Cluster to remote-write metrics to AMP workspace in Prod 1 AWS Account.
- Deploying ADOT add-on, CloudWatch add-on to Prod 2 Amazon EKS Cluster to write metrics to CloudWatch in Prod 2 AWS Account.
- Configuring GitOps tooling (Argo CD add-on) to support deployment of ho11y and yelb sample applications, in a way that restricts each application to be deployed only into the team namespace, by using Argo CD projects.
- Setting up IAM roles in Prod 1 and Prod 2 Accounts to allow an AMG service role in the Monitoring account (mon-account) to access metrics from AMP workspace in Prod 1 account and CloudWatch namespace in Prod 2 account.
- Setting Amazon Managed Grafana to visualize AMP metrics from Amazon EKS cluster in Prod account 1 and CloudWatch metrics on workloads in Amazon EKS cluster in Prod account 2.
- Installing Grafana Operator in Monitoring account (mon-account) to add AWS data sources and create Grafana Dashboards to Amazon Managed Grafana.
- Installing External Secrets Operator in Monitoring account (mon-account) to retrieve and Sync the Grafana API keys.
GitOps configuration¤
- For GitOps, this pattern bootstraps Argo CD add-on and points to sample applications in AWS Observability Accelerator.
- You can find the team-geordie configuration for this pattern in the workload repository under the folder
team-geordie. - GitOps based management of Amazon Grafana resources (like: Datasources and Dashboards) is achieved using Argo CD application
grafana-operator-app. Grafana Operator resources are deployed usinggrafana-operator-chart.
Prerequisites¤
Ensure following tools are installed in host machine:
AWS Accounts¤
- AWS Control Tower deployed in your AWS environment in the management account. If you have not already installed AWS Control Tower, follow the Getting Started with AWS Control Tower documentation, or you can enable AWS Organizations in the AWS Management Console account and enable AWS SSO.
- An AWS account under AWS Control Tower called Prod 1 Account(Workloads Account A aka
prodEnv1) provisioned using the AWS Service Catalog Account Factory product AWS Control Tower Account vending process or AWS Organization. - An AWS account under AWS Control Tower called Prod 2 Account(Workloads Account B aka
prodEnv2) provisioned using the AWS Service Catalog Account Factory] product AWS Control Tower Account vending process or AWS Organization. - An AWS account under AWS Control Tower called Pipeline Account (aka
pipelineEnv) provisioned using the AWS Service Catalog Account Factory product AWS Control Tower Account vending process or AWS Organization. - An AWS account under AWS Control Tower called Monitoring Account (Grafana Account aka
monitoringEnv) provisioned using the AWS Service Catalog Account Factory product AWS Control Tower Account vending process or AWS Organization. - An existing Amazon Managed Grafana Workspace in
monitoringEnvregion ofmonitoringEnvaccount. Enable Data sources AWS X-Ray, Amazon Managed Service for Prometheus and Amazon Cloudwatch. - If you are bringing new AWS accounts to deploy this pattern, then create a free-tier EC2 instance and let it run for 15-30 minutes in order to complete validation of account.
NOTE: This pattern consumes multiple Elastic IP addresses, because 3 VPCs with 3 subnets are created in
ProdEnv1,ProdEnv2andmonitoringEnvAWS accounts. Make sure your account limits for EIP are increased to support additional 3 EIPs per account.
Clone Repository¤
Clone cdk-aws-observability-accelerator repository, if not done already.
git clone https://github.com/aws-observability/cdk-aws-observability-accelerator.git
cd cdk-aws-observability-accelerator
Pro Tip: This document is compatible to run as Notebook with RUNME for VS Code. There's no need to manually copy and paste commands. You can effortlessly execute them directly from this markdown file. Feel free to give it a try.
Here is a sample usage of this document using RUNME:
SSO Profile Setup¤
- You will be accessing multiple accounts during deployment of this pattern. It is recommended to configure the AWS CLI to authenticate access with AWS IAM Identity Center (successor to AWS Single Sign-On). Let's configure Token provider with automatic authentication refresh for AWS IAM Identity Center. Ensure Prerequisites mentioned here are complete before proceeding to next steps.
- Create and use AWS IAM Identity Center login with
AWSAdministratorAccessPermission set assigned to all AWS accounts required for this pattern (prodEnv1, prodEnv2, pipelineEnv and monitoringEnv). - Configure AWS profile with sso for
pipelineEnvaccount:
aws configure sso --profile pipeline-account
# sample configuration
# SSO session name (Recommended): coa-multi-access-sso
# SSO start URL [None]: https://d-XXXXXXXXXX.awsapps.com/start
# SSO region [None]: us-west-2
# SSO registration scopes [sso:account:access]:sso:account:access
# Attempting to automatically open the SSO authorization page in your default browser.
# If the browser does not open or you wish to use a different device to authorize this request, open the following URL:
# https://device.sso.us-west-2.amazonaws.com/
# Then enter the code:
# XXXX-XXXX
# There are 7 AWS accounts available to you.
# Using the account ID 111122223333
# There are 2 roles available to you.
# Using the role name "AWSAdministratorAccess"
# CLI default client Region [None]: us-west-2
# CLI default output format [None]: json
# To use this profile, specify the profile name using --profile, as shown:
# aws s3 ls --profile pipeline-account
- Then, configure profile for
ProdEnv1AWS account.
aws configure sso --profile prod1-account
# sample configuration
# SSO session name (Recommended): coa-multi-access-sso
# There are 7 AWS accounts available to you.
# Using the account ID 444455556666
# There are 2 roles available to you.
# Using the role name "AWSAdministratorAccess"
# CLI default client Region [None]: us-west-2
# CLI default output format [None]: json
# To use this profile, specify the profile name using --profile, as shown:
# aws s3 ls --profile prod2-account
- Then, configure profile for
ProdEnv2AWS account.
aws configure sso --profile prod2-account
- Then, configure profile for
monitoringEnvAWS account.
aws configure sso --profile monitoring-account
- Login to required SSO profile using
aws sso login --profile <profile name>. Let's now log in topipelineEnvaccount. When SSO login expires, you can use this command to re-login.
export AWS_PROFILE='pipeline-account'
aws sso login --profile $AWS_PROFILE
- Export required environment variables for further use. If not available already, you will be prompted for name of Amazon Grafana workspace in
monitoringEnvregion ofmonitoringEnvaccount. And, then its endpoint URL, ID, Role ARN will be captured as environment variables.
source `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/source-envs.sh
- Create SSM SecureString Parameter
/cdk-accelerator/cdk-contextinpipelineEnvregion ofpipelineEnvaccount. This parameter contains account ID and region of all four AWS accounts used in this Observability Accelerator pattern.
aws ssm put-parameter --profile pipeline-account --region ${COA_PIPELINE_REGION} \
--type "SecureString" \
--overwrite \
--name "/cdk-accelerator/cdk-context" \
--description "AWS account details of different environments used by Multi-Account Multi-Region Mixed Observability (M3) Accelerator pattern" \
--value '{
"context": {
"pipelineEnv": {
"account": "'$COA_PIPELINE_ACCOUNT_ID'",
"region": "'$COA_PIPELINE_REGION'"
},
"prodEnv1": {
"account": "'$COA_PROD1_ACCOUNT_ID'",
"region": "'$COA_PROD1_REGION'"
},
"prodEnv2": {
"account": "'$COA_PROD2_ACCOUNT_ID'",
"region": "'$COA_PROD2_REGION'"
},
"monitoringEnv": {
"account": "'$COA_MON_ACCOUNT_ID'",
"region": "'$COA_MON_REGION'"
}
}
}'
Amazon Grafana Configuration¤
-
Run
helpers/multi-acc-new-eks-mixed-observability-pattern/amg-preconfig.shscript to -
create SSM SecureString parameter
/cdk-accelerator/amg-infoinpipelineEnvregion ofpipelineEnvaccount. This will be used by CDK for Grafana Operator resources configuration. - create Grafana workspace API key.
- create SSM SecureString parameter
/cdk-accelerator/grafana-api-keyinmonitoringEnvregion ofmonitoringEnvaccount. This will be used by External Secrets Operator.
eval bash `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/amg-preconfig.sh
GitHub Sources Configuration¤
-
Following GitHub sources used in this pattern:
-
Apps Git Repo - This repository serves as the source for deploying and managing applications in
prodEnv1andprodEnv2using GitOps by Argo CD. Here, it is configured to sample-apps from aws-observability-accelerator. - Source for CodePipeline - This repository serves as the CodePipeline source stage for retrieving and providing source code to downstream pipeline stages, facilitating automated CI/CD processes. Whenever a change is detected in the source code, the pipeline is initiated automatically. This is achieved using GitHub webhooks. We are using CodePipeline to deploy multi-account multi-region clusters.
- Source for
monitoringEnvArgo CD - This repository serves as the source for deploying and managing applications in themonitoringEnvenvironment using GitOps by Argo CD. Here, it is configured to grafana-operator-app from aws-observability-accelerator, using which Grafana Datasoures and Dashboards are deployed.
NOTE: Argo CD source repositories used here for
prodEnv1,prodEnv2andmonitoringEnvare public. If you need to use private repositories, create secret calledgithub-ssh-keyin respective accounts and region. This secret should contain your GitHub SSH private key as a JSON structure with fieldssshPrivateKeyandurlin AWS Secrets Manager. Argo CD add-on will use this secret for authentication with private GitHub repositories. For more details on setting up SSH credentials, please refer to Argo CD Secrets Support.
- Fork
cdk-aws-observability-acceleratorrepository to your GitHub account. -
Create GitHub Personal Access Token (PAT) for your CodePipeline GitHub source. For more information on how to set it up, please refer here. The GitHub Personal Access Token should have these scopes:
-
repo - to read the repository
-
admin:repo_hook - to use webhooks
-
Run
helpers/multi-acc-new-eks-mixed-observability-pattern/gitsource-preconfig.shscript to -
create SSM SecureString Parameter
/cdk-accelerator/pipeline-git-infoinpipelineEnvregion ofpipelineEnvaccount which contains details of CodePipeline source. This parameter contains GitHub owner name where you forkedcdk-aws-observability-accelerator, repository name (cdk-aws-observability-accelerator) and branch (main). - create AWS Secret Manager secret
github-tokeninpipelineEnvregion ofpipelineEnvaccount to hold GitHub Personal Access Token (PAT).
eval bash `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/gitsource-preconfig.sh
Deployment¤
- Fork
cdk-aws-observability-acceleratorrepository to your CodePioeline source GitHub organization/user. - Install the AWS CDK Toolkit globally on host machine.
npm install -g aws-cdk
- Install project dependencies.
cd `git rev-parse --show-toplevel`
npm i
make build
- Bootstrap all 4 AWS accounts using step mentioned for different environment for deploying CDK applications in Deploying Pipelines. If you have bootstrapped earlier, please remove them before proceeding with this step. Remember to set
pipelineEnvaccount number in--trustflag. You can also refer to commands mentioned below:
# bootstrap pipelineEnv account WITHOUT explicit trust
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap --profile pipeline-account \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
aws://${COA_PIPELINE_ACCOUNT_ID}/${COA_PIPELINE_REGION}
# bootstrap prodEnv1 account with trust access from pipelineEnv account
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap --profile prod1-account \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
--trust ${COA_PIPELINE_ACCOUNT_ID} \
aws://${COA_PROD1_ACCOUNT_ID}/${COA_PROD1_REGION}
# bootstrap prodEnv2 account with trust access from pipelineEnv account
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap --profile prod2-account \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
--trust ${COA_PIPELINE_ACCOUNT_ID} \
aws://${COA_PROD2_ACCOUNT_ID}/${COA_PROD2_REGION}
# bootstrap monitoringEnv account with trust access from pipelineEnv account
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap --profile monitoring-account \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
--trust ${COA_PIPELINE_ACCOUNT_ID} \
aws://${COA_MON_ACCOUNT_ID}/${COA_MON_REGION}
- Once all pre-requisites are set, you are ready to deploy the pipeline. Run the following command from the root of cloned repository to deploy the pipeline stack in
pipelineEnvaccount. This step may require approximately 20 minutes to finish.
export AWS_PROFILE='pipeline-account'
export AWS_REGION=${COA_PIPELINE_REGION}
cd `git rev-parse --show-toplevel`
make pattern multi-acc-new-eks-mixed-observability deploy multi-account-COA-pipeline
-
Check status of pipeline that deploys multiple Amazon EKS clusters through CloudFromation stacks in respective accounts. This deployment also creates
-
ampPrometheusDataSourceRolewith permissions to retrieve metrics from AMP inProdEnv1account, cloudwatchDataSourceRolewith permissions to retrieve metrics from CloudWatch inProdEnv2account and- Updates Amazon Grafana workspace IAM role in
monitoringEnvaccount to assume roles inProdEnv1andProdEnv2accounts for retrieving and visualizing metrics in Grafana
This step may require approximately 50 minutes to finish. You may login to pipelineEnv account and navigate to AWS CodePipeline console at pipelineEnv region to check the status.
# script to check status of codepipeline
dots=""; while true; do status=$(aws codepipeline --profile pipeline-account list-pipeline-executions --pipeline-name multi-account-COA-pipeline --query 'pipelineExecutionSummaries[0].status' --output text); [ $status == "Succeeded" ] && echo -e "Pipeline execution SUCCEEDED." && break || [ "$status" == "Failed" ] && echo -e "Pipeline execution FAILED." && break || printf "\r" && echo -n "Pipeline execution status: $status$dots" && dots+="." && sleep 10; done
Post Deployment¤
-
Once all steps of
multi-acc-stagesinmulti-account-COA-pipelineare complete, run script to -
create entries in kubeconfig with contexts of newly created EKS clusters.
- export cluster specific and kubecontext environment variables (like:
COA_PROD1_CLUSTER_NAMEandCOA_PROD1_KUBE_CONTEXT). - get Amazon Prometheus Endpoint URL from
ProdEnv1account and export to environment variableCOA_AMP_ENDPOINT_URL.
source `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/post-deployment-source-envs.sh
- Then, update parameter
AMP_ENDPOINT_URLof Argo CD bootstrap app inmonitoringEnvwith Amazon Prometheus endpoint URL fromProdEnv1account (COA_AMP_ENDPOINT_URL) and sync Argo CD apps.
if [[ `lsof -i:8080 | wc -l` -eq 0 ]]
then
export ARGO_SERVER=$(kubectl --context ${COA_MON_KUBE_CONTEXT} -n argocd get svc -l app.kubernetes.io/name=argocd-server -o name)
export ARGO_PASSWORD=$(kubectl --context ${COA_MON_KUBE_CONTEXT} -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d)
echo "ARGO PASSWORD:: "$ARGO_PASSWORD
kubectl --context ${COA_MON_KUBE_CONTEXT} port-forward $ARGO_SERVER -n argocd 8080:443 > /dev/null 2>&1 &
argocdPid=$!
echo pid: $argocdPid
sleep 5s
argocd --kube-context ${COA_MON_KUBE_CONTEXT} login localhost:8080 --insecure --username admin --password $ARGO_PASSWORD
argocd --kube-context ${COA_MON_KUBE_CONTEXT} app set argocd/bootstrap-apps --helm-set AMP_ENDPOINT_URL=$COA_AMP_ENDPOINT_URL
argocd --kube-context ${COA_MON_KUBE_CONTEXT} app sync argocd/bootstrap-apps
echo -e '\033[0;33m' "\nConfirm update here.. You should see AMP endpoint URL and no error message." '\033[0m'
kubectl --context ${COA_MON_KUBE_CONTEXT} get -n grafana-operator grafanadatasources grafanadatasource-amp -o jsonpath='{.spec.datasource.url}{"\n"}{.status}{"\n"}'
kill -9 $argocdPid
else
echo "Port 8080 is already in use by PID `lsof -i:8080 -t`. Please terminate it and rerun this step."
fi
NOTE: You can access Argo CD Admin UI using port-forwading. Here are commands to access
prodEnv1Argo CD:
export PROD1_ARGO_SERVER=$(kubectl --context ${COA_PROD1_KUBE_CONTEXT} -n argocd get svc -l app.kubernetes.io/name=argocd-server -o name)
export PROD1_ARGO_PASSWORD=$(kubectl --context ${COA_PROD1_KUBE_CONTEXT} -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d)
echo "PROD1 ARGO PASSWORD:: "$PROD1_ARGO_PASSWORD
nohup kubectl --context ${COA_PROD1_KUBE_CONTEXT} port-forward $PROD1_ARGO_SERVER -n argocd 8081:443 > /dev/null 2>&1 &
sleep 5
curl localhost:8081
- Datasource
grafana-operator-amp-datasourcecreated by Grafana Operator needs to reflect AMP Endpoint URL. There is a limitation with Grafana Operator (or Grafana) which doesn't sync updatedgrafana-datasourcesto Grafana. To overcome this issue, we will simply delete Datasource and Grafana Operator syncs up with the latest configuration in 5 minutes. This is achieved using Grafana API and key stored in SecureString parameter/cdk-accelerator/grafana-api-keyinmonitoringEnvaccount.
export COA_AMG_WORKSPACE_URL=$(aws ssm get-parameter --profile pipeline-account --region ${COA_PIPELINE_REGION} \
--name "/cdk-accelerator/amg-info" \
--with-decryption \
--query Parameter.Value --output text | jq -r ".[] | .workspaceURL")
export COA_AMG_API_KEY=$(aws ssm get-parameter --profile monitoring-account --region ${COA_MON_REGION} \
--name "/cdk-accelerator/grafana-api-key" \
--with-decryption \
--query Parameter.Value --output text)
export COA_AMP_DS_ID=$(curl -s -H "Authorization: Bearer ${COA_AMG_API_KEY}" ${COA_AMG_WORKSPACE_URL}/api/datasources \
| jq -r ".[] | select(.name==\"grafana-operator-amp-datasource\") | .id")
echo "Datasource Name:: grafana-operator-amp-datasource"
echo "Datasource ID:: "$COA_AMP_DS_ID
curl -X DELETE -H "Authorization: Bearer ${COA_AMG_API_KEY}" ${COA_AMG_WORKSPACE_URL}/api/datasources/${COA_AMP_DS_ID}
- Then, deploy ContainerInsights in
ProdEnv2account.
prod2NGRole=$(aws cloudformation describe-stack-resources --profile prod2-account --region ${COA_PROD2_REGION} \
--stack-name "coa-eks-prod2-${COA_PROD2_REGION}-coa-eks-prod2-${COA_PROD2_REGION}-blueprint" \
--query "StackResources[?ResourceType=='AWS::IAM::Role' && contains(LogicalResourceId,'NodeGroupRole')].PhysicalResourceId" \
--output text)
aws iam attach-role-policy --profile prod2-account --region ${COA_PROD2_REGION} \
--role-name ${prod2NGRole} \
--policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy
aws iam list-attached-role-policies --profile prod2-account --region ${COA_PROD2_REGION} \
--role-name $prod2NGRole | grep CloudWatchAgentServerPolicy || echo 'Policy not found'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${COA_PROD2_CLUSTER_NAME}'/;s/{{region_name}}/'${COA_PROD2_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl --context ${COA_PROD2_KUBE_CONTEXT} apply -f -
Validating Grafana Dashboards¤
- Run the below command in
ProdEnv1cluster to generate test traffic to sample application and let us visualize traces to X-Ray and Amazon Managed Grafana Console out the sampleho11yapp :
frontend_pod=`kubectl --context ${COA_PROD1_KUBE_CONTEXT} get pod -n geordie --no-headers -l app=frontend -o jsonpath='{.items[*].metadata.name}'`
loop_counter=0
while [ $loop_counter -le 5000 ] ;
do
kubectl exec --context ${COA_PROD1_KUBE_CONTEXT} -n geordie -it $frontend_pod -- curl downstream0.geordie.svc.cluster.local;
echo ;
loop_counter=$[$loop_counter+1];
done
- Let it run for a few minutes and look in Amazon Grafana Dashboards > Observability Accelerator Dashboards > Kubernetes / Compute Resources / Namespace (Workloads)
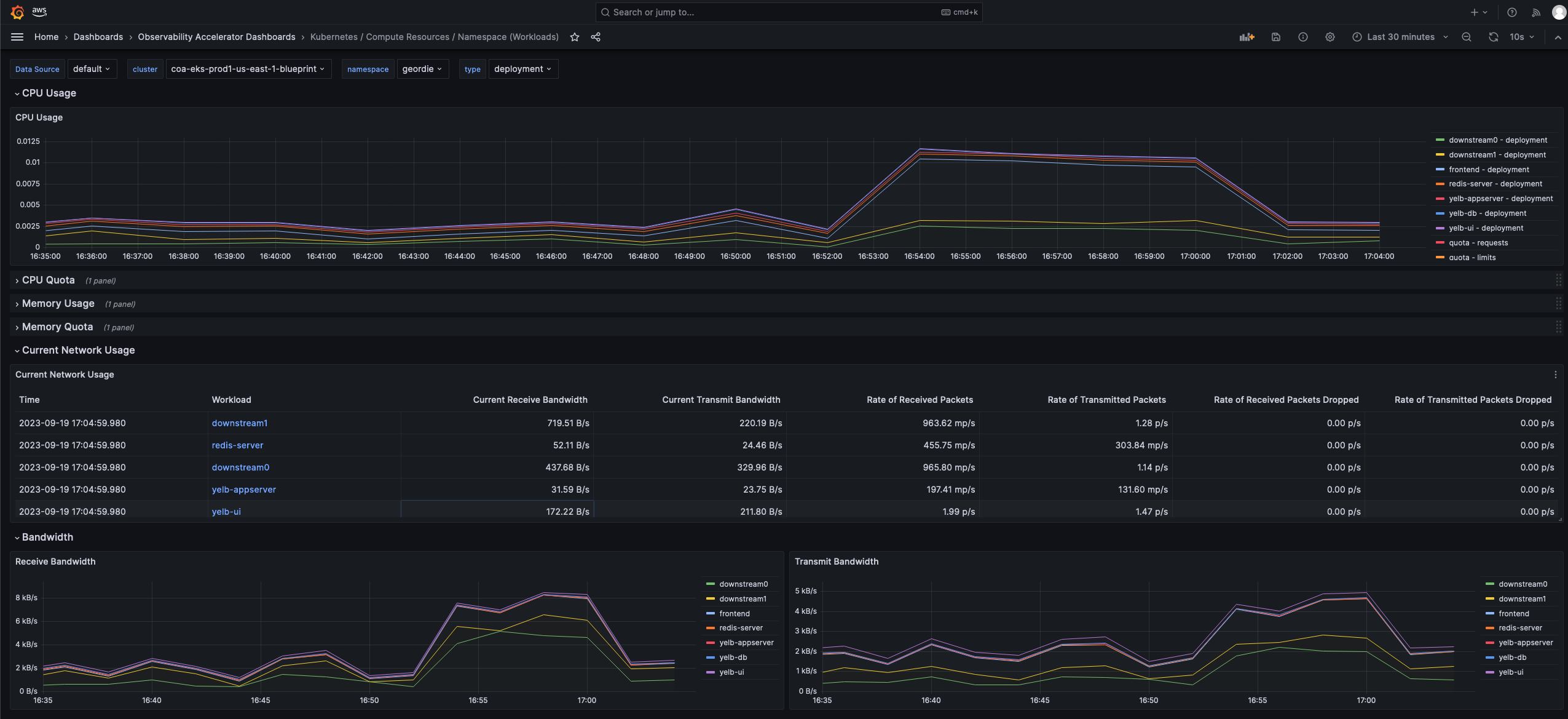
Please also have a look at other Dashboards created using Grafana Operator under folder Observability Accelerator Dashboards.
- Run the below command in
ProdEnv2cluster to generate test traffic to sample application.
frontend_pod=`kubectl --context ${COA_PROD2_KUBE_CONTEXT} get pod -n geordie --no-headers -l app=frontend -o jsonpath='{.items[*].metadata.name}'`
loop_counter=0
while [ $loop_counter -le 5000 ] ;
do
kubectl exec --context ${COA_PROD2_KUBE_CONTEXT} -n geordie -it $frontend_pod -- curl downstream0.geordie.svc.cluster.local;
echo ;
loop_counter=$[$loop_counter+1];
done
- Let it run for a few minutes and look in Amazon Grafana Administration > Datasources > grafana-operator-cloudwatch-datasource > Explore. Set values as highlighted in the snapshot and 'Run query'.
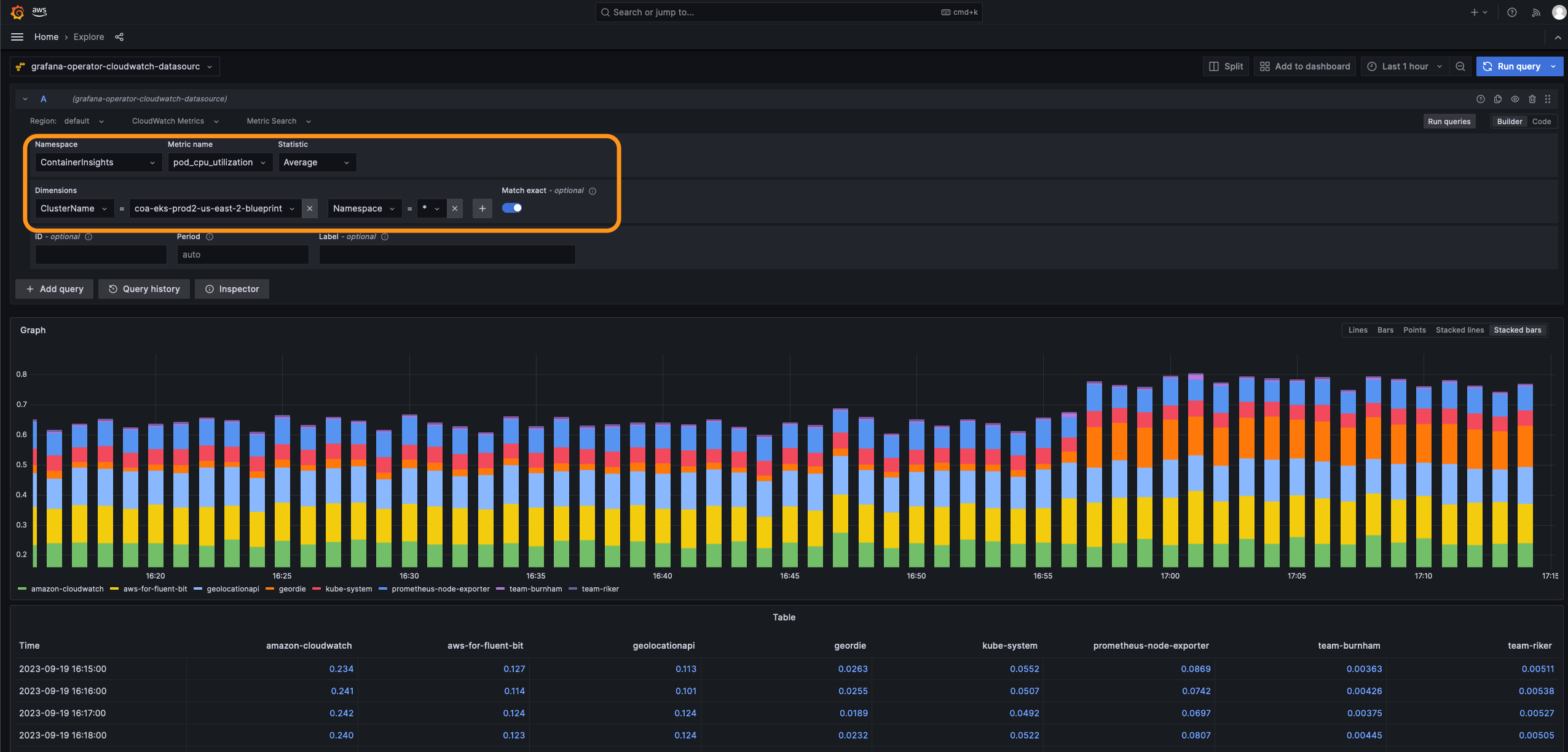
- Then, let us look at X-Ray traces in Amazon Grafana Administration > Datasources > grafana-operator-xray-datasource > Explore. Set Query Type = Service Map and 'Run query'.
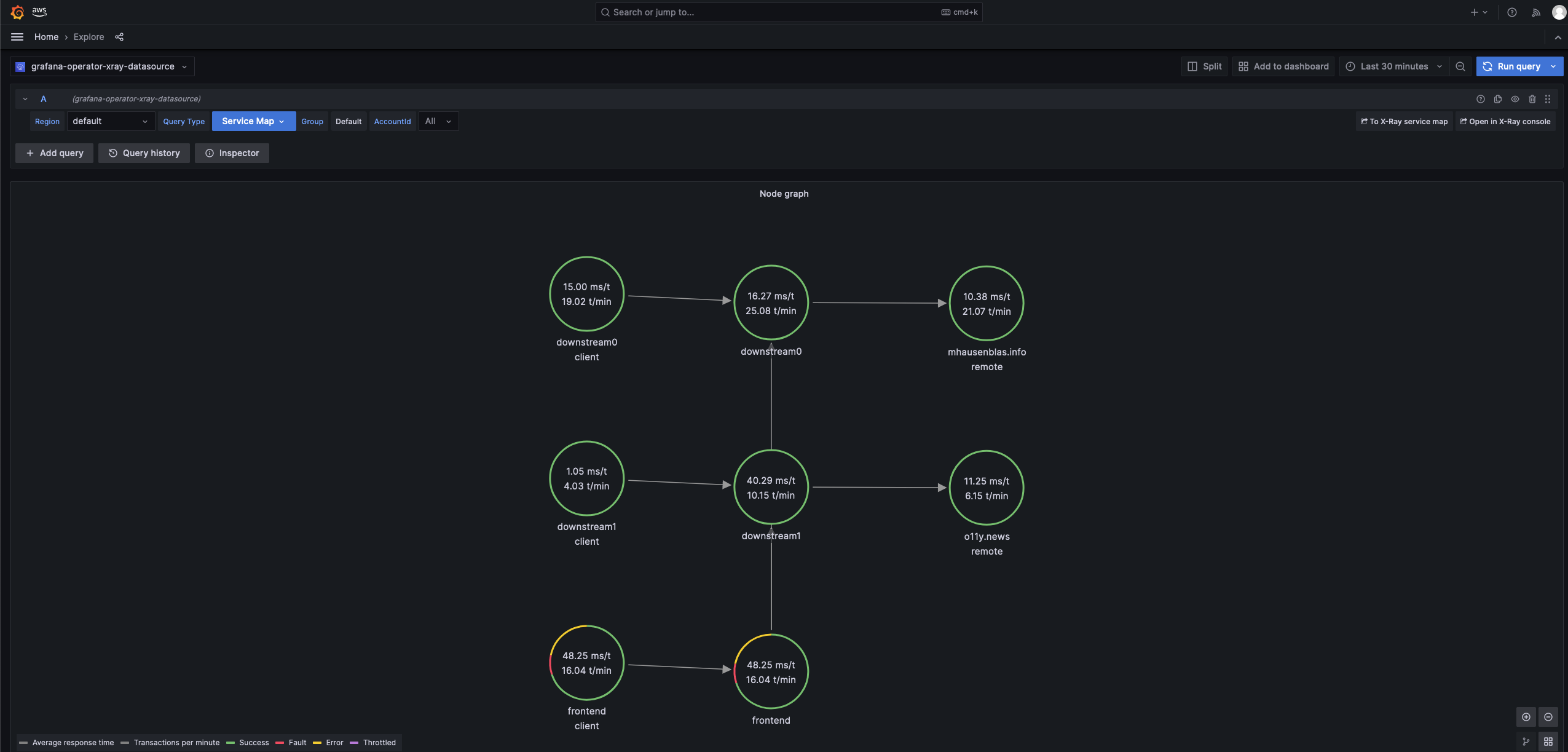
Clean up¤
- Run this command to destroy this pattern. This will delete pipeline.
export AWS_PROFILE='pipeline-account'
aws sso login --profile $AWS_PROFILE
cd `git rev-parse --show-toplevel`
source `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/source-envs.sh
make pattern multi-acc-new-eks-mixed-observability destroy multi-account-COA-pipeline
- Next, run this script to clean up resources created in respective accounts. This script deletes Argo CD apps, unsets kubeconfig entries, initiates deletion of CloudFormation stacks, secrets, SSM parameters and Amazon Grafana Workspace API key from respective accounts.
eval bash `git rev-parse --show-toplevel`/helpers/multi-acc-new-eks-mixed-observability-pattern/clean-up.sh
- In certain scenarios, CloudFormation stack deletion might encounter issues when attempting to delete a nodegroup IAM role. In such situations, it's recommended to first delete the relevant IAM role and then proceed with deleting the CloudFormation stack.
- Delete Dashboards and Data sources in Amazon Grafana.