Datenbanken sind seit Jahrzehnten zentrale Komponenten von IT-Systemen. Sie erlauben die dauerhafte Speicherung von strukturierten und unstrukturierten Informationen. Die Konfiguration und der Betrieb einer Datenbank erfordern häufig Expertenwissen. Datenbank-Administratoren (DBA) kümmern sich traditionell um diese Themen.
Zwei grundsätzliche Entwicklungen konnten in den letzten Jahren bei Datenbanken beobachtet werden:
Wie bei fast allen technologischen Entwicklungen gibt es nicht nur Vorteile, sondern ebenfalls auch Nachteile und Herausforderungen. Ein zentraler Aspekt für Unternehmen ist sicherlich das erforderliche, und unterschiedliche Datenbank Know-How aufzubauen und zu bewahren. Mit einer gestiegenen Anzahl unterschiedlich unterstützter Datenbank-Technologien wächst häufig auch die Anzahl benötigter Mitarbeiter, um diese ordnungsgemäss zu konfigurieren und zu betreiben.
Datenbanken verfügen über eine Vielzahl an unterschiedlichen technischen Konzepten. Da dieser Kurs kein Datenbank-Kurs ist, werden die technischen Konzepte nicht im Detail erklärt. Stattdessen wird dieser Abschnitt die für den Cloud-Kontext relevanten technischen Aspekte erklären.
Werden Datenbanken in der Cloud verwendet, so gibt es je nach genutzten Service zwei grundsätzliche Modelle. Entweder basiert der Service auf einem serverbasierten Ansatz oder aber auf einem serverlosen Ansatz. Eines vorweg, in beiden Modellen laufen die Datenbank immer noch auf Servern. Der Unterschied für Cloud-Nutzer ist, dass ihr euch bei einem serverbasierten Ansatz Gedanken machen müsst über wie viele Ressourcen (CPU, Memory, …) der Datenbank-Server verfügen soll und wo (in welcher Availability Zone) sich dieser befinden soll. Bei einem serverlosen Ansatz fällt dieser Aufwand komplett weg und stattdessen geben User dieser Services eher an wie viele Lese- und Schreiboperation die Datenbank unterstützen soll. Daneben sind serverlose Services so konzipiert, dass sie mit der entsprechenden Last skalieren können, sprich im Hintergrund können mehr oder weniger Ressourcen automatisch zur Verfügung gestellt werden. Eine Konsequenz aus dieser automatischen Skalierung sind die Kosten, welche für den Service anfallen. Gibt es wenig Last, so sind diese gering und wird eine hohe Last abgearbeitet so steigen entsprechend die Kosten.
Die Themen Skalierbarkeit und Verfügbarkeit müssen bei einem serverbasierten Ansatz stärker betrachtet und ggf. aktiviert werden. Soll z.B. der Datenbank-Server nicht nur in einer Availability Zone, sondern noch in einer weiteren Availability Zone laufen, um ein hochverfügbares Setup zu haben, so sind die entsprechenden Optionen für den jeweiligen Service auszuwählen. Ähnlich sieht es aus, wenn es neben dem einzelnen Datenbank-Server noch weitere Datenbank-Server geben soll um z.B. eine grosse Menge an lesenden Anfragen zu bewältigen. Dies muss ebenfalls vom Kunden konfiguriert werden.
Innerhalb von AWS gibt es unterschiedliche Möglichkeiten Datenbanken zu nutzen. Neben der klassischen Möglichkeit Datenbanken selber in AWS zu verwalten, analog zum Muster wie dies Unternehmen in eigenen Rechenzentren machen, erlaubt es AWS ebenfalls eine Vielzahl unterschiedlicher Datenbank-Typen als von AWS verwaltete Services (Managed Services) zu nutzen. Durch die Nutzung von Managed Services wird der Aufwand für die Nutzung dieser Services für Unternehmen deutlich vereinfacht, da typische Administrationsaufgaben von AWS übernommen werden und automatisiert sind.
AWS bietet über 10 unterschiedliche Datenbank-Services an und in der Folge sollen nur die wichtigsten Services kurz beschrieben werden:
Amazon RDS: RDS steht für Relational Database Service und erlaubt es sowohl kommerzielle (Oracle, Microsoft) als auch Open-Source basierte Datenbanken (MySQL, PostgreSQL) als Managed Services von AWS zu beziehen. Es handelt sich bei allen Produkten um relationale Datenbanken, die über einen serverbasierten Ansatz zur Verfügung gestellt werden.
Amazon DynamoDB: Hierbei handelt es sich um eine NoSQL-Datenbank bei der zu einem eindeutigen Schlüssel mehrere Attribute (Spalten) persistiert werden. Typische Anwendungsfälle für DynamoDB sind hochfrequentierte Webanwendungen oder Spiele, die Antwortzeiten im einstelligen Millisekundenbereich benötigen. DynamoDB ist eine Implementierung eines serverlosen Datenbank-Service.
Amazon ElastiCache: Die Verwendung von Caches erlaubt es Informationen direkt aus dem Memory zurückzugeben und nicht diese erst über eine Datenbankabfrage zu erhalten. Über diesen Ansatz lassen sich Antworten im Mikrosekundenbereich erzielen, und typische Anwendungsfälle sind z.B. das Sitzungs-Management von Online-Shops (Einträge in einem Warenkorb).
Amazon Redshift: Eine weitere wichtige Kategorie zum Speichern und Verwalten von grossen Datenmengen sind Data Warehouses (DWH). Der Fokus dieser Systeme liegt auf analytische Aspekte und Nutzer von Data Warehouses versuchen neue Erkenntnisse aus einer Vielzahl von unterschiedlichen Datenquellen zu erhalten. Amazon Redshift ist das schnellste und am häufigsten verwendete Cloud Data-Warehouse weltweit.
Der Betrieb unserer Datenbank als Managed Service von AWS macht Sinn, da bereits viele Themen wir z.B. Skalierbarkeit, Monitoring, Backup & Recovery und Hochverfügbarkeit einfach aktiviert werden können. Benutzer müssen sich nicht wie sonst um die Installation einer virtuellen Maschine, der Datenbank-Engine oder dem Einspielen von Updates kümmern.
In der Beispielanwendung wird die Ablage der Daten in einer Datenbank vorgenommen. Durch diese Separation können alle Ebenen der Anwendung (Front- und Backend sowie Datenbank) abhängig von ihrer Auslastung skaliert werden.
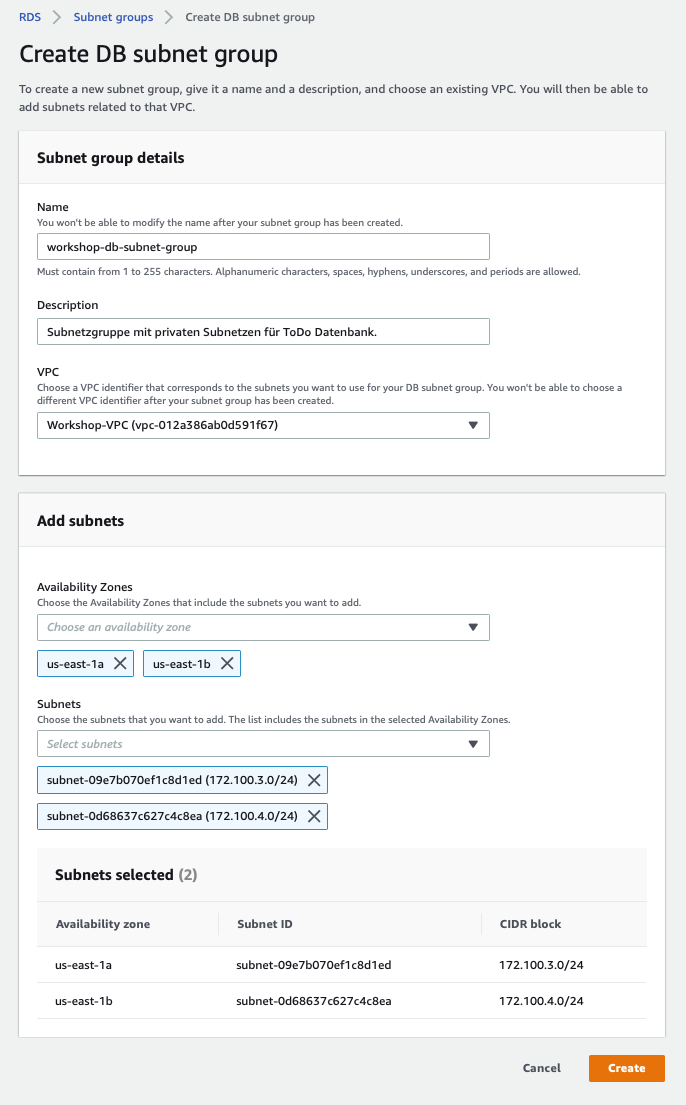
Eine Subnetzgruppe definiert in welche Subnetzen Amazon RDS eine Datenbank platzieren darf.
Aufgabe:
Erstelle eine Amazon RDS Subnetzgruppe (engl. Subnet Group) mit dem Namen workshop-db-subnet-group. Konfiguriere die Subnetzgruppe, sodass sie die beiden privaten Subnetze 172.100.3.0/24 und 172.100.4.0/24 aus den Availability Zonen us-east-1a und us-east-1b enthält.
Aufgabe:
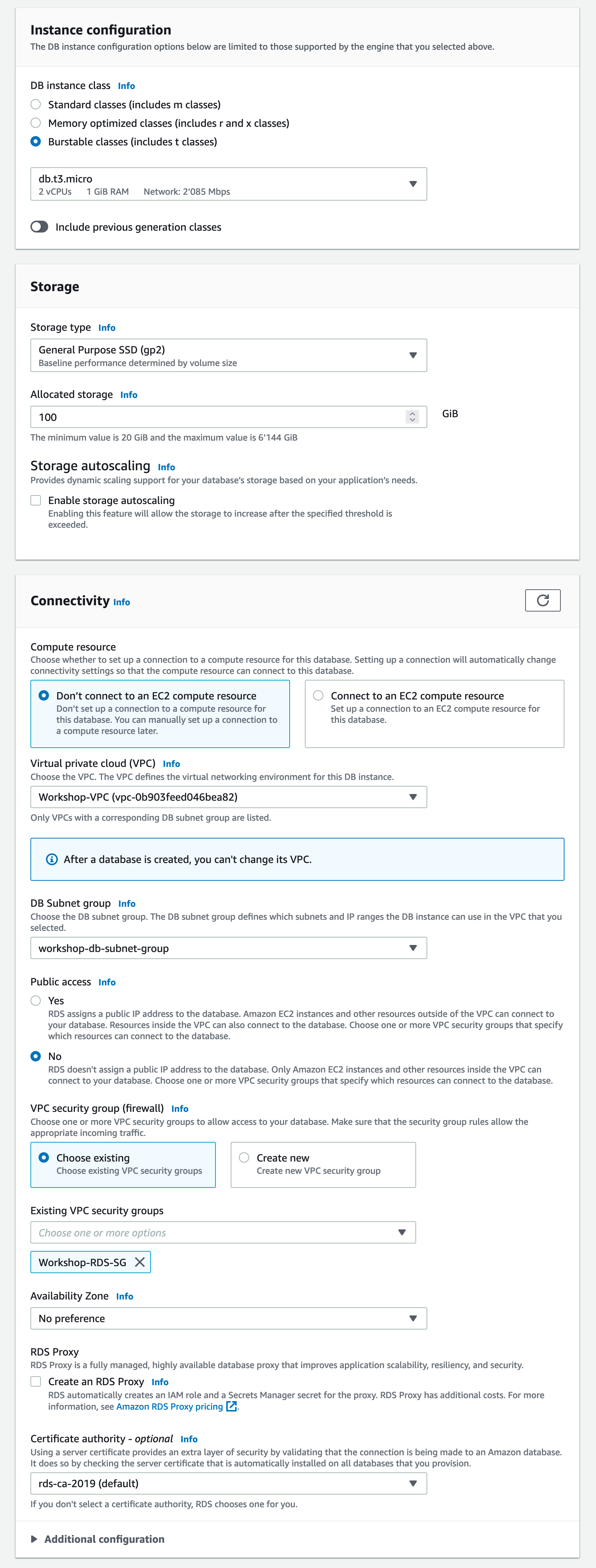
Erstelle eine eigene Amazon RDS Datenbank mit dem Namen workshop-db. Die Datenbank soll als Datenbankengine MySQL 8.0.35 benutzen.
Da diese Applikation nicht produktionsfähig sein muss kannst du Kosten sparen indem du die Datenbank als Dev/Test Datenbank erstellst. Damit wir später ein Failover testen können, nutze die Multi-AZ DB instance. Wähle den burstable Typ db.t3.micro aus und deaktiviere storage autoscaling.
Die Datenbank soll in der zuvor erstellten Subnetzgruppe mit dem Namen workshop-db-subnet-group platziert werden. Für die Security Gruppe soll Workshop-RDS-SG ausgewählt werden. Diese Security Gruppe erlaubt nur Netzwerkverbindungen von den Servern die die Applikation ausführen.
Außerdem musst du sicherstellen, dass sich die Applikation mit dem Master usernameclusteradmin und dem Master password todopassword bei der Datenbank authentifizieren/anmelden kann.
Aus Sicherheitsgründen sollten Passwörter selbstverständlich niemals in einer solchen Form dokumentiert werden! Obwohl die Zugangsdaten hier im Klartext dokumentiert sind, wird später der Zugriff auf die Datenbank nur von den Container Instanzen her möglich sein. Zudem wird die Datenbank NICHT über das Internet erreichbar sein. Anstatt nun den Benutzernamen sowie das Passwort zu notieren könnte diese z.B. in AWS Secrets Manager abgelegt werden.
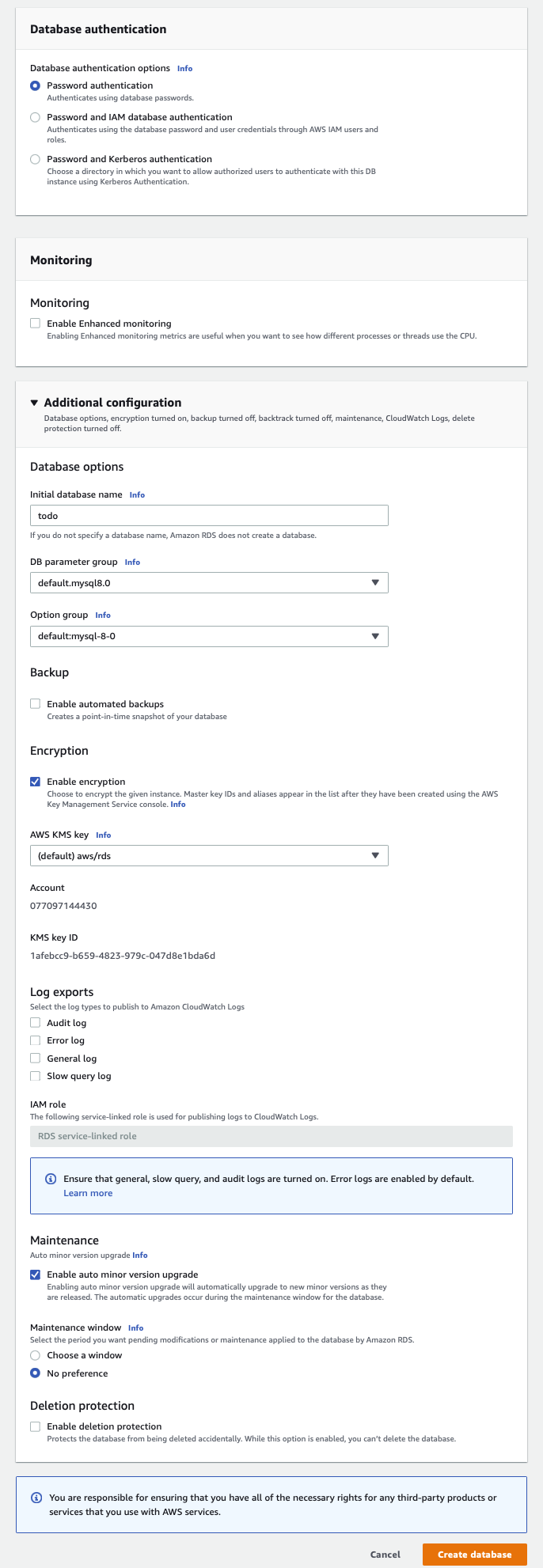
Finde die zwei letzten Einstellungen, definiere den initialen Datenbanknamen als todo und schalte automatische Backups aus.
Kannst du die Einstellung für Verschlüsselung finden? Wie du siehst, ist Verschlüsselung automatisch für Amazon RDS angeschaltet. Amazon RDS benutzt die im Kapitel zur Verschlüsselung server-side encryption Methode zur Verschlüsselung der Daten in Rest. Sollte ein Angreifer die Datenbank hacken, kann dieser nicht die Daten ohne den Schlüssel lesen. Somit hilft die Amazon RDS Voreinstellung das Best Practice Verschlüsselung zu nutzen. Diese Einstellung sollte also unbedingt angeschaltet bleiben.
Bevor du auf Create database klickst solltest du deine Konfiguration mit den folgenden Screenshots vergleichen: Screenshot 1, Screenshot 2, und Screenshot 3. Die Datenbank hat viele Einstellungen und manche Einstellungen sind nach der Provisierung fest, sodass diese korrekt sein sollten, damit die ToDo-App später funktioniert.
Das Setup kann einige Minuten in Anspruch nehmen. Der Status kann in der AWS Console verfolgt werden. Für die Beispielanwendung ist die ausgewählte Datenbank-Instanz vollkommen ausreichend. Wenn sich die Anforderungen an die zur Verfügung stehenden Ressourcen ändern, kann die Instanzgrösse später im Betrieb während eines Maintenance Windows jederzeit geändert werden.
Der DNS Name wird später für die Verbindung der Backend Container Instanzen benötigt. Daher am besten gleich über die Zwischenablage in ein Textfile kopieren und dort zusätzlich den Datenbank Benutzernamen sowie das Passwort (siehe oben) notieren.
Name und value todoapp in dem Tags Tab.Herzlichen Glückwunsch! Du hast eine relationale Datenbank (Amazon RDS Instanz) erstellt, die als Speicher für die ToDos dienen wird. Die Instanz ist nicht öffentlich erreichbar und wurde im Workshop VPC gestartet. Durch die verknüpfte Security Group Workshop-RDS-SG kann die Datenbank lediglich von Ressourcen erreicht werden, die von der Workshop-ECS-SG aus kommen.
Im nächsten Schritt wird ein Load Balancer, der die Anfragen from Frontend auf dem Backend verteilt, erstellt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}