sample-aiml-security-assessment
AI/ML Security Assessment Framework - Developer Guide
Table of Contents
- Architecture Overview
- Assessment Structure
- Adding New AI/ML Service Assessments
- Assessment Best Practices
- Testing Your Extensions
- Monitoring and Debugging
- Development Roadmap
- Report Generation Architecture
- Documentation and Screenshots
- CI/CD Workflows
- Support and Resources
Architecture Overview
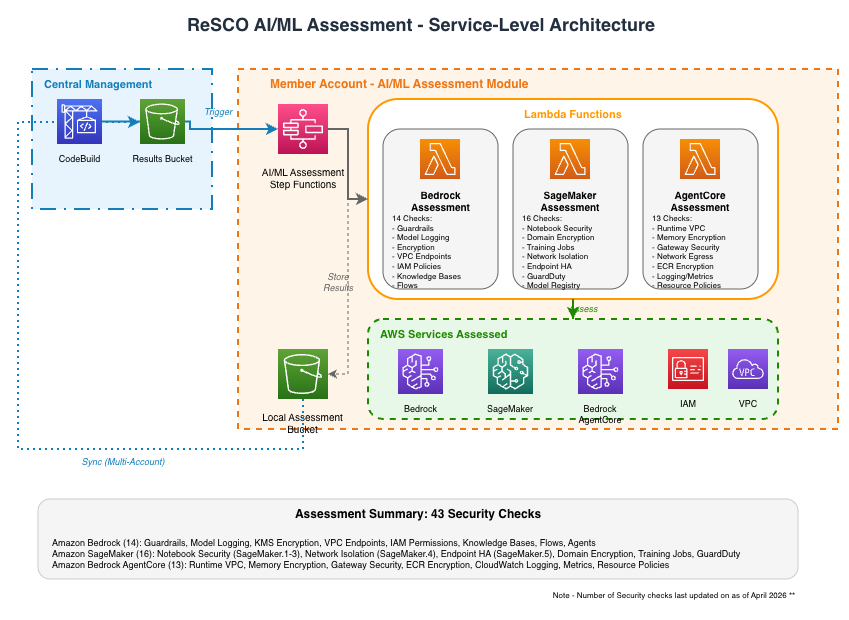
The AI/ML Security Assessment Framework is a serverless, multi-account security assessment solution for AWS AI/ML workloads. It performs 52 core security checks across Amazon Bedrock, Amazon SageMaker AI, and Amazon Bedrock AgentCore, with an optional 64-check Financial Services GenAI risk assessment, generating interactive HTML reports with findings and remediation guidance.
Security Design Principles
- Runtime assessment Lambda roles are read-oriented and scoped to the APIs needed by each assessment
- AWS CodeBuild and member-account roles require deployment permissions because they create or update the SAM assessment stacks before running checks
- Cross-account trust is limited to the specific AWS CodeBuild role in the central assessment account
- Amazon S3 buckets enforce SSL-only access
- Assessment data is encrypted in transit and at rest
- No persistent credentials are stored in AWS CodeBuild
Architecture Diagrams
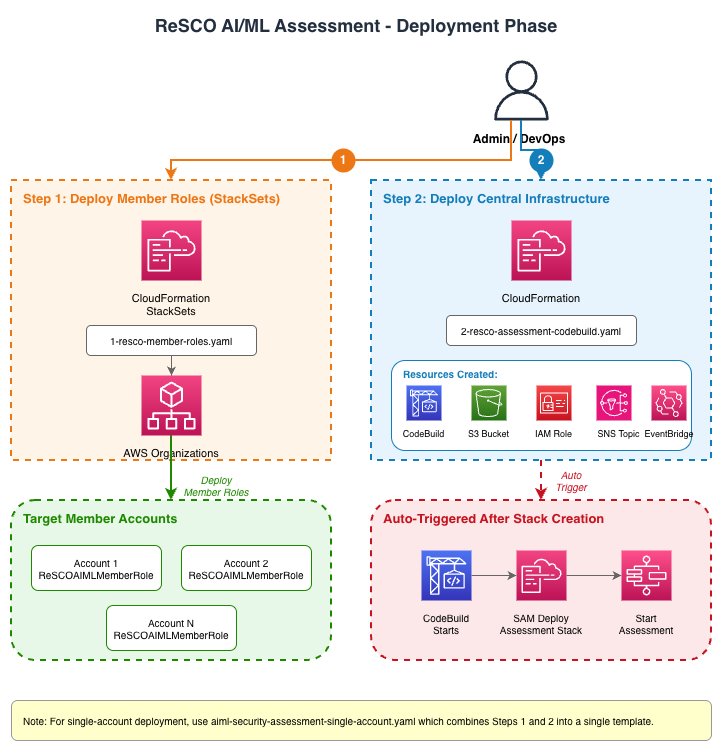
Phase 1: Deployment Setup (AWS CloudFormation)
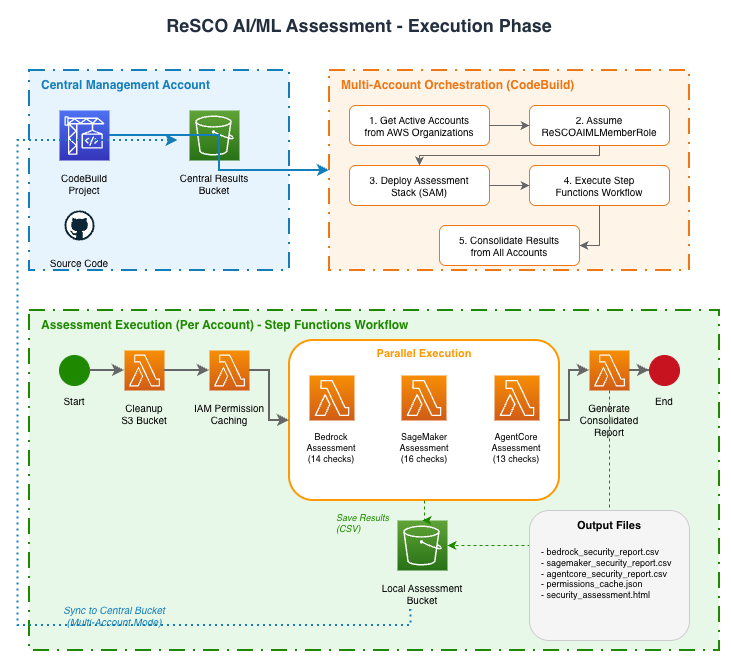
Phase 2: Assessment Execution (AWS CodeBuild)
Service-Level Assessment Architecture
Two-Phase Architecture
Phase 1: Infrastructure Deployment
Step 1: Member Account Roles (1-aiml-security-member-roles.yaml)
- AWS CloudFormation StackSets Deployment: Deploys
AIMLSecurityMemberRoleto all target accounts - Cross-Account Trust: Establishes trust relationship with the central assessment account
- Assessment and Deployment Permissions: Grants read-oriented service permissions for assessment checks and deployment permissions needed for CodeBuild to create or update per-account SAM stacks
Step 2: Central Infrastructure (2-aiml-security-codebuild.yaml)
- AWS CodeBuild Project: Orchestrates multi-account deployments and assessments
- Amazon S3 Bucket: Central storage for consolidated assessment results
- AWS IAM Role:
MultiAccountCodeBuildRolewith cross-account access permissions - Amazon SNS Topic: Optional email notifications for assessment completion
- Amazon EventBridge Rules: Automated workflow triggers
- AWS Lambda Trigger: Automatically starts AWS CodeBuild after stack creation
Phase 2: Assessment Execution (AWS CodeBuild Orchestration)
AWS CodeBuild Execution Flow
- Account Discovery: In multi-account mode, lists active accounts from AWS Organizations or uses
MultiAccountListOverride - Role Assumption: In multi-account mode, assumes
AIMLSecurityMemberRolein each target account - AWS SAM Deployment: Deploys or updates the AI/ML assessment stack through AWS SAM
- Assessment Execution: Triggers AWS Step Functions workflow in each account, passing
enableFinServfrom the deployment parameter - Results Consolidation: Syncs per-account reports to the infrastructure bucket and creates a consolidated report for multi-account runs
Project Structure
sample-aiml-security-assessment/
├── aiml-security-assessment/
│ ├── functions/security/
│ │ ├── bedrock_assessments/ # Bedrock security checks (14)
│ │ ├── sagemaker_assessments/ # SageMaker security checks (25)
│ │ ├── agentcore_assessments/ # AgentCore security checks (13)
│ │ ├── finserv_assessments/ # Optional Financial Services GenAI risk checks (64)
│ │ ├── finserv_tests/ # FinServ-specific unit and coverage tests
│ │ ├── iam_permission_caching/ # AWS IAM permissions cache
│ │ ├── cleanup_bucket/ # Amazon S3 cleanup
│ │ ├── resolve_regions/ # Multi-region resolution Lambda
│ │ └── generate_consolidated_report/ # HTML/CSV report generation
│ ├── statemachine/ # AWS Step Functions definition
│ ├── images/ # SAM application images
│ ├── template.yaml # AWS SAM template (single-account)
│ ├── template-multi-account.yaml # AWS SAM template (multi-account)
│ ├── samconfig.toml # SAM deployment configuration
│ ├── envvars.json # Environment variables for local testing
│ └── testfile.json # Test event file for local invocation
├── deployment/ # AWS CloudFormation templates
├── docs/ # Documentation
│ ├── DEVELOPER_GUIDE.md # This guide
│ ├── SECURITY_CHECKS.md # Security checks reference
│ ├── TROUBLESHOOTING.md # Troubleshooting guide
│ ├── diagrams/ # Architecture diagrams
│ └── icons/ # AWS service icons
├── sample-reports/ # Sample assessment reports
│ ├── scripts/ # Screenshot capture scripts
│ ├── *.html # Sample HTML reports
│ └── *.png # Report screenshots
├── tests/ # Unit tests for assessment functions
│ └── requirements.txt # Test dependencies
├── .github/workflows/ # PR lint, test, SAM validate, and security scans
├── buildspec.yml # AWS CodeBuild orchestration
└── consolidate_html_reports.py # Multi-account report consolidation
Member Account Resources (Deployed by AWS SAM)
- AWS SAM Application: AI/ML security assessment stack
- AWS Step Functions: Single workflow orchestrating all assessments
- AWS Lambda Functions: One per core service (Amazon Bedrock, Amazon SageMaker AI, Amazon Bedrock AgentCore), one FinServ assessment Lambda invoked only when enabled, plus utilities
- Local Amazon S3 Bucket: Storage for account-specific results
Assessment Execution Workflow
AWS CodeBuild Orchestration
# buildspec.yml execution flow
1. Get active accounts from AWS Organizations
2. For each account:
- Assume AIMLSecurityMemberRole
- Deploy AI/ML assessment stack through AWS SAM
- Start AWS Step Functions execution
3. Wait for completion and consolidate results
AWS Step Functions (Per Module)
{
"Comment": "AI/ML Assessment Module",
"StartAt": "Cleanup S3 Bucket",
"States": {
"Cleanup S3 Bucket": {
"Type": "Task",
"Next": "IAM Permission Caching"
},
"IAM Permission Caching": {
"Type": "Task",
"Next": "Resolve Target Regions"
},
"Resolve Target Regions": {
"Type": "Task",
"Comment": "Resolves target regions from TARGET_REGIONS env var",
"Next": "Scan Regions"
},
"Scan Regions": {
"Type": "Map",
"ItemsPath": "$.ResolvedRegions.regions",
"MaxConcurrency": "${MaxRegionConcurrency}",
"ItemProcessor": {
"ProcessorConfig": {"Mode": "INLINE"},
"StartAt": "Run Security Assessments",
"States": {
"Run Security Assessments": {
"Type": "Parallel",
"Branches": [
{"StartAt": "Bedrock Security Assessment", "States": {...}},
{"StartAt": "Sagemaker Security Assessment", "States": {...}},
{"StartAt": "AgentCore Security Assessment", "States": {...}},
{
"StartAt": "FinServ Enabled?",
"States": {
"FinServ Enabled?": {
"Type": "Choice",
"Comment": "Runs FinServ only when enableFinServ is true and RegionIndex is 0"
},
"FinServ Security Assessment": {"Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "End": true},
"FinServ Assessment Skipped": {"Type": "Pass", "End": true}
}
}
],
"End": true
}
}
},
"Next": "Generate Consolidated Report"
},
"Generate Consolidated Report": {
"Type": "Task",
"End": true
}
}
}
Assessment Structure
The framework includes 52 core security checks across three AI/ML services, plus 64 optional Financial Services GenAI risk checks when EnableFinServAssessment is enabled. For the complete list of checks with descriptions, see the Security Checks Reference.
AWS Lambda Functions
Each core service assessment AWS Lambda function:
- Receives execution context and target region from AWS Step Functions (via the Map state)
- Verifies the service is available in the target region (returns N/A finding if not)
- Reads cached AWS IAM permissions from Amazon S3
- Creates regional boto3 clients with explicit
region_nameparameter - Performs security checks against AWS APIs in the target region
- Generates CSV report with findings (includes
Regioncolumn) - Uploads results to Amazon S3 with region-suffixed filename
- Returns findings summary to AWS Step Functions
The Financial Services assessment Lambda is different. It is deployed in both SAM templates, but Step Functions invokes it only when the execution input includes "enableFinServ": "true" and only from the first region iteration (RegionIndex == 0). It receives the full TargetRegions list and emits FinServ findings with Region values so the report can display the same regional filters as the core services.
Additional Functions:
- AWS IAM Permission Caching: Pre-fetches AWS IAM policies to optimize assessment (global, runs once)
- Cleanup Bucket: Removes old assessment data
- Resolve Regions: Resolves target regions from
TargetRegionsparameter for the Map state - Generate Consolidated Report: Creates HTML report from CSV findings with region filtering
Adding New AI/ML Service Assessments
To add a new AI/ML service (for example, Amazon Comprehend, Amazon Textract):
Step 1: Create Service Assessment Function
- Create Function Directory (One function per service):
# Example: Adding Comprehend security assessment mkdir -p aiml-security-assessment/functions/security/comprehend_assessments cd aiml-security-assessment/functions/security/comprehend_assessments - Create Function Files:
```python
app.py
import boto3 import os import json from botocore.config import Config from botocore.exceptions import ClientError, EndpointConnectionError from schema import create_finding
boto3_config = Config(retries=dict(max_attempts=10, mode=”adaptive”))
def lambda_handler(event, context): “"”Main assessment handler for new service””” all_findings = []
# Extract target region from Step Functions Map state
region = event.get("Region", os.environ.get("AWS_REGION", "us-east-1"))
# Verify service availability in this region
try:
test_client = boto3.client("comprehend", config=boto3_config, region_name=region)
test_client.list_endpoints(MaxResults=1)
except (EndpointConnectionError, Exception) as e:
if "Could not connect to the endpoint URL" in str(e):
# Service not available — return N/A finding
...
return {"statusCode": 200, "body": {"message": f"Service not available in {region}"}}
# Get cached permissions
execution_id = event["Execution"]["Name"]
permission_cache = get_permissions_cache(execution_id)
# Run assessment checks (pass region to each)
findings = check_new_service_security(permission_cache, region=region)
all_findings.append(findings)
# Generate and upload report (include region in S3 key)
csv_content = generate_csv_report(all_findings)
bucket_name = os.environ.get("AIML_ASSESSMENT_BUCKET_NAME")
s3_url = write_to_s3(execution_id, csv_content, bucket_name, region=region)
return {
"statusCode": 200,
"body": {
"message": "New service assessment completed",
"findings": all_findings,
"report_url": s3_url,
},
}
def check_new_service_security(permission_cache, region: str = “”): “"”Implement your security checks here””” findings = { “check_name”: “New Service Security Check”, “status”: “PASS”, “details”: “”, “csv_data”: [], }
# Create regional client
client = boto3.client("comprehend", config=boto3_config, region_name=region)
# Your assessment logic here
# Pass region= to all create_finding() calls
return findings ```
- Create Requirements File:
# requirements.txt boto3>=1.26.0 botocore>=1.29.0 - Create Schema File:
```python
schema.py
from enum import Enum
class SeverityEnum(str, Enum): HIGH = “High” MEDIUM = “Medium” LOW = “Low” INFORMATIONAL = “Informational”
class StatusEnum(str, Enum): FAILED = “Failed” PASSED = “Passed” NA = “N/A”
def create_finding( check_id, finding_name, finding_details, resolution, reference, severity, status, region=”” ): “"”Create standardized finding format
Args:
check_id: Unique check identifier (for example, SM-01, BR-01, AC-01)
finding_name: Name of the finding
finding_details: Detailed description
resolution: Steps to resolve (empty string for N/A status)
reference: Documentation URL
severity: SeverityEnum value
status: StatusEnum value (Failed, Passed, or N/A)
region: AWS region where the finding was identified
"""
return {
"Check_ID": check_id,
"Finding": finding_name,
"Finding_Details": finding_details,
"Resolution": resolution,
"Reference": reference,
"Severity": severity,
"Status": status,
"Region": region,
} ```
Step 2: Update AWS SAM Template
Add your new function to both SAM templates:
aiml-security-assessment/template.yamlaiml-security-assessment/template-multi-account.yaml
ComprehendSecurityAssessmentFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub 'aiml-security-${AWS::StackName}-ComprehendAssessment'
CodeUri: functions/security/comprehend_assessments/
Handler: app.lambda_handler
Runtime: python3.12
Timeout: 600
MemorySize: 1024
Environment:
Variables:
AIML_ASSESSMENT_BUCKET_NAME: !Ref AIMLAssessmentBucket
TARGET_REGIONS: !Ref TargetRegions
Policies:
- S3CrudPolicy:
BucketName: !Ref AIMLAssessmentBucket
- Statement:
- Sid: ComprehendReadPermissions
Effect: Allow
Action:
- comprehend:List*
- comprehend:Describe*
- comprehend:Get*
Resource: '*'
Step 3: Update AWS Step Functions Definition
Add the new service to the Run Security Assessments parallel branch inside the Scan Regions Map state in aiml-security-assessment/statemachine/assessments.asl.json. Also add the function ARN substitution and LambdaInvokePolicy for the new function in both SAM templates.
{
"Parallel Service Assessments": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Bedrock Security Assessment",
"States": {"Bedrock Security Assessment": {"Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "End": true}}
},
{
"StartAt": "SageMaker Security Assessment",
"States": {"SageMaker Security Assessment": {"Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "End": true}}
},
{
"StartAt": "AgentCore Security Assessment",
"States": {"AgentCore Security Assessment": {"Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "End": true}}
},
{
"StartAt": "Comprehend Security Assessment",
"States": {"Comprehend Security Assessment": {"Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "End": true}}
}
]
}
}
Step 4: Update AWS IAM Permissions
Add required permissions to every role that may deploy or run the new service assessment:
In deployment/1-aiml-security-member-roles.yaml:
- Effect: Allow
Action:
- comprehend:List*
- comprehend:Describe*
- comprehend:Get*
Resource: '*'
In deployment/aiml-security-single-account.yaml (for single account mode):
- comprehend:List*
- comprehend:Describe*
- comprehend:Get*
In deployment/2-aiml-security-codebuild.yaml (for management-account multi-account mode):
- comprehend:List*
- comprehend:Describe*
- comprehend:Get*
Also add runtime permissions to the new Lambda role statements in both SAM templates if the new service function needs service-specific access at execution time.
Step 5: Test Locally
Test your new assessment function locally:
cd aiml-security-assessment
sam build --template template.yaml
sam local invoke ComprehendSecurityAssessmentFunction --event testfile.json
Assessment Best Practices
1. Security Check Implementation
- Use Cached Permissions: Always use the AWS IAM permission cache to avoid API throttling
- Handle Exceptions: Implement proper error handling and logging
- Follow Least Privilege: Only request necessary permissions
- Standardize Findings: Use the
create_finding()function for consistent output - Check ID Convention: Use service prefixes for check IDs (BR-XX for Amazon Bedrock, SM-XX for Amazon SageMaker AI, AC-XX for Amazon Bedrock AgentCore, FS-XX for Financial Services GenAI risk checks)
- Status Semantics: Use correct status values:
Passed: Resources were checked and met the assessed best practiceFailed: Resources were checked and found non-compliantN/A: No resources exist to check (for example, “No notebooks found”, “No guardrails configured”)
- Severity Values: Use appropriate severity levels:
High: Critical security issues requiring immediate attentionMedium: Important security improvements recommendedLow: Minor optimizations suggestedInformational: Advisory information, no action requiredN/A: Check not applicable (typically paired with N/A status)
2. Performance Optimization
- Batch API Calls: Use pagination and batch operations where possible
- Implement Retries: Use exponential backoff for AWS API calls
- Cache Results: Store intermediate results to avoid redundant API calls
- Set Appropriate Timeouts: Configure AWS Lambda timeout based on assessment complexity
3. Error Handling
try:
# Assessment logic
result = aws_client.describe_service()
except ClientError as e:
if e.response["Error"]["Code"] == "AccessDenied":
# Handle permission issues
logger.warning(f"Access denied for service check: {str(e)}")
return create_finding(
finding_name="Permission Check",
finding_details="Insufficient permissions to assess service",
resolution="Grant required permissions to assessment role",
reference="https://docs.aws.amazon.com/service/permissions",
severity="High",
status="Failed",
)
else:
# Handle other AWS errors
logger.error(f"AWS API error: {str(e)}")
raise
except Exception as e:
# Handle unexpected errors
logger.error(f"Unexpected error: {str(e)}", exc_info=True)
raise
Testing Your Extensions
1. Local Testing
# Test an individual SAM function
cd aiml-security-assessment
sam build --template template.yaml
sam local invoke NewServiceSecurityAssessmentFunction --event test-event.json
2. Integration Testing
# Deploy to test account
sam deploy --stack-name aiml-security-test --capabilities CAPABILITY_IAM
# Execute AWS Step Functions
aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:region:account:stateMachine:TestStateMachine \
--input '{"accountId":"123456789012","enableFinServ":"false"}'
3. Multi-Account Testing
- Deploy member roles to test accounts using AWS CloudFormation StackSets
- Deploy central infrastructure with test parameters
- Monitor AWS CodeBuild logs for deployment and execution status
- Verify results in central Amazon S3 bucket
Monitoring and Debugging
For detailed troubleshooting guidance, common issues, and debugging tips, see the Troubleshooting Guide.
Development Roadmap
Current Status
- AI/ML Assessment: 52 core checks across three services, plus 64 optional Financial Services GenAI risk checks (see Security Checks Reference)
Potential Additions
- Amazon Comprehend: Data privacy, access controls, entity recognition security
- Amazon Textract: Document processing security, PII detection
- Amazon Rekognition: Image analysis security, content moderation
- Amazon Polly/Amazon Transcribe: Voice AI security assessments
Development Pattern
- Each AWS AI/ML service gets its own dedicated AWS Lambda function
- AWS Step Functions orchestrates parallel execution of service assessments
- Multi-region scans use a Step Functions Map state with configurable
MaxRegionConcurrency - FinServ checks are opt-in through
EnableFinServAssessment; the Lambda is deployed by default but invoked only when enabled - Results are consolidated into a single HTML/CSV report
- AWS CodeBuild orchestrates deployment and execution across multiple accounts
Report Generation Architecture
Shared Template Module
Report generation uses a single shared template (report_template.py) for both deployment modes:
aiml-security-assessment/functions/security/generate_consolidated_report/
├── app.py # Lambda handler (single-account)
├── report_template.py # Shared HTML/CSS/JS template
└── ...
consolidate_html_reports.py # CodeBuild script (multi-account)
How It Works
| Component | Mode | Description |
|---|---|---|
app.py (AWS Lambda) |
mode='single' |
Generates per-account HTML reports during AWS Step Functions execution |
consolidate_html_reports.py |
mode='multi' |
Consolidates all account reports in AWS CodeBuild post-build phase |
Both call generate_html_report() from report_template.py with different parameters.
Modifying the Report Template
To update report styling, layout, or features:
- Edit
report_template.pyonly - changes apply to both single and multi-account reports - Run the report generator tests from the report package directory:
python -m pytest test_generate_report.py -v - Key functions:
get_html_template()- HTML/CSS/JS structuregenerate_table_rows()- Finding row generationgenerate_html_report()- Main entry point withmodeparameter (‘single’ or ‘multi’)
Documentation and Screenshots
Updating Sample Reports
When you modify the report template or add new features, update the sample reports and screenshots:
1. Generate New Sample Reports
After making changes to report_template.py, regenerate sample reports from a fresh assessment run or from the local report test fixtures. The existing test_generate_report.py file is a pytest/unittest test module, not a standalone --mode/--output CLI.
# Generate local viewable reports from fixtures
cd aiml-security-assessment/functions/security/generate_consolidated_report
python -m pytest test_generate_report.py -k "generate_viewable_report or generate_multi_account_report" -s
The fixture reports are written under aiml-security-assessment/functions/security/generate_consolidated_report/test_reports/. Use them to validate report rendering before refreshing the canonical files in sample-reports/.
2. Capture Screenshots
The repository includes an automated screenshot capture tool:
# Activate virtual environment
source .venv/bin/activate
# Install dependencies (first time only)
pip install -r sample-reports/dev-requirements.txt
playwright install chromium
# Capture and optimize screenshots
python sample-reports/scripts/capture_screenshots.py
What the script does:
- Opens HTML reports in a headless browser
- Captures key views (dashboard, findings table, dark mode)
- Automatically optimizes images (target: 200-300KB each)
- Converts large PNGs to JPEG if needed
- Saves screenshots in
sample-reports/folder
What gets generated:
The script captures 4 screenshots:
dashboard-overview-light.png- Executive dashboard in light modedashboard-overview-dark.png- Executive dashboard in dark modefindings-table.png- Detailed findings table with filtersmulti-account-summary.png- Multi-account consolidated view
All screenshots are automatically optimized (target: 200-300KB each, ~600KB total).
Customization:
Edit sample-reports/scripts/capture_screenshots.py to customize:
# Viewport size
VIEWPORT_WIDTH = 1440
VIEWPORT_HEIGHT = 900
# Image quality
JPEG_QUALITY = 85 # Range: 1-100
PNG_OPTIMIZE = True
# Add new screenshots to SCREENSHOTS list
SCREENSHOTS = [
{
"name": "my-screenshot",
"file": "security_assessment_single_account.html",
"description": "My Custom View",
"actions": [
{"type": "wait", "selector": ".element", "timeout": 2000},
{"type": "click", "selector": ".button"},
{"type": "scroll", "position": 500},
],
"clip": {"x": 0, "y": 0, "width": 1440, "height": 800},
}
]
Available action types:
wait- Wait for selector (for example,{"type": "wait", "selector": ".metrics", "timeout": 2000})click- Click element (for example,{"type": "click", "selector": ".theme-toggle"})scroll- Scroll to position (for example,{"type": "scroll", "position": 500})wait_time- Wait milliseconds (for example,{"type": "wait_time", "ms": 300})
Troubleshooting:
| Issue | Solution |
|---|---|
playwright not installed |
pip install playwright && playwright install chromium |
| Sample reports not found | Run from repository root |
| Screenshots too large | Lower JPEG_QUALITY or reduce viewport size |
| Browser launch fails | Run playwright install-deps (Linux only) |
3. Update README
After generating new screenshots, update the README to reference them:
### Sample Assessment Reports
**Preview:**

*Executive summary with severity counts and service breakdown*

*Interactive findings table with filtering capabilities*
Documentation Best Practices
- Keep screenshots optimized: Target 200-300KB per image
- Use descriptive filenames:
dashboard-overview-light.png, notscreenshot1.png - Update both HTML and screenshots when making UI changes
- Test screenshots render correctly in GitHub’s markdown preview
- All screenshot tooling: Located in
sample-reports/for easy organization
CI/CD Workflows
GitHub Actions workflows run automatically to validate code quality and security on every pull request.
PR Checks
| Workflow | File | What It Checks |
|---|---|---|
| Python Code Quality | .github/workflows/python-lint.yml |
ruff check (lint) and ruff format --check (formatting) on changed .py files |
| Python Tests | .github/workflows/python-tests.yml |
Runs upstream tests, FinServ tests, and report-pipeline tests in separate pytest sessions |
| CloudFormation Lint | .github/workflows/cfn-lint.yml |
Validates deployment and SAM templates with cfn-lint |
| SAM Validate & Build | .github/workflows/sam-validate.yml |
Runs sam validate --lint and sam build on SAM templates |
| ASH Security Scan | .github/workflows/ash-security-scan.yml |
Scans changed files for secrets, dependency vulnerabilities, and IaC misconfigurations |
Additional workflows run post-merge or on schedule:
| Workflow | File | Trigger |
|---|---|---|
| ASH Full Repository Scan | .github/workflows/ash-full-repository-scan.yml |
Push to main, monthly schedule, manual |
| Labeler | .github/workflows/label.yml |
Auto-labels PRs by changed paths (bedrock, sagemaker, agentcore, deployment, docs) |
cfn-lint suppressions are configured in .cfnlintrc at the repository root for IAM actions not yet in cfn-lint’s database (for example, bedrock-agentcore actions).
Running Checks Locally
Before pushing, run these checks locally to catch issues early:
# Install tools (first time only)
pip install ruff cfn-lint
pip install -r tests/requirements.txt
pip install "pydantic>=2.0.0"
# Python lint and format
ruff check aiml-security-assessment/functions/security/
ruff format --check aiml-security-assessment/functions/security/
# Unit tests. Run these as separate pytest sessions because multiple
# assessment packages use top-level app.py imports.
export AIML_ASSESSMENT_BUCKET_NAME=test-assessment-bucket
export AWS_DEFAULT_REGION=us-east-1
export AWS_ACCESS_KEY_ID=testing
export AWS_SECRET_ACCESS_KEY=testing
python -m pytest tests/ -v --tb=short
python -m pytest aiml-security-assessment/functions/security/finserv_tests/ -v --tb=short
python -m pytest tests/test_consolidate_finserv.py -v --tb=short
cd aiml-security-assessment/functions/security/generate_consolidated_report
python -m pytest test_generate_report.py -v --tb=short
cd -
# CloudFormation lint
cfn-lint deployment/*.yaml
cfn-lint aiml-security-assessment/template.yaml
cfn-lint aiml-security-assessment/template-multi-account.yaml
# SAM validate and build
cd aiml-security-assessment
sam validate --template template.yaml --lint
sam validate --template template-multi-account.yaml --lint
sam build --template template.yaml
sam build --template template-multi-account.yaml
Support and Resources
Documentation
This developer guide provides the foundation for extending the AI/ML Security Assessment Framework. As you add new AI/ML services and security checks, please update this documentation to help future contributors understand and build upon your work.