AI分析パイプライン
Segment Analyzerは、Strands SDKベースのReAct(Reasoning + Acting)エージェントです。アップストリーム前処理結果(OCR、BDA、PDFテキスト、Transcribe)とAIツールを組み合わせて、文書と映像を反復的に分析します。エージェントが自ら質問を生成し、ツールを呼び出して回答を取得し、統合するプロセスを繰り返すことで、深い分析を実行します。
分析フロー全体構造
Section titled “分析フロー全体構造”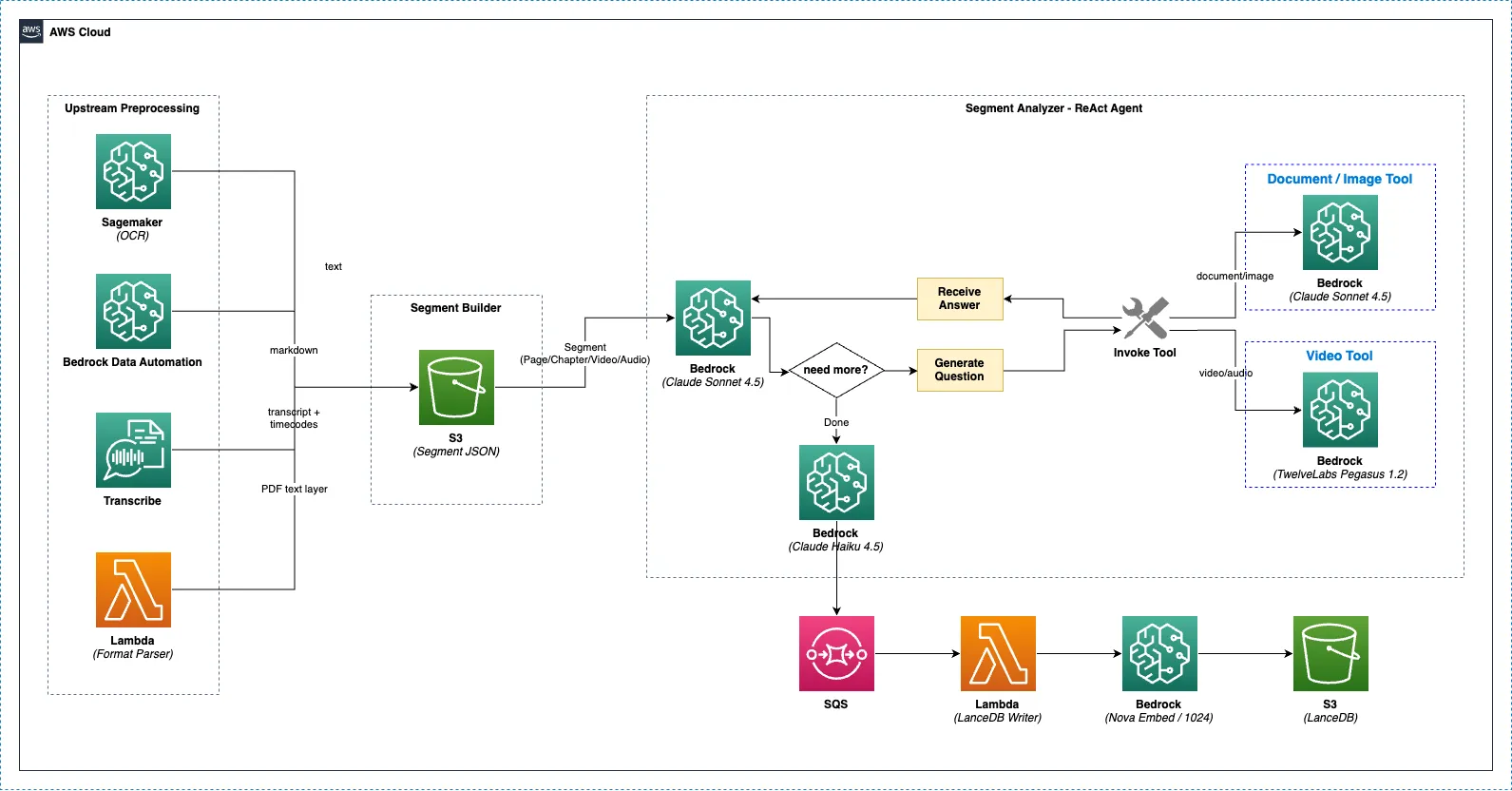
アップストリーム前処理(並列) ├─ PaddleOCR (Lambda/SageMaker) ── テキスト抽出(自動) ├─ Bedrock Data Automation ── 文書構造分析(オプション) ├─ Format Parser ── PDFテキストレイヤー抽出(自動、PDFのみ) └─ AWS Transcribe ── 音声/映像テキスト変換(自動) ↓ Segment Builder(全結果をマージ → S3セグメントJSON) ↓ Segment Analyzer (ReAct Agent) ├─ 文書/画像 → Claude Sonnet 5 + 画像分析ツール └─ 映像/音声 → Claude Sonnet 5 + Pegasus映像分析ツール ↓ Analysis Finalizer → SQS → LanceDB Writer ↓ Document Summarizer (Claude Haiku 4.5)アップストリーム前処理
Section titled “アップストリーム前処理”Segment Analyzerが分析を開始する前に、複数の前処理機が元ファイルから情報を抽出します。ファイルタイプ別前処理フローの詳細はPreprocessing Pipelineを参照してください。
PaddleOCR
Section titled “PaddleOCR”文書と画像からテキストを抽出します。詳細はOCR on SageMakerを参照してください。
Bedrock Data Automation(オプション)
Section titled “Bedrock Data Automation(オプション)”AWS BDAを使用して文書構造(テーブル、レイアウトなど)をマークダウン形式で分析します。プロジェクト設定で有効/無効を切り替えられます。
AWS Transcribe
Section titled “AWS Transcribe”オーディオ/ビデオファイルから音声をテキストに変換します。タイムコード付きのセグメント単位トランスクリプトを生成します。
Format Parser
Section titled “Format Parser”| 項目 | 値 |
|---|---|
| 対象 | PDFファイルのみ(application/pdf) |
| ライブラリ | pypdf |
| 動作 | ページごとのテキストレイヤー抽出 |
| 目的 | デジタルPDFの場合、OCRなしで正確なテキスト確保 |
デジタルPDFにはテキストレイヤーが含まれており、OCRより正確な元テキストを抽出できます。この結果はOCR/BDA結果とともにSegment Analyzerのコンテキストとして提供されます。
Segment Builder
Section titled “Segment Builder”全前処理結果を単一セグメントJSONにマージするステップです。
文書/画像セグメント
Section titled “文書/画像セグメント”{ "segment_index": 0, "segment_type": "PAGE", "image_uri": "s3://.../preprocessed/page_0000.png", "paddleocr": "OCRで抽出したテキスト...", "bda_indexer": "BDAマークダウン結果...", "format_parser": "PDFテキストレイヤー...", "ai_analysis": []}映像/音声セグメント
Section titled “映像/音声セグメント”{ "segment_index": 0, "segment_type": "CHAPTER", "file_uri": "s3://.../video.mp4", "start_timecode_smpte": "00:00:00:00", "end_timecode_smpte": "00:05:30:00", "transcribe": "全トランスクリプト...", "transcribe_segments": [ {"id": 0, "transcript": "...", "start_time": "0.0", "end_time": "5.2"} ], "bda_indexer": "チャプター要約...", "ai_analysis": []}Segment Analyzer(ReAct Agent)
Section titled “Segment Analyzer(ReAct Agent)”Segment Analyzerは反復的質問-回答方式で分析します。エージェントがコンテキスト(OCR、BDA、PDFテキストなど)を確認した後、自ら質問を作成してツールを呼び出し、回答を受けて統合します。このプロセスを複数回繰り返して深い分析を実行します。
エージェントがコンテキスト確認 → 「この文書のタイプを確認する必要がある」 → analyze_image("この文書のタイプと構造は?")を呼び出し → Claude Sonnet 5が画像を見て回答 → 「テーブルがあるので詳しく分析する必要がある」 → analyze_image("テーブルの構造とデータを抽出して")を呼び出し → Claude Sonnet 5が回答 → 「技術図面の寸法を確認する必要がある」 → analyze_image("図面に表示された寸法と仕様は?")を呼び出し → Claude Sonnet 5が回答 → 全結果を統合して最終分析を作成適応型分析深度
Section titled “適応型分析深度”エージェントはコンテンツの複雑さに応じて分析深度を自動調整します。
| 複雑度 | ツール呼び出し回数 | 例 |
|---|---|---|
| 最小 | 1回 | 空白ページ、単純テキスト |
| 通常 | 2〜3回 | 一般的な文書ページ |
| 深層 | 4回以上 | 技術図面、複雑なテーブル、ダイアグラム |
文書/画像分析
Section titled “文書/画像分析”| モデル | 用途 |
|---|---|
| Claude Sonnet 5 | ReActエージェント(推論 + ツール呼び出し判断) |
| Claude Sonnet 5(Vision) | 画像分析ツール(ツール内部で画像と質問を処理) |
analyze_image
Section titled “analyze_image”文書画像に対して特定の質問を投げかけて分析します。Claude Sonnet 5のVision機能を使用して画像を直接確認し回答します。
@tooldef analyze_image(question: str) -> str: """文書画像を特定の質問で分析します。
テキスト内容、視覚的要素、ダイアグラム、テーブルなどについて ターゲット質問を投げかけて分析します。 """質問例:
- 「この文書のタイプと全体構造を説明して」
- 「テーブルに含まれる全データを抽出して」
- 「技術図面に表示された寸法と仕様を読み取って」
- 「チャートのデータポイントとトレンドを分析して」
rotate_image
Section titled “rotate_image”文書画像が回転している場合に補正します。
@tooldef rotate_image(degrees: int) -> str: """現在の文書画像を指定された角度で回転します。
テキストが逆さま、横向き、または斜めに表示されている場合に使用します。 """分析プロセス
Section titled “分析プロセス”入力:画像 + OCRテキスト + BDA結果(オプション) + PDFテキスト(PDFのみ) ↓[ステップ1] 向き確認 → 必要に応じてrotate_imageで補正 ↓[ステップ2] 文書概要 → analyze_image("この文書のタイプは?") ↓[ステップ3] テキスト抽出 → analyze_image("全テキストを抽出して") ↓[ステップ4] テーブル/図表 → analyze_image("テーブルとチャートを分析して") ↓[ステップ5] 詳細 → analyze_image("技術仕様と寸法を抽出して") ↓最終統合 → 全ツール回答を統合して構造化された分析を作成映像/音声分析
Section titled “映像/音声分析”| モデル | 用途 |
|---|---|
| Claude Sonnet 5 | ReActエージェント(推論 + ツール呼び出し判断) |
| TwelveLabs Pegasus 1.2 | 映像分析ツール(ツール内部で映像を直接分析) |
analyze_video
Section titled “analyze_video”映像セグメントに対して特定の質問を投げかけて分析します。TwelveLabs Pegasus 1.2モデルがS3の映像を直接視聴して分析します。
@tooldef analyze_video(question: str) -> str: """映像セグメントを特定の質問で分析します。
視覚的コンテンツ、動作、シーン、オブジェクト、人物、テキストオーバーレイなどについて ターゲット質問を投げかけて分析します。 """質問例:
- 「この映像でどのような動作が行われているか?」
- 「画面に表示される主要なオブジェクトと人物を説明して」
- 「画面に表示されるテキストを読み取って」
- 「このセグメントのキーイベントは何か?」
Pegasusモデル呼び出し
Section titled “Pegasusモデル呼び出し”{ "inputPrompt": "この映像セグメントでどのような動作が行われているか?", "mediaSource": { "s3Location": { "uri": "s3://bucket/projects/p1/documents/d1/video.mp4", "bucketOwner": "123456789012" } }}PegasusはS3の映像ファイルを直接分析し、BDAが抽出したチャプター情報(タイムコード)に基づいてセグメントが分割されます。
分析プロセス
Section titled “分析プロセス”入力:映像URI + Transcribe結果 + BDAチャプター要約(オプション) + タイムコード ↓[ステップ1] コンテンツ概要 → analyze_video("主要コンテンツを説明して") ↓[ステップ2] 視覚的要素 → analyze_video("どのような動作とオブジェクトが見えるか?") ↓[ステップ3] 音声内容 → analyze_video("発話内容を要約して") ↓[ステップ4] キーイベント → analyze_video("キーイベントは何か?") ↓最終統合 → Transcribe + Pegasus回答を統合してタイムラインベース分析を作成文書 vs 映像比較
Section titled “文書 vs 映像比較”| 項目 | 文書/画像 | 映像/音声 |
|---|---|---|
| セグメントタイプ | PAGE | CHAPTER, VIDEO, AUDIO |
| 入力データ | 画像URI | 映像URI + タイムコード |
| 前処理データ | OCR + BDA(オプション) + PDFテキスト | Transcribe + BDA(オプション) |
| エージェントモデル | Claude Sonnet 5 | Claude Sonnet 5 |
| 分析ツールモデル | Claude Sonnet 5(Vision) | TwelveLabs Pegasus 1.2 |
| ツール | analyze_image, rotate_image | analyze_video |
| 分析フォーカス | テキスト、テーブル、ダイアグラム、レイアウト | 動作、シーン、音声、視覚的イベント |
Document Summarizer
Section titled “Document Summarizer”全セグメント分析完了後、Document Summarizerが文書全体の要約を生成します。
| 項目 | 値 |
|---|---|
| モデル | Claude Haiku 4.5(claude-4-5-haiku) |
| 入力 | 全セグメントのAI分析結果(最大50,000文字) |
| 出力 | 構造化された文書要約 |
要約構造: 1. 文書概要(1〜2文) 2. 主要発見事項(3〜5項目) 3. 重要データポイント 4. 結論Claude Haikuを使用する理由:深層分析はSegment Analyzerで既に完了しているため、要約ステップでは高速かつコスト効率的なモデルで十分です。
分析結果保存
Section titled “分析結果保存”各ツール呼び出しの結果はai_analysis配列に順次保存されます。
{ "ai_analysis": [ { "analysis_query": "この文書のタイプと構造は?", "content": "この文書は技術仕様書で..." }, { "analysis_query": "テーブルのデータを抽出して", "content": "テーブルには以下の項目が含まれています..." } ]}分析完了後、Analysis Finalizerがcontent_combined(全分析結果統合)を生成し、SQSを通じてLanceDB Writerに送信します。LanceDB WriterはNova Embedでベクトル埋め込みを実行しLanceDBに保存します。
多言語サポート
Section titled “多言語サポート”Segment Analyzerはプロジェクト設定言語に応じて分析結果を該当言語で生成します。韓国語、英語、日本語、中国語をサポートしています。
既に分析されたセグメントをカスタム指示で再分析できます。再分析時、プロジェクトデフォルトプロンプトの代わりにユーザー指定の指示が適用されます。