Architecture
Architecture
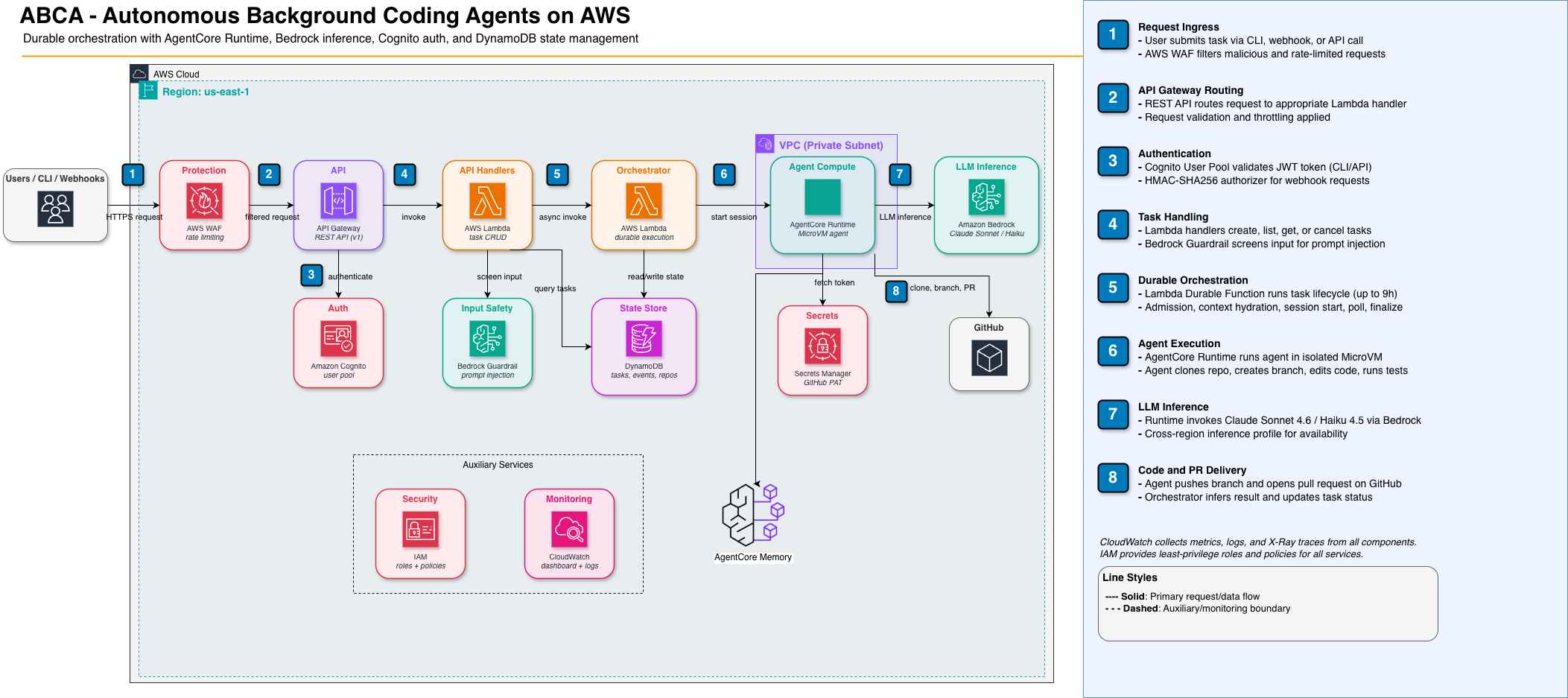
Section titled “Architecture”This document outlines the overall architecture of the project. You can refer to the specific documents in the current folder for deep dive on each block.
Design Principles
Section titled “Design Principles”- Extensibility: possibility to extend the system without modifying core code
- Flexibility: this field is moving fast and is still experimental, we want to be able to switch components as needed. Critical components should be accessed through internal interfaces (e.g., ComputeStrategy, MemoryStore) so that implementations can be swapped without rewriting the codebase.
- Reliability / fault tolerance: critical for long-running agents. What happens when things fail mid-task?
- Cost efficiency: with agents potentially running for hours and burning tokens, this should be a first-class concern from day one.
- Security by default: given the agent executes code and has repo access, we want isolated sandboxed environments, fine grain access control, least-privilege access.
- Observability and evaluation: it should be easy to see everything that is going on — task lifecycle, agent reasoning, tool use, and outcomes — so the system can be monitored, debugged, and improved over time. It will also help to evaluate different configurations of components.
Project positioning: platform and reference architecture
Section titled “Project positioning: platform and reference architecture”ABCA serves two purposes: a deployable, self-hosted platform for running autonomous coding agents, and a reference architecture for building agent platforms on AWS. Understanding both roles clarifies packaging, API stability, and documentation decisions.
Deployable platform
Section titled “Deployable platform”The primary consumption model is operational. ABCA is a CDK application (AwsCdkTypeScriptApp) that you deploy into an AWS account. The Blueprint construct onboards repositories, the orchestrator framework runs tasks, and teams interact through the CLI (bgagent), REST API, or webhooks. The value proposition: autonomous coding agents running in isolated compute with managed lifecycle, concurrency control, and cost efficiency.
The internal extensibility model — interface-driven components (ComputeStrategy, blueprint customization layers, swappable providers) — serves platform operators who want to customize behavior without forking.
Reference architecture
Section titled “Reference architecture”ABCA is also a reference implementation for how to build an autonomous agent platform on AWS. The design documents in docs/design/ form a comprehensive architectural decision record covering:
- Durable orchestration — task state machine, checkpoint/replay with Lambda Durable Functions, failure modes and recovery
- Blueprint framework — lifecycle hooks, 3-layer customization model, step input/output contracts
- Compute abstraction — strategy pattern for agent session management across providers (AgentCore, ECS)
- Agent lifecycle — context hydration, session monitoring via async invocation and sticky routing, result inference
- CDK-based multi-tenant onboarding — per-repo configuration as infrastructure, custom resource lifecycle
- Concurrency and cost management — atomic counters, queue design, token budgets, poll cost analysis
Teams building their own agent platforms can study and adapt these patterns. The architecture is prescriptive: it demonstrates how AgentCore, Bedrock, CDK, DynamoDB, and Cognito compose into a coherent system for long-running autonomous agents.
Competitive landscape (March 2026)
Section titled “Competitive landscape (March 2026)”Autonomous coding platforms tend to converge on a common architecture: sandboxed execution per task, hybrid deterministic+agentic orchestration, and PR output with a human review gate.
ABCA’s differentiators: self-hosted (data stays in your AWS account), CDK-based infrastructure-as-code (customizable, auditable), strong security controls (VPC isolation, DNS Firewall, WAF, Bedrock Guardrails), and cross-session memory (Tier 1 operational). Current gaps include live session visibility, multi-agent coordination, and mid-execution human feedback.
What ABCA is not
Section titled “What ABCA is not”A construct library. There is no jsii compilation, no npm publishing, no Construct Hub listing, and no stable public API contract for external consumers. The project is packaged with release: false and stability: 'experimental'. Non-backward-compatible changes between iterations are acceptable when they simplify the design.
How this affects contributors and adopters
Section titled “How this affects contributors and adopters”| Audience | Consumption model |
|---|---|
| Operators (primary) | Deploy the CDK app, onboard repos via Blueprint, submit tasks through CLI/API/webhooks. Customize via blueprint configuration (compute strategies, custom steps, step sequences). |
| Platform developers | Extend the platform by implementing internal interfaces (ComputeStrategy, custom step Lambdas). Follow the internal extension points, not a public API contract. |
| Teams building their own agent platforms | Study the architecture and design docs as a reference implementation. Fork and adapt the patterns. No stable library API to depend on — treat it as a codebase to learn from and modify, not to import. |
Background agents
Section titled “Background agents”User flow
Section titled “User flow”Agents are fully unattended. No confirmation prompts, no human-triggered commands during execution. The quarantined MicroVM environment means any mistakes are confined to the limited blast radius of one devbox (a branch in a repo), so the agent runs with full permissions. Human review happens only at the PR stage. It’s a one shot mode -> user sends a task, and an agent works on it.
- User uses one of the supported client (CLI,…) and submit a task by providing a GitHub repository and a task description (either text or GitHub issue). Also, a task can be triggered through a webhook or run on schedule. The system accepts multi-modal content (text, images).
- The input gateway
- Task is submitted to the system. If the repository is not onboarded to the system, an error message is sent back to the user. Otherwise, the user receives confirmation and a task id.
- The task pipeline is triggered.
- Agent works on the task in an isolated sandboxed environment. Clones the repository, starts a branch, perform changes on files, commit, run tests, build.
- Once the task pipeline is done, a pull request is created. The agent adds any useful artifacts to the pull request as attachment (images, videos,…) to prove the feature is working.
- At anytime, the user can use a supported client to query about a task (status) or cancel it.
Blueprints: deterministic orchestration and agent workload
Section titled “Blueprints: deterministic orchestration and agent workload”Overview
Section titled “Overview”
A blueprint is the definition of how a task runs: a hybrid workflow that mixes deterministic steps (no LLM, predictable, cheap) with one or more agentic steps (LLM-driven, flexible, expensive). In our architecture, each user task is executed according to a blueprint.
The task pipeline is implemented by a durable orchestrator (e.g. Lambda Durable Functions) that runs the deterministic part: admission control, context hydration, starting the agent session, polling for session completion, and finalization (result inference from GitHub, cleanup). The non-deterministic part is the agent workload itself: a single long-running agent session inside the compute environment (clone repo, edit code, commit, run tests, create PR). The orchestrator never runs the agent logic; it only invokes the runtime that hosts the agent and then waits for the session to end.
So: blueprint = the task. The blueprint is the sequence of deterministic steps plus the invocation of the agent. The orchestrator is a framework that enforces platform invariants (state machine, events, concurrency, cancellation) and delegates variable work to blueprint-defined step implementations. Blueprints customize what runs through three layers: (1) parameterized built-in strategies — select and configure built-in step implementations (e.g. compute.type: 'agentcore' vs 'ecs'); (2) Lambda-backed custom steps — provide a Lambda ARN for custom logic at specific pipeline phases; (3) custom step sequences — define which steps run and in what order. The framework wraps every step with state transitions, event emission, and cancellation checks, ensuring platform guarantees hold regardless of customization. See Repository onboarding for the full blueprint execution framework and customization model.
For the full orchestrator design — task state machine, execution model, failure modes, concurrency management, data model, and implementation strategy — see ORCHESTRATOR.md.
The steps below are the blueprint in action: deterministic orchestration (1–2, 4) and one agentic step (3).
- Deterministic: The task orchestrator runs admission control, then context hydration (task id, issue body, user message, memory context → assembled prompt). When AgentCore Memory is configured, context hydration loads repository knowledge (semantic search) and past task episodes (episodic search) in parallel and injects them into the system prompt. See MEMORY.md.
- Deterministic: The orchestrator starts the agent session (compute environment) and passes in the prompt. The prompt version (SHA-256 hash of deterministic prompt parts) is stored on the task record for traceability.
- Agentic: The agent runs in the isolated environment: clone repo, create branch, edit code, commit often, run tests and lint, create PR. Commits are attributed via git trailers (
Task-Id,Prompt-Version). At task end, the agent writes memory (task episode + repo learnings) to AgentCore Memory. The orchestrator does not execute this logic; it only waits for the session to finish. - Deterministic: The orchestrator infers the result (e.g. by querying GitHub for a PR on the agent’s branch), updates task status, and finalizes (result inference, cleanup). If the agent did not write memory (crash, timeout), the orchestrator writes a fallback episode. A validation step may run here (e.g. configurable post-agent checks); see repo onboarding for customizing these steps.
For the API contract — endpoints, request/response schemas, error codes, authentication, and pagination — see API_CONTRACT.md.
Onboarding pipeline
Section titled “Onboarding pipeline”Overview
Section titled “Overview”The onboarding pipeline is separate from the coding agent pipeline. It provides a way to onboard a new repository to the system.
Onboarding is CDK-based. Each repository is an instance of the Blueprint CDK construct in the stack. The construct provisions per-repo infrastructure and writes a RepoConfig record to the shared RepoTable in DynamoDB. Deploying the stack = onboarding or updating repos. There is no runtime API for repo CRUD.
Flow: CDK deploy → Blueprint custom resource → DynamoDB RepoTable (PutItem with status: 'active') → orchestrator reads RepoConfig at task time.
The Blueprint construct configures how the orchestrator framework executes steps for that repo: compute strategy selection (compute_type), Lambda-backed custom steps (custom_steps), and optional step sequence overrides (step_sequence), alongside per-repo model, turn limits, GitHub token, and poll interval. The orchestrator loads this config after load-task and passes it to each subsequent step. See REPO_ONBOARDING.md for the full Blueprint construct interface, RepoConfig schema, blueprint execution framework, and integration point details.
Control panel
Section titled “Control panel”Overview
Section titled “Overview”The control panel is a web-based UI (dashboard) that gives operators and users a central place to manage the platform, see what the agents are doing, and inspect outcomes. It complements the CLI and other channels: users can submit and manage tasks from the CLI or Slack, but the control panel provides a unified view across tasks, agents, and system health. More details in the dedicated documentation.
TODO: add more info
Cost model
Section titled “Cost model”Cost efficiency is a design principle. The following estimates are based on 50 tasks/day with an average session duration of ~1 hour per task.
Per-component monthly cost estimate (50 tasks/day)
Section titled “Per-component monthly cost estimate (50 tasks/day)”| Component | Estimated monthly cost | Dominant cost driver |
|---|---|---|
| AgentCore Runtime (2 vCPU, 8 GB, ~1 hr/task) | ~$300–500 | vCPU-hours + GB-hours |
| Bedrock inference (agent reasoning, ~200K tokens/task avg) | ~$300–900 | Input/output tokens × model price |
| Bedrock inference (extraction, self-feedback, ~2 calls/task) | ~$30–100 | Additional LLM calls at task end |
| Lambda (orchestrator polls, handlers, webhooks) | ~$10–30 | ~48K poll invocations/day + handler invocations |
| DynamoDB (on-demand: tasks, events, counters, webhooks) | ~$5–20 | Write capacity units for events |
| API Gateway (REST API, ~2K requests/day) | ~$5–15 | Per-request pricing |
| AgentCore Memory (events, records, retrieval) | TBD | Pricing not fully public; proportional to usage |
| CloudWatch (logs, metrics, traces, Transaction Search) | ~$20–50 | Log ingestion + storage |
| Secrets Manager (GitHub App keys, webhook secrets) | ~$5–10 | Per-secret/month + API calls |
| S3 (artifacts, memory backups) | ~$1–5 | Storage + requests |
| Total | ~$700–1,600/month |
Per-task cost breakdown
Section titled “Per-task cost breakdown”| Phase | Estimated cost per task | Notes |
|---|---|---|
| Orchestrator (Lambda polls + handlers) | ~$0.001 | ~960 polls × $0.0000002/invocation |
| Compute (AgentCore Runtime, 1 hr) | ~$0.20–0.35 | vCPU-hours + GB-hours |
| Inference (agent reasoning) | ~$0.20–0.60 | Depends heavily on model choice and token volume |
| Inference (extraction + self-feedback) | ~$0.02–0.07 | 2 short LLM calls |
| Memory (load + write) | ~$0.01–0.05 | 4 retrieval + 2 write API calls |
| Total per task | ~$0.45–1.10 |
Cost levers
Section titled “Cost levers”| Lever | Impact | Trade-off |
|---|---|---|
| Model choice | Largest single lever. Sonnet vs. Opus can be 3–5× difference. | Cheaper models may produce lower-quality PRs. |
| Session duration | Directly proportional to compute cost. Turn caps (Iter 3a) help. | Shorter sessions may leave tasks incomplete. |
| Poll interval | 30s → 60s halves orchestrator Lambda invocations. | Slower status updates (acceptable for hour-long tasks). |
| Memory retrieval depth | Fewer records retrieved = fewer API calls + shorter prompts. | Less context may reduce PR quality. |
| Token budget per task | Cap total tokens (input + output) per session. | Agent may stop before completing the task. |
Key insight
Section titled “Key insight”The dominant cost is Bedrock inference + compute, not infrastructure. Memory, Lambda, DynamoDB, and API Gateway are a small fraction of total cost. This supports investing in managed services (AgentCore Memory, AgentCore Runtime) — the operational simplification is justified because infrastructure cost is not the bottleneck.
Known architectural risks
Section titled “Known architectural risks”The following risks were identified via external review (March 2026) and are tracked in repository issues.
| # | Risk | Severity | Component | Mitigation status |
|---|---|---|---|---|
| 1 | Agent vs. orchestrator DynamoDB race — agent/task_state.py writes terminal status without conditional expressions, so it can overwrite orchestrator-managed CANCELLED with COMPLETED. The orchestrator’s transitionTask() uses ConditionExpression but the agent side does not. | High | agent/task_state.py | Resolved (Iteration 3bis) — ConditionExpression guards added to write_running() (requires status IN SUBMITTED, HYDRATING) and write_terminal() (requires status IN RUNNING, HYDRATING, FINALIZING). ConditionalCheckFailedException is caught and logged as a skip. |
| 2 | No DLQ on orchestrator async invocation — The orchestrator Lambda is invoked with InvocationType: 'Event' but has no dead-letter queue. Failed or throttled invocations leave tasks stuck in SUBMITTED. | High | src/constructs/task-orchestrator.ts | Resolved (Iteration 3bis) — SQS DLQ deliberately skipped since durable execution (withDurableExecution, 14-day retention) manages its own retries; a DLQ would conflict. Added retryAttempts: 0 on alias async invoke config to prevent Lambda-level duplicate invocations. CloudWatch alarm on fn.metricErrors() (threshold: 3, 2 periods of 5min) provides alerting. |
| 3 | Concurrency counter drift — If the orchestrator crashes between concurrency increment and decrement, the user’s counter is permanently inflated. The UserConcurrencyTable JSDoc acknowledges this but no reconciliation process exists. | Medium | src/constructs/user-concurrency-table.ts | Resolved (Iteration 3bis) — ConcurrencyReconciler construct with scheduled Lambda (EventBridge rate 15min). Scans concurrency table, queries task table’s UserStatusIndex GSI per user, compares actual count with stored active_count, and corrects drift. TOCTOU-safe via ConditionExpression on update. |
| 4 | Single NAT Gateway — natGateways: 1 means a single AZ failure blocks all agent internet egress. Acceptable for development; needs multi-AZ NAT for production. | Medium | src/constructs/agent-vpc.ts | Mitigated (Iteration 3bis) — already configurable via AgentVpcProps.natGateways (default: 1). Deployers can set natGateways: 2 or higher for multi-AZ redundancy. No code changes needed. |
| 5 | Dual-language prompt assembly — Both TypeScript (context-hydration.ts:assembleUserPrompt) and Python (entrypoint.py:assemble_prompt) implement the same logic. Changes to one must be manually replicated in the other. | Medium | src/handlers/shared/context-hydration.ts, agent/entrypoint.py | Mitigated (Iteration 3bis) — production path uses orchestrator’s assembleUserPrompt() exclusively; the Python assemble_prompt() has a deprecation docstring and is retained only for local batch mode and dry-run mode. Risk of divergence reduced but not eliminated. |
Cross-reference: concept ownership
Section titled “Cross-reference: concept ownership”Each concept has a source-of-truth document and one or more documents that reference it. When updating a concept, start with the source doc.
| Concept | Source of truth | Referenced by |
|---|---|---|
| Task state machine and lifecycle | ORCHESTRATOR.md | API_CONTRACT.md, OBSERVABILITY.md, ROADMAP.md |
| Memory components (Tiers 1–4) | MEMORY.md | EVALUATION.md, ROADMAP.md, SECURITY.md, src/constructs/agent-memory.ts, src/handlers/shared/memory.ts, agent/memory.py |
| Review feedback loop | MEMORY.md (Review feedback memory) | SECURITY.md (prompt injection), EVALUATION.md (data sources), ROADMAP.md (3d) |
| Agent self-feedback | MEMORY.md (Insights section) | EVALUATION.md (Agent self-feedback section) |
| Prompt versioning | EVALUATION.md (Prompt versioning) | ORCHESTRATOR.md (data model: prompt_version), ROADMAP.md (3b), src/handlers/shared/prompt-version.ts |
| Extraction prompts | MEMORY.md (Extraction prompts) | EVALUATION.md (references), ROADMAP.md (3b) |
| Tiered tool access | SECURITY.md (Input validation) | REPO_ONBOARDING.md, ROADMAP.md (Iter 5) |
| Memory isolation | SECURITY.md (Memory-specific threats) | MEMORY.md (Requirements), ROADMAP.md (Iter 5) |
| Data protection / DR | SECURITY.md (Data protection) | — |
| 2GB image limit | COMPUTE.md (AgentCore Runtime 2GB) | ROADMAP.md (Iter 5: alternate runtime) |
| Cost model | COST_MODEL.md | ARCHITECTURE.md, ORCHESTRATOR.md (poll cost), NETWORK_ARCHITECTURE.md, COMPUTE.md |
| RepoConfig schema and blueprint execution framework | REPO_ONBOARDING.md | ORCHESTRATOR.md, ARCHITECTURE.md |
| Re-onboarding triggers | REPO_ONBOARDING.md | MEMORY.md (consolidation), COMPUTE.md (snapshot-on-schedule) |
| Real-time streaming | API_CONTRACT.md (OQ1) | ROADMAP.md (Iter 4), CONTROL_PANEL.md |
| Model selection | ARCHITECTURE.md (Per-repo model selection) | ORCHESTRATOR.md (model_id), ROADMAP.md (3a blueprint config) |
| Project positioning (platform and reference architecture) | ARCHITECTURE.md (Project positioning) | ROADMAP.md (Iter 6: reusable constructs), README.md |
| ComputeStrategy interface | REPO_ONBOARDING.md (Compute strategy interface) | ORCHESTRATOR.md, COMPUTE.md, ROADMAP.md (Iter 5) |
| Custom steps trust boundary | SECURITY.md (Blueprint custom steps) | REPO_ONBOARDING.md, ORCHESTRATOR.md |
| Step event types | API_CONTRACT.md (Event types) | OBSERVABILITY.md (Task lifecycle) |
| Operational procedures and deployment safety | OBSERVABILITY.md | ORCHESTRATOR.md (counter drift), ROADMAP.md (Iter 5: CI/CD) |
| Network availability (NAT Gateway) | NETWORK_ARCHITECTURE.md | COST_MODEL.md, ARCHITECTURE.md (Known risks) |
| Architectural risks and design-code gaps | ARCHITECTURE.md (Known risks) | ROADMAP.md (Pre-production hardening) |
| Agent swarm orchestration | ROADMAP.md (Iter 6) | — |
| Adaptive model router | ROADMAP.md (Iter 5) | COST_MODEL.md |
| Capability-based security | ROADMAP.md (Iter 5) | SECURITY.md |
| Live session replay | ROADMAP.md (Iter 4) | API_CONTRACT.md |
Per-repo model selection
Section titled “Per-repo model selection”Different tasks and repos may benefit from different models. The model_id field in the blueprint config (see ORCHESTRATOR.md) allows per-repo overrides. Suggested defaults:
- Implementation tasks: Claude Sonnet 4 (good balance of quality and cost)
- PR review tasks: Claude Haiku (fast, cheap — review is read-only analysis)
- Complex/critical repos: Claude Opus 4 (highest quality, highest cost — opt-in per repo)