Monitoring, Logging & Alarme
Themen
Einleitung
Eine erfolgreiche Landung von einem Flugzeug ist nur möglich, wenn das Flugzeug die Höhe, Neigung, und weitere Metriken misst und dem Pilot anzeigt, damit dieser die Metriken beobachten kann (Monitoring) und basierend darauf Entscheidungen trifft. Zudem besitzt ein Flugzeug eine Blackbox, die Daten vom Flugzeug aufzeichnet, damit im Falle einer Fehlfunktion nachvollzogen werden kann, welche Aktionen zu der Fehlfunktion geführt haben (Logging). In der Interaktion zwischen Pilot und Flugzeug wird der Pilot durch Warnleuchten und Warntöne alarmiert, wenn bestimmte Metriken einen bestimmten Schwellenwert über- oder unterschreite (Alarming), zum Beispiel wenn die Neigung zu steil ist. Monitoring, Logging, und Alarming tragen wesentlich zum erfolgreichen Flug bei. Aus dem gleichen Grund sind diese drei Konzepte auch bei anderen Interaktionen zwischen Mensch und System nicht wegzudenken. Im nächsten Abschnitt lernst du Monitoring, Logging, und Alarming im Kontext von der Interaktion zwischen Menschen und Computern kennen.
Technische Konzepte
Du hast bereits gelernt, dass Monitoring, das Messen und Beobachten von einem System bedeutet. Diese Messwerte werden als Metriken bezeichnet. Computer können auch durch Messwerte wie zum Beispiel CPU-Auslastung, Netzwerk-Nutzung, und Speicherkapazität beobachtet werden. Als Computernutzer kannst du diese Metriken mit Programmen anschauen, wie zum Beispiel dem Task Manager in Windows, Activity Monitor in MacOS, und top Command auf Linux. In den meisten Fällen stehen diese Programme auf Servern nicht zur Verfügung, bzw. werden nicht ausgeführt, da kein Nutzer direkt über einen Bildschirm mit dem Betriebssystem interagiert. Stattdessen können Server Metriken messen und an einen Clouddienst für Monitoring senden, damit die verantwortlichen Personen die Metriken beobachten können. So kann zum Beispiel die Entscheidung getroffen werden, dass eine Applikation einen besseren Server benötigt, da die CPU konstant vollständig ausgelastet ist.
Logging bedeutet die Aktionen, die ein System vornimmt aufzuzeichnen, damit die Historie der Aktionen nachvollziehbar ist. Sicher kennst du Logging vom Implementieren von Applikationen. Mit System.out.println("Hallo") in Java, print("Hallo") in Python, und console.log("Hello") in JavaScript kann der Programmierer eine Nachricht auf der Konsole ausgeben. In einer Cloudumgebung kann ein Server diese allgemeinen Nachrichten, Warnungen, und Fehlermeldungen an einen zentralen Clouddienst für Logging senden, damit die Ausgabe sichtbar ist. Dies ermöglicht zum Beispiel das Debuggen eines Fehlers der Applikation laufend auf einem Server.
In einer Cloudumgebung können Alarme definiert werden, um bestimmte Personen oder andere Systeme auf eine eingetretene Situation aufmerksam zu machen. Ein Alarm wird definiert durch einen Grenzwert für eine Metrik und eine Aktion, die der Alarm ausführen soll. Eine Beispieldefinition ist alarmiere Telefonnummer +41 XX XXX XX XX per SMS (Aktion), wenn die Anzahl der Container in einem Cluster (Metrik) kleiner als 3 (Schwellenwert) ist. In diesem Fall wird eine Person per SMS darauf aufmerksam gemacht, dass wahrscheinlich ein Container abgestürzt ist und ein Eingriff erforderlich ist. Ein Alarm kann auch zur Automatisierung genutzt werden. Zum Beispiel kann ein Alarm das Starten weiterer Container auslösen, wenn alle existierenden Container mit der Anzahl der Anfragen ausgelastet sind. Diese Automatisierung kann hilfreich sein für Events mit einer außergewöhnlichen Anzahl an Anfragen von Kunden, wie zum Beispiel Black Friday. In diesem Fall würde das System durch den Alarm automatisch skalieren, ohne dass ein Mensch eingreifen muss.
Relevante AWS Services
Der Service Amazon CloudWatch bietet die zentrale Sammlung, Analyse und Auswertung von Logfiles, Metriken und Alarmierung bei Ereignissen für eine Vielzahl von Anwendungsfällen wie z.B. die Überwachung der Infrastruktur, Optimierung von Workloads oder die Benachrichtigung bei Erreichen von Schwellwerten oder der Feststellung von Anomalien.
Da man seine Anwendungen nicht rund um die Uhr selbst überwachen kann, ist es nicht nur hilfreich Alarme zu erstellen, die zum Beispiel durch Schwellwerte ausgelöst werden, sondern auch benachrichtigt zu werden. Amazon Simple Notification Service (Amazon SNS) ist ein Service durch den Nachrichten zugestellt werden können. Ein Produzent bereitet eine Nachricht vor und sendet diese an ein bestimmtes Thema (Topic) in Amazon SNS. Die Konsumenten, die dieses Thema abonniert haben, können die Nachricht lesen. Das Zusenden kann an eine E-mail oder SMS oder an andere AWS Services erfolgen. Der Versand und das Lesen der Nachricht erfolgt asynchron, da die Nachricht vom Konsumenten nicht sofort gelesen werden muss.
Anwendung
Logfiles der ToDo-App
Während der Konfiguration der Task Definition für die Front- und Backend Container wurden die Log Groups für die Sammlung der Container Logs in CloudWatch Logs bereits konfiguriert.
- Unter Services den Dienst CloudWatch auswählen.
- Links im Menü unter Logs auf Log groups klicken.
- Die beiden Log groups für die Front- und Backend Container sind unter
/ecs/workshop-frontendund/ecs/workshop-backendchronologisch aufgeführt. - Über Filter können spezifische Events z.B. für die Fehlersuche herausgefiltert werden.
Die gesammelten Log files können jedoch auch noch weiter verarbeitet werden. So lassen sich diese z.B. an weitere Empfänger schicken (z.B. Elasticsearch oder Lambda) und somit Automatisierungen realisieren, die beim Erhalt gewisser Nachrichten eine Aktion ausführen.
Je nach Applikation und deren Konfiguration können hier gewisse Log Outputs ausgegeben werden.
Service Monitoring
Viele AWS Services bieten ein Monitoring direkt im Kontext des jeweiligen Dienstes an. Das ist besonders dann hilfreich, wenn man schnell und unkompliziert die wichtigsten Werte des Services analysieren möchte. Im Folgenden sind zwei Beispiele aufgeführt, die das veranschaulichen.
RDS Metriken
- Unter Services den Dienst RDS auswählen.
- Links im Menü auf Databases und danach auf
workshop-dbklicken. - Im Tab Monitoring sind die Metriken wie z.B. CPU Utilization, Anzahl der DB Verbindungen, Storage- und Memory-Auslastung, IOPS etc. auf einen Blick sichtbar und könnten auch mit anderen DB Instanzen vergleichen werden.
Load Balancer Metriken
- Unter Services den Dienst EC2 auswählen.
- Links im Menü unter Load Balancing auf Load Balancers klicken.
- Den Load Balancer
todoAppauswählen. - Im Tag auf Monitoring klicken.
Hier werden nun die wichtigsten Metriken (wie z.B. die Antwortzeiten, Anzahl der Requests, HTTP Error Codes etc.) auf einen Blick dargestellt.
Alarmierung
Bevor der Alarm eingestellt werden kann, muss definiert werden, wie man alarmiert wird, wenn der Alarm ausgelöst wird.
- Unter Services den Dienst Simple Notification Service auswählen.
- Links im Menü Topics auswählen und auf Create topic klicken.
- Wähle Standard als Type aus und gebe Thema den Namen
todotopic. - Klicke auf Create topic.
- Optional: Nun ist es möglich beispielsweise die eigene Email als Subscription zu hinterlegen. Diese muss, bevor sie genutzt werden kann, bestätigt werden.
Nun kann der Alarm selbst erstellt werden.
- Unter Services den Dienst EC2 auswählen.
- Links im Menü links unter Load Balancers
todoAppauswählen. - Klicke auf das Tab Monitoring und klicke bei HTTP 4XXs auf die drei Punkte rechts oben.
- Klicke auf View in metrics und es öffnet sich ein neues Fenster mit dieser Metrik in CloudWatch.
- In der Zeile, wo das Label
todoApp, die Details, die Statistik und weiteres aufgeführt sind, klicke auf die Klingel, um einen Alarm zu erstellen. HTTP 4XXs ist die Metrik, die evaluiert werden soll. - Stelle Period auf
5 Minuten. - Nun stellen wir die Schwelle ein, bei der der Alarm getriggert wird. Setze die Schwelle auf 3.
- Klicke auf additonal configuration und stelle 3 out of 15 Datenpunkte ein. Das bedeutet, wenn innerhalb von 5 Minuten 3 von 15 Datenpunkten höher als die Schwelle sind, dann wird der Alarm getriggert. Klicke auf Next.
- Wähle
todotopicals Amazon SNS Topic aus und klicke auf Next. - Benenne den Alarm
404-Errorund klicke auf create alarm.
Nun kannst du den Alarm auch selbstständig testen. Wenn du noch die Anwendung offen hast, kannst du zu deinem Link /diese_url_existiert_nicht hinzufügen. Da diese Seite nicht existiert, wirst du eine Fehlermeldung bekommen. Jetzt rufe den fehlerhaften Link mehrmals auf, um den Alarm zu triggern. Dein Alarm müsste in Alarm sein. Sobald mehr als 5 Minuten vergangen sind, wo keine 3 Datenpunkte von 15 den Fehlercode auslösen, dann wird der Alarm wieder in den OK-State zurückkehren.
Zentrales Dashboard
Wie die beiden letzten Beispiele des Load Balancers sowie der RDS Instanz gezeigt haben kommen die Metriken, welche im Kontext der einzelnen Services angezeigt werden, bereits aus CloudWatch. Mithilfe dieser Informationen ist es ebenfalls möglich einen oder mehrere Alarme zu definieren welche beim Überschreiten von Schwellwerten ausgelöst werden.
Für die Überwachung der gesamten Applikationsumgebung können die einzelnen Metriken innerhalb von CloudWatch auf einem zentralen Dashboard angezeigt werden, denn oftmals haben die Auswirkungen z.B. eines Anstiegs der Auslastung einer Applikation einen Einfluss auf andere Bereiche der gesamten Infrastruktur. So müssen z.B. die Container Instanzen skaliert werden, wenn die Requests des Load Balancers stark ansteigen und dadurch die Antwortzeiten der Anwendung steigen. Wenn der Zustand bestehen bleibt wird wohl über längere Zeit hin auch die Datenbank Instanz mehr Ressourcen benötigen bevor diese zum Bottleneck wird. Zuerst einmal ist es also wichtig, einen Gesamtüberblick zu erhalten. Dies ist am einfachsten über ein zentrales Dashboard zu realisieren.
Danach können z.B. Schwellwerte definiert und eine automatische Benachrichtigung eingerichtet werden. Es ist daneben auch möglich, zusätzlich zur Benachrichtigung automatisierte Schritte zu definieren welche in einem Alarm-Fall ausgeführt werden. Hierdurch sinkt der manuelle Aufwand erheblich und es kann schneller auf Systemzustände reagiert werden. Ein sehr gutes Verständnis über das Systemverhalten ist jedoch Voraussetzung um Aktionen anschliessend gezielt automatisieren zu können.
Dashboard einrichten
Um besser den Überblick zu behalten, erstellst du nun ein Dashboard. Es gibt verschiedene Darstellungsweisen für die Metriken, welche nun teilweise genutzt werden sollen. Dein Dashboard kann am Ende beispielsweise so aussehen, aber du kannst dieses frei gestalten.
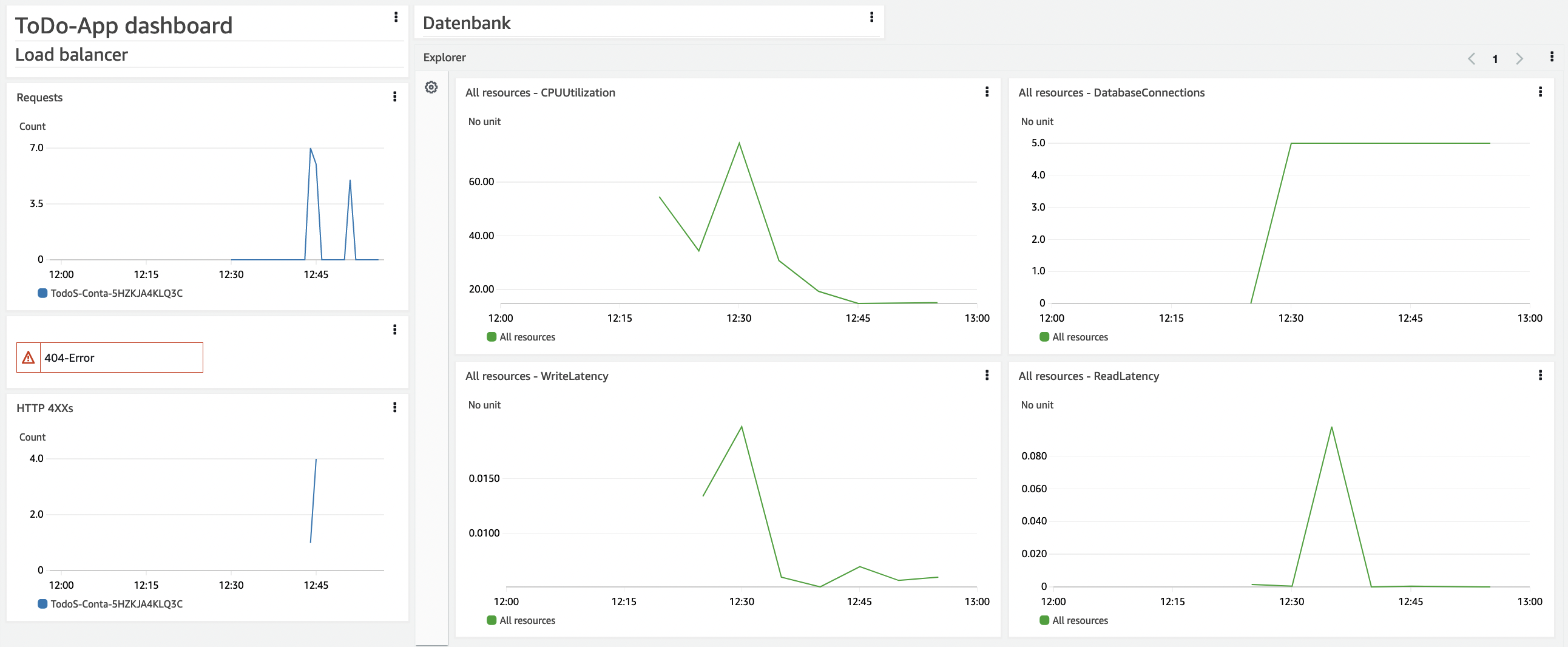
- Unter Services den Dienst CloudWatch auswählen.
- Links im Menü auf Dashboards klicken und benenne dein Dashboard
ToDo-App-Dashboard. - Klicke auf der rechten Seite auf Create dashboard.
- Füge ein neues Text Widget hinzu. Gib deinem Dashboard die Übeschrift
ToDo-App Dashboard. Du kannst auch weitere Titel oder Untertitel je nach Bedarf einfügen. - Klicke oben rechts auf Save, um die erste Änderung zu speichern.
Füge nun zwei Metriken für deinen Load Balancer hinzu.
- Unter Services den Dienst EC2 auswählen.
- Links im Menü links unter Load Balancers in der Liste auf
todoAppklicken. - Klicke auf das Tab Monitoring und klicke bei HTTP 4XXs auf die drei Punkte rechts oben.
- Klicke auf View in metrics und es öffnet sich ein neues Fenster mit dieser Metrik in CloudWatch.
- Klicke rechts oben auf Actions und auf Add to dashboard. Wähle dein
ToDo-App Dashboardaus. Nun hast du deine erste Metrik zum Dashboard hinzugefügt. Du kannst diese durch Drag-and-Drop richtig positionieren. - Führe nun Schritt 3-5 für die Metrik Requests aus. Nun hast du auch die Metrik Requests zu deinem Dashboard hinzugefügt.
- Klicke oben rechts auf Save, um die die Änderungen zu speichern.
Nun fügen wir den bereits erstellten Alarm hinzu.
- Klick auf das Plus rechts oben im Dashboard.
- Wähle Alarm status und setze einen Hacken für deinen Alarm
404-Errorund bestätige mit Create widget.. - Wähle dein Dashboard
ToDo-App Dashboardaus, um den Alarm hinzuzufügen und bestätige mit Add to dashboard. - Durch Drag-and-Drop kannst du selbst festlegen, wo dein Alarm positioniert sein soll.
- Klicke oben rechts auf Save, um die Änderung zu speichern.
Erstelle deine erste Übersicht für die Datenbank:
- Klick auf das Plus rechts oben im Dashboard.
- Wähle Explorer und Empty Explorer widget.
- Suche nach RDS und wähle vier Metriken wie zum Beispiel CPU-Utilization aus.
- Wähle als Ressource unter FROM die Datenbank mit dem Tag
Name:todoapp. - Nun kannst du selbst auswählen wie die Aggregation aussehen soll.
- Klicke oben rechts auf Save, um den hinzugefügten Explorer zu speichern.
Visualisiere eine Metrik mit der Darstellung deiner Wahl. Es kann eine Metrik zu deiner Datenbank workshop-db sein, zum Load Balancer todoApp oder zu deinem Container Cluster workshop-cluster. Dadurch kannst du dir die wichtigsten Metriken für dich zusammenstellen und so die ganze Anwendung einfacher überwachen.
Zusammenfassung und nächste Schritte
Herzlichen Glückwunsch! Du hast erfolgreich ein eigenes Dashboard für dein Monitoring eingerichtet und einen Überblick bekommen, welche Metriken beobachtet werden können. Im nächsten Kapitel geht es darum Backups zu erstellen.