Using Layout Analysis for Text Linearization
This example uses Textractor to predict layout components in a document page and return the text output in reading order. We will also demonstrate how text linearization can be tailored to your specific usecase though the TextLinearizationConfig object.
Installation
To begin, install the amazon-textract-textractor package using pip.
pip install amazon-textract-textractor
There are various sets of dependencies available to tailor your installation to your use case. The base package will have sensible default, but you may want to install the PDF extra dependencies if your workflow uses PDFs with pip install amazon-textract-textractor[pdfium]. You can read more on extra dependencies in the documentation
Calling Textract
[1]:
import os
from PIL import Image
from textractor import Textractor
from textractor.visualizers.entitylist import EntityList
from textractor.data.constants import TextractFeatures
[2]:
image = Image.open("../../../tests/fixtures/matrix.png").convert("RGB")
image
[2]:
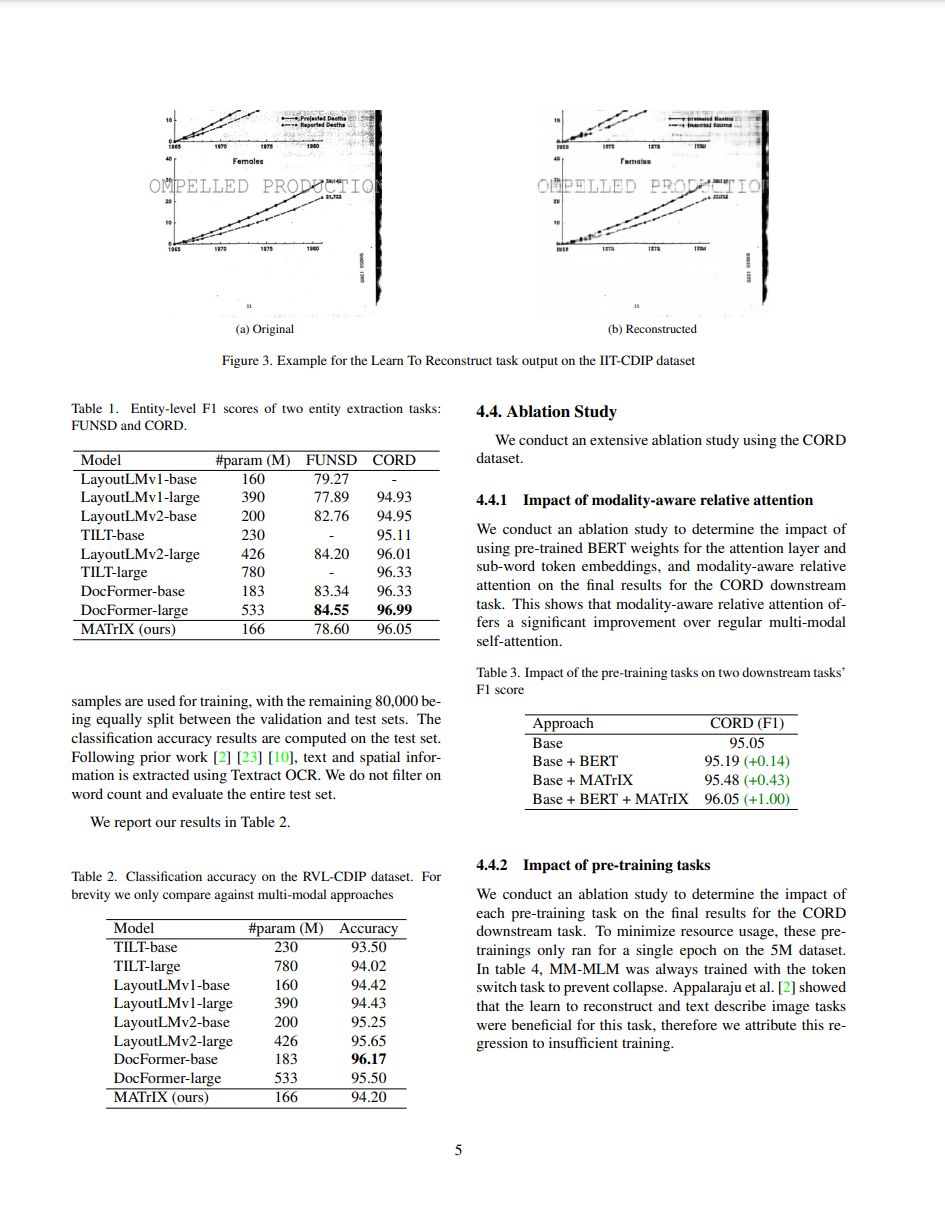
The image above, taken from a research paper, uses a two-column layout.
[5]:
extractor = Textractor(region_name="us-west-2")
document = extractor.detect_document_text(
file_source=image,
save_image=True
)
[6]:
print(document.text)
Reported
1945
1970
1877
-
TETS
Females
famales
PELLED PRODUCTIO
OMPELLED PRODUCTIO
21,722
1965
1979
1971
1980
ITTA
-
(a) Original
(b) Reconstructed
Figure 3. Example for the Learn To Reconstruct task output on the IIT-CDIP dataset
Table 1. Entity-level F1 scores of two entity extraction tasks:
4.4. Ablation Study
FUNSD and CORD.
We conduct an extensive ablation study using the CORD
Model
#param (M)
FUNSD
CORD
dataset.
LayoutLMvl-base
160
79.27
-
LayoutLMvl-large
390
77.89
94.93
4.4.1 Impact of modality-aware relative attention
LayoutLMv2-base
200
82.76
94.95
TILT-base
230
95.11
We conduct an ablation study to determine the impact of
-
LayoutLMv2-large
426
84.20
96.01
using pre-trained BERT weights for the attention layer and
TILT-large
780
-
96.33
sub-word token embeddings, and modality-aware relative
DocFormer-base
183
83.34
96.33
attention on the final results for the CORD downstream
DocFormer-large
533
84.55
96.99
task. This shows that modality-aware relative attention of-
MATrIX (ours)
166
78.60
96.05
fers a significant improvement over regular multi-modal
self-attention.
Table 3. Impact of the pre-training tasks on two downstream tasks'
F1 score
samples are used for training, with the remaining 80,000 be-
ing equally split between the validation and test sets. The
Approach
CORD (F1)
classification accuracy results are computed on the test set.
Base
95.05
Following prior work [2] [23] [10], text and spatial infor-
Base + BERT
95.19 (+0.14)
mation is extracted using Textract OCR. We do not filter on
Base + MATrIX
95.48 (+0.43)
word count and evaluate the entire test set.
Base + BERT + MATrIX
96.05 (+1.00)
We report our results in Table 2.
4.4.2 Impact of pre-training tasks
Table 2. Classification accuracy on the RVL-CDIP dataset. For
brevity we only compare against multi-modal approaches
We conduct an ablation study to determine the impact of
each pre-training task on the final results for the CORD
Model
#param (M)
Accuracy
downstream task. To minimize resource usage, these pre-
TILT-base
230
93.50
trainings only ran for a single epoch on the 5M dataset.
TILT-large
780
94.02
In table 4, MM-MLM was always trained with the token
LayoutLMvl-base
160
94.42
switch task to prevent collapse. Appalaraju et al. [2] showed
LayoutLMvl-large
390
94.43
that the learn to reconstruct and text describe image tasks
LayoutLMv2-base
200
95.25
were beneficial for this task, therefore we attribute this re-
LayoutLMv2-large
426
95.65
gression to insufficient training.
DocFormer-base
183
96.17
DocFormer-large
533
95.50
MATrIX (ours)
166
94.20
5
As we can see, the lack of layout awareness in the raw OCR output of the DetectDocumentText API causes the resulting text to be scrambled making it difficult to extract relevant information.
Instead, let’s use the new Layout feature of the AnalyzeDocument API
[7]:
document = extractor.analyze_document(
file_source=image,
features=[TextractFeatures.LAYOUT],
save_image=True
)
[8]:
print(document.text)
Reported
1945
1970
1877
Females
PELLED PRODUCTIO
21,722
1965
1979
1971
1980
(a) Original
-
TETS
famales
OMPELLED PRODUCTIO
ITTA
-
(b) Reconstructed
Figure 3. Example for the Learn To Reconstruct task output on the IIT-CDIP dataset
Table 1. Entity-level F1 scores of two entity extraction tasks: FUNSD and CORD.
Model #param (M) FUNSD CORD
LayoutLMvl-base 160 79.27
-
LayoutLMvl-large 390 77.89 94.93
LayoutLMv2-base 200 82.76 94.95
TILT-base 230 - 95.11
LayoutLMv2-large 426 84.20 96.01
TILT-large 780 - 96.33
DocFormer-base 183 83.34 96.33
DocFormer-large 533 84.55 96.99
MATrIX (ours) 166 78.60 96.05
samples are used for training, with the remaining 80,000 be- ing equally split between the validation and test sets. The classification accuracy results are computed on the test set. Following prior work [2] [23] [10], text and spatial infor- mation is extracted using Textract OCR. We do not filter on word count and evaluate the entire test set.
We report our results in Table 2.
Table 2. Classification accuracy on the RVL-CDIP dataset. For brevity we only compare against multi-modal approaches
Model #param (M) Accuracy
TILT-base 230 93.50
TILT-large 780 94.02
LayoutLMvl-base 160 94.42
LayoutLMvl-large 390 94.43
LayoutLMv2-base 200 95.25
LayoutLMv2-large 426 95.65
DocFormer-base 183 96.17
DocFormer-large 533 95.50
MATrIX (ours) 166 94.20
4.4. Ablation Study
We conduct an extensive ablation study using the CORD dataset.
4.4.1 Impact of modality-aware relative attention
We conduct an ablation study to determine the impact of using pre-trained BERT weights for the attention layer and sub-word token embeddings, and modality-aware relative attention on the final results for the CORD downstream task. This shows that modality-aware relative attention of- fers a significant improvement over regular multi-modal self-attention.
Table 3. Impact of the pre-training tasks on two downstream tasks' F1 score
Approach CORD (F1)
Base 95.05
Base + BERT 95.19 (+0.14)
Base + MATrIX 95.48 (+0.43)
Base + BERT + MATrIX 96.05 (+1.00)
4.4.2 Impact of pre-training tasks
We conduct an ablation study to determine the impact of each pre-training task on the final results for the CORD downstream task. To minimize resource usage, these pre- trainings only ran for a single epoch on the 5M dataset. In table 4, MM-MLM was always trained with the token switch task to prevent collapse. Appalaraju et al. [2] showed that the learn to reconstruct and text describe image tasks were beneficial for this task, therefore we attribute this re- gression to insufficient training.
5
The above is much better, avoiding the column overlap, but what if you want to remove the text extracted from figures which is not part of the main text and have specific header indicator for markdown rendering? To do so, we will leverage the `TextLinearizationConfig <>`__ object which has over 40 options to tailor the text linearization to your use case.
[19]:
from textractor.data.text_linearization_config import TextLinearizationConfig
config = TextLinearizationConfig(
hide_figure_layout=True,
title_prefix="# ",
section_header_prefix="## "
)
print(document.get_text(config=config))
(a) Original
(b) Reconstructed
Figure 3. Example for the Learn To Reconstruct task output on the IIT-CDIP dataset
Table 1. Entity-level F1 scores of two entity extraction tasks: FUNSD and CORD.
Model #param (M) FUNSD CORD
LayoutLMvl-base 160 79.27
-
LayoutLMvl-large 390 77.89 94.93
LayoutLMv2-base 200 82.76 94.95
TILT-base 230 - 95.11
LayoutLMv2-large 426 84.20 96.01
TILT-large 780 - 96.33
DocFormer-base 183 83.34 96.33
DocFormer-large 533 84.55 96.99
MATrIX (ours) 166 78.60 96.05
samples are used for training, with the remaining 80,000 be- ing equally split between the validation and test sets. The classification accuracy results are computed on the test set. Following prior work [2] [23] [10], text and spatial infor- mation is extracted using Textract OCR. We do not filter on word count and evaluate the entire test set.
We report our results in Table 2.
Table 2. Classification accuracy on the RVL-CDIP dataset. For brevity we only compare against multi-modal approaches
Model #param (M) Accuracy
TILT-base 230 93.50
TILT-large 780 94.02
LayoutLMvl-base 160 94.42
LayoutLMvl-large 390 94.43
LayoutLMv2-base 200 95.25
LayoutLMv2-large 426 95.65
DocFormer-base 183 96.17
DocFormer-large 533 95.50
MATrIX (ours) 166 94.20
## 4.4. Ablation Study
We conduct an extensive ablation study using the CORD dataset.
## 4.4.1 Impact of modality-aware relative attention
We conduct an ablation study to determine the impact of using pre-trained BERT weights for the attention layer and sub-word token embeddings, and modality-aware relative attention on the final results for the CORD downstream task. This shows that modality-aware relative attention of- fers a significant improvement over regular multi-modal self-attention.
Table 3. Impact of the pre-training tasks on two downstream tasks' F1 score
Approach CORD (F1)
Base 95.05
Base + BERT 95.19 (+0.14)
Base + MATrIX 95.48 (+0.43)
Base + BERT + MATrIX 96.05 (+1.00)
## 4.4.2 Impact of pre-training tasks
We conduct an ablation study to determine the impact of each pre-training task on the final results for the CORD downstream task. To minimize resource usage, these pre- trainings only ran for a single epoch on the 5M dataset. In table 4, MM-MLM was always trained with the token switch task to prevent collapse. Appalaraju et al. [2] showed that the learn to reconstruct and text describe image tasks were beneficial for this task, therefore we attribute this re- gression to insufficient training.
5
Conclusion
By leveraging layout information, we can linearize the text in a way that is easier to read of both humans and LLMs. In the “Textractor for large language model” notebook, we explore how this can lead to greatly improved question answering capabilities.