배포 옵션¶
구성 방법¶
GenU를 사용하면 parameter.ts 또는 AWS CDK context를 통해 설정을 변경할 수 있습니다.
여러 환경에 대한 설정을 정의할 수 있으므로 새 환경을 구축할 때는 parameter.ts를 사용하는 것을 권장합니다. 하위 호환성을 위해 매개변수는 context > parameter.ts 순서로 검색됩니다.
Context 사용 시: CDK context는 '-c'로 지정할 수 있지만, 코드 변경이 없으므로 프론트엔드 빌드가 트리거되지 않습니다. 이 자산의 경우 cdk.json에서 모든 설정을 변경하는 것을 권장합니다.
parameter.ts 값 변경 방법¶
packages/cdk/parameter.ts의 값을 변경하여 설정을 구성합니다.
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
ragEnabled: false,
// 필요에 따라 다른 매개변수 사용자 정의
},
staging: {
ragEnabled: false,
// 필요에 따라 다른 매개변수 사용자 정의
},
prod: {
ragEnabled: true,
// 필요에 따라 다른 매개변수 사용자 정의
},
};
CDK context의 env로 지정된 환경이 parameter.ts에 정의되어 있으면 parameter.ts의 값이 우선됩니다. 지정된 env 환경이 parameter.ts에 정의되지 않은 경우 context 값으로 환경이 생성됩니다.
packages/cdk/cdk.json의 context에서 env를 지정하거나 -c로 env를 전환할 수 있습니다.
// cdk.json
{
"context": {
"env": "dev"
}
}
# cdk.json context.env에 지정된 env로 배포
npm run cdk:deploy
# 환경을 prod로 설정하여 배포
npm run cdk:deploy -- -c env=prod
로컬에서 개발할 때는 다음과 같이 env를 지정합니다:
# cdk.json context.env에 지정된 백엔드를 사용하여 로컬 개발
npm run web:devw
# dev2 환경 백엔드를 사용하여 로컬 개발
npm run web:devw --env=dev2
cdk.json 값 변경 방법¶
packages/cdk/cdk.json의 context 아래 값을 변경하여 설정을 구성합니다. 예를 들어, "ragEnabled": true로 설정하면 RAG 채팅 사용 사례가 활성화됩니다. context 값을 설정한 후 다음 명령으로 재배포하여 설정을 적용합니다:
npm run cdk:deploy
사용 사례 구성¶
RAG Chat (Amazon Kendra) 사용 사례 활성화¶
ragEnabled를 true로 설정합니다. (기본값은 false)
검색 성능을 향상시킬 수 있는 선호 언어로 kendraIndexLanguage를 설정할 수도 있습니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
ragEnabled: true,
kendraIndexLanguage: 'en',
},
};
// cdk.json
{
"context": {
"ragEnabled": true,
"kendraIndexLanguage": "en"
}
}
}
변경 후 npm run cdk:deploy로 재배포하여 변경사항을 적용합니다. /packages/cdk/rag-docs/docs에 저장된 데이터는 Kendra 데이터 소스용 S3 버킷에 자동으로 업로드됩니다. (logs로 시작하는 파일은 동기화되지 않습니다.)
Note
기본적으로 Amazon Bedrock 사용자 가이드(일본어)와 Amazon Nova 사용자 가이드(영어)가 샘플 데이터로 /packages/cdk/rag-docs/docs에 저장되어 있습니다.
다음으로 다음 단계에 따라 Kendra 데이터 소스 동기화를 수행합니다:
- Amazon Kendra 콘솔 열기
- generative-ai-use-cases-index 클릭
- Data sources 클릭
- "s3-data-source" 클릭
- Sync now 클릭
Sync run history의 Status / Summary가 Completed로 표시되면 프로세스가 완료됩니다. S3에 저장된 파일이 동기화되어 Kendra를 통해 검색할 수 있습니다.
기존 Amazon Kendra 인덱스 사용¶
기존 Kendra 인덱스를 사용할 때는 ragEnabled가 여전히 true여야 합니다.
kendraIndexArn에 인덱스 ARN을 지정합니다. 기존 Kendra 인덱스와 함께 S3 데이터 소스를 사용하는 경우 kendraDataSourceBucketName에 버킷 이름을 지정합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
kendraIndexArn: '<Kendra Index ARN>',
kendraDataSourceBucketName: '<Kendra S3 Data Source Bucket Name>',
},
};
// cdk.json
{
"context": {
"kendraIndexArn": "<Kendra Index ARN>",
"kendraDataSourceBucketName": "<Kendra S3 Data Source Bucket Name>"
}
}
변경 후 npm run cdk:deploy로 재배포하여 변경사항을 적용합니다.
<Kendra Index ARN>은 다음 형식을 가집니다:
arn:aws:kendra:<Region>:<AWS Account ID>:index/<Index ID>
예를 들어:
arn:aws:kendra:ap-northeast-1:333333333333:index/77777777-3333-4444-aaaa-111111111111
RAG Chat (Knowledge Base) 사용 사례 활성화¶
ragKnowledgeBaseEnabled를 true로 설정합니다. (기본값은 false)
기존 Knowledge Base가 있는 경우 ragKnowledgeBaseId를 지식 베이스 ID로 설정합니다. (null인 경우 OpenSearch Serverless 지식 베이스가 생성됩니다)
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
ragKnowledgeBaseEnabled: true,
ragKnowledgeBaseId: 'XXXXXXXXXX',
ragKnowledgeBaseStandbyReplicas: false,
ragKnowledgeBaseAdvancedParsing: false,
ragKnowledgeBaseAdvancedParsingModelId:
'anthropic.claude-3-sonnet-20240229-v1:0',
embeddingModelId: 'amazon.titan-embed-text-v2:0',
},
};
// cdk.json
{
"context": {
"ragKnowledgeBaseEnabled": true,
"ragKnowledgeBaseId": "XXXXXXXXXX",
"ragKnowledgeBaseStandbyReplicas": false,
"ragKnowledgeBaseAdvancedParsing": false,
"ragKnowledgeBaseAdvancedParsingModelId": "anthropic.claude-3-sonnet-20240229-v1:0",
"embeddingModelId": "amazon.titan-embed-text-v2:0",
"rerankingModelId": "amazon.rerank-v1:0",
"queryDecompositionEnabled": true
}
}
ragKnowledgeBaseStandbyReplicas는 자동으로 생성되는 OpenSearch Serverless의 중복성과 관련됩니다:
false: 개발 및 테스트 목적에 적합합니다. 단일 AZ에서 실행되어 OCU 비용이 절반으로 줄어듭니다.true: 프로덕션 환경에 적합합니다. 여러 AZ에서 실행되어 고가용성을 제공합니다.
embeddingModelId는 임베딩에 사용되는 모델입니다. 현재 다음 모델이 지원됩니다:
"amazon.titan-embed-text-v1"
"amazon.titan-embed-text-v2:0"
"cohere.embed-multilingual-v3"
"cohere.embed-english-v3"
rerankingModelId는 재순위에 사용되는 모델입니다. 현재 다음 모델이 지원됩니다: (기본값은 null)
"amazon.rerank-v1:0"
"cohere.rerank-v3-5:0"
queryDecompositionEnabled는 쿼리 분해를 활성화합니다. (기본값은 false)
변경 후 npm run cdk:deploy로 재배포하여 변경사항을 적용합니다. Knowledge Base는 modelRegion에 지정된 지역에 배포됩니다. 다음 사항에 유의하세요:
modelRegion지역의modelIds에 최소 하나의 모델이 정의되어야 합니다.embeddingModelId모델이modelRegion지역의 Bedrock에서 활성화되어야 합니다.rerankingModelId모델이modelRegion지역의 Bedrock에서 활성화되어야 합니다.npm run cdk:deploy를 실행하기 전에modelRegion지역에서 AWS CDK Bootstrap이 완료되어야 합니다.
# Bootstrap 명령 예제 (modelRegion이 us-east-1인 경우)
npx -w packages/cdk cdk bootstrap --region us-east-1
배포 중에 /packages/cdk/rag-docs/docs에 저장된 데이터는 Knowledge Base 데이터 소스용 S3 버킷에 자동으로 업로드됩니다. (logs로 시작하는 파일은 동기화되지 않습니다.)
Note
기본적으로 Amazon Bedrock 사용자 가이드(일본어)와 Amazon Nova 사용자 가이드(영어)가 샘플 데이터로 /packages/cdk/rag-docs/docs에 저장되어 있습니다.
배포가 완료된 후 다음 단계에 따라 Knowledge Base 데이터 소스를 동기화합니다:
- Knowledge Base 콘솔 열기
- generative-ai-use-cases-jp 클릭
- s3-data-source를 선택하고 Sync 클릭
- web-crawler-data-source를 선택하고 Sync 클릭
각 데이터 소스의 Status가 Available이 되면 프로세스가 완료됩니다. S3에 저장된 파일과 Web Crawler로 가져온 웹 페이지가 수집되어 Knowledge Base를 통해 검색할 수 있습니다.
Note
RAG Chat (Knowledge Base)를 활성화한 후 다시 비활성화하려면 ragKnowledgeBaseEnabled: false로 설정하고 재배포합니다. 이렇게 하면 RAG Chat (Knowledge Base)가 비활성화되지만 RagKnowledgeBaseStack 자체는 남아있습니다. 완전히 제거하려면 관리 콘솔을 열고 modelRegion의 CloudFormation에서 RagKnowledgeBaseStack 스택을 삭제하세요.
고급 파싱 활성화¶
고급 파싱 기능을 활성화할 수 있습니다. 고급 파싱은 파일의 테이블과 그래프와 같은 비구조화된 데이터에서 정보를 분석하고 추출하는 기능입니다. 파일의 텍스트 외에 테이블과 그래프에서 추출된 데이터를 추가하여 RAG 정확도를 향상시킬 수 있습니다.
ragKnowledgeBaseAdvancedParsing: 고급 파싱을 활성화하려면true로 설정ragKnowledgeBaseAdvancedParsingModelId: 정보 추출에 사용되는 모델 ID 지정- 지원되는 모델 (2024/08 기준)
anthropic.claude-3-sonnet-20240229-v1:0anthropic.claude-3-haiku-20240307-v1:0
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
ragKnowledgeBaseEnabled: true,
ragKnowledgeBaseId: 'XXXXXXXXXX',
ragKnowledgeBaseStandbyReplicas: false,
ragKnowledgeBaseAdvancedParsing: true,
ragKnowledgeBaseAdvancedParsingModelId:
'anthropic.claude-3-sonnet-20240229-v1:0',
embeddingModelId: 'amazon.titan-embed-text-v2:0',
},
};
// cdk.json
{
"context": {
"ragKnowledgeBaseEnabled": true,
"ragKnowledgeBaseId": "XXXXXXXXXX",
"ragKnowledgeBaseStandbyReplicas": false,
"ragKnowledgeBaseAdvancedParsing": true,
"ragKnowledgeBaseAdvancedParsingModelId": "anthropic.claude-3-sonnet-20240229-v1:0",
"embeddingModelId": "amazon.titan-embed-text-v2:0"
}
}
청킹 전략 변경¶
rag-knowledge-base-stack.ts에는 chunkingConfiguration을 지정하는 섹션이 있습니다. 주석을 해제하고 CDK 문서 또는 CloudFormation 문서를 참조하여 원하는 청킹 전략으로 변경하세요.
예를 들어, 의미적 청킹으로 변경하려면 주석을 해제하고 다음과 같이 지정합니다:
// packages/cdk/lib/rag-knowledge-base-stack.ts
// 의미적 청킹
chunkingConfiguration: {
chunkingStrategy: 'SEMANTIC',
semanticChunkingConfiguration: {
maxTokens: 300,
bufferSize: 0,
breakpointPercentileThreshold: 95,
},
},
그런 다음 변경사항 적용을 위한 Knowledge Base 또는 OpenSearch Service 재생성 장을 참조하여 변경사항을 적용합니다.
변경사항 적용을 위한 Knowledge Base 또는 OpenSearch Service 재생성¶
Knowledge Base 청킹 전략 또는 다음 OpenSearch Service 매개변수의 경우, 변경 후 npm run cdk:deploy를 실행해도 변경사항이 반영되지 않습니다:
embeddingModelIdragKnowledgeBaseStandbyReplicasragKnowledgeBaseAdvancedParsingragKnowledgeBaseAdvancedParsingModelId
변경사항을 적용하려면 다음 단계에 따라 기존 Knowledge Base 관련 리소스를 삭제하고 재생성합니다:
ragKnowledgeBaseEnabled를 false로 설정하고 배포- CloudFormation 열기 (지역 확인), RagKnowledgeBaseStack 클릭
- 우측 상단의 Delete를 클릭하여 RagKnowledgeBaseStack 삭제
이렇게 하면 S3 버킷과 RAG 파일이 삭제되어 일시적으로 RAG 채팅을 사용할 수 없게 됩니다 - 매개변수 또는 청킹 전략 변경
- RagKnowledgeBaseStack 삭제가 완료된 후
npm run cdk:deploy로 재배포
RagKnowledgeBaseStack 삭제와 함께 RAG 채팅용 S3 버킷과 그 안에 저장된 RAG 파일이 삭제됩니다. S3 버킷에 RAG 파일을 업로드한 경우 백업하고 재배포 후 다시 업로드하세요. 또한 앞서 언급한 단계에 따라 데이터 소스 (s3-data-source, web-crawler-data-source)를 다시 동기화하세요.
관리 콘솔에서 OpenSearch Service 인덱스 확인 방법¶
기본적으로 관리 콘솔에서 OpenSearch Service의 Indexes 탭을 열면 User does not have permissions for the requested resource라는 오류 메시지가 표시됩니다.
이는 데이터 액세스 정책이 관리 콘솔에 로그인한 IAM 사용자를 허용하지 않기 때문입니다.
다음 단계에 따라 필요한 권한을 수동으로 추가하세요:
- OpenSearch Service 열기 (지역 확인), generative-ai-use-cases-jp 클릭
- 페이지 하단의 generative-ai-use-cases-jp라는 Associated policy 클릭
- 우측 상단의 Edit 클릭
- 페이지 중간의 Select principals 섹션에서 Add principals 클릭, IAM User/Role 등 (관리 콘솔에 로그인한 권한) 추가
- Save
저장 후 잠시 기다린 다음 다시 액세스해 보세요.
메타데이터 필터 구성¶
필터 설정은 packages/common/src/custom/rag-knowledge-base.ts에서 구성할 수 있습니다. 필요에 따라 사용자 정의하세요.
dynamicFilters: 애플리케이션 측에서 동적으로 필터를 생성하고 적용합니다. (예: 부서와 같은 사용자 속성을 기반으로 필터 생성 및 적용) 현재 Claude Sonnet 3.5만 지원합니다. (할당량으로 인해 스로틀링이 발생할 수 있음) Cognito Groups 또는 SAML IdP Groups를 Attributes에 매핑하여 사용할 수도 있습니다. (자세한 내용은 Microsoft Entra ID와 SAML 통합 참조)implicitFilters: 지정된 경우 LLM이 사용자 질문을 기반으로 지정된 메타데이터에 대한 필터를 생성하고 적용합니다. (예: 사용자 질문에 언급된 연도로 필터링하여 해당 연도의 데이터만 검색) 빈 배열인 경우 필터가 적용되지 않습니다.hiddenStaticExplicitFilters: 애플리케이션 수준에서 필터를 적용합니다. (예: 기밀로 분류된 데이터 제외)userDefinedExplicitFilters: 애플리케이션 UI에 표시되는 필터를 정의합니다.
Agent Chat 사용 사례 활성화¶
Agent Chat 사용 사례에서는 다음을 수행할 수 있습니다:
- 데이터 시각화, 코드 실행, 데이터 분석을 위한 Code Interpreter 사용
- Amazon Bedrock용 Agents를 사용한 작업 실행
- Amazon Bedrock용 Knowledge Bases의 벡터 데이터베이스 참조
Agents는 modelRegion에 지정된 지역에 생성됩니다. 아래에 언급된 agentEnabled: true 옵션은 Code Interpreter 에이전트와 검색 에이전트를 생성하기 위한 것입니다. 수동으로 생성된 Agents를 추가할 때는 agentEnabled: true가 필요하지 않습니다.
Code Interpreter Agent 배포¶
Code Interpreter를 사용하여 데이터 시각화, 코드 실행, 데이터 분석 등을 수행할 수 있습니다.
Code Interpreter 에이전트는 Agent를 활성화할 때 배포됩니다.
agentEnabled를 true로 설정합니다. (기본값은 false)
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
agentEnabled: true,
},
};
// cdk.json
{
"context": {
"agentEnabled": true
}
}
에이전트 기반 모델 사용자 정의¶
Code Interpreter 및 Search Agent에서 사용하는 기반 모델을 사용자 정의할 수 있습니다. 기본적으로 global.anthropic.claude-sonnet-4-6이 사용됩니다.
agentFoundationModel: 에이전트에 사용할 모델을 지정합니다. Bedrock Agent가 지원하는 모델만 사용할 수 있습니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
agentFoundationModel: 'global.anthropic.claude-sonnet-4-6',
},
};
// cdk.json
{
"context": {
"agentFoundationModel": "global.anthropic.claude-sonnet-4-6"
}
}
Search Agent 배포¶
API에 연결하여 최신 정보를 참조하여 응답하는 Agent를 생성합니다. Agent를 사용자 정의하여 다른 작업을 추가하고 여러 Agent를 생성하여 전환할 수 있습니다.
사용 가능한 기본 검색 에이전트는 Brave Search API의 Data for AI 또는 Tavily의 Tavily Search API입니다. 다른 API와 함께 사용할 수 있도록 API를 사용자 정의하는 것도 가능합니다. Brave Search API는 무료 플랜에서도 신용카드 설정이 필요합니다.
Note
Agent Chat 사용 사례를 활성화하면 Agent Chat 사용 사례에서만 외부 API로 데이터를 전송합니다. (기본적으로 Brave Search API 또는 Tavily Search) 다른 사용 사례는 AWS 내에서 완전히 계속 사용할 수 있습니다. 활성화하기 전에 내부 정책과 API 서비스 약관을 확인하세요.
agentEnabled와 searchAgentEnabled를 true로 설정하고 (기본값은 false) 필수 필드를 설정합니다.
searchEngine: 사용할 검색 엔진을 지정합니다.Brave또는Tavily를 사용할 수 있습니다.searchApiKey: 검색 엔진의 API 키를 지정합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
agentEnabled: true,
searchAgentEnabled: true,
searchEngine: 'Brave' or 'Tavily',
searchApiKey: '<Search Engine API Key>',
},
};
// cdk.json
{
"context": {
"agentEnabled": true,
"searchAgentEnabled": true,
"searchEngine": "Brave" or "Tavily",
"searchApiKey": "<Search Engine API Key>"
}
}
변경 후 npm run cdk:deploy로 재배포하여 변경사항을 적용합니다. 이렇게 하면 기본 검색 엔진 Agent가 배포됩니다.
Note
검색 에이전트를 활성화한 후 비활성화하려면 searchAgentEnabled: false로 설정하고 재배포합니다. 이렇게 하면 검색 에이전트가 비활성화되지만 WebSearchAgentStack 자체는 남아있습니다. 완전히 제거하려면 관리 콘솔을 열고 modelRegion의 CloudFormation에서 WebSearchAgentStack 스택을 삭제하세요.
수동으로 생성된 Agents 추가¶
기본 Agents 외에 수동으로 생성된 Agents를 등록하려면 agents에 추가 Agents를 추가합니다. Agents는 modelRegion에 생성되어야 합니다.
[!NOTE] >
agentEnabled: true는 Code Interpreter 에이전트와 검색 에이전트를 생성하는 옵션이므로 수동으로 생성된 Agents를 추가할 때는 필요하지 않습니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
agents: [
{
displayName: 'MyCustomAgent',
agentId: 'XXXXXXXXX',
aliasId: 'YYYYYYYY',
},
],
},
};
// cdk.json
{
"context": {
"agents": [
{
"displayName": "MyCustomAgent",
"agentId": "XXXXXXXXX",
"aliasId": "YYYYYYYY"
}
]
}
}
packages/cdk/lib/construct/agent.ts를 수정하여 새 Agents를 정의할 수도 있습니다. CDK에서 정의된 Agents를 사용하는 경우 agentEnabled: true로 설정합니다.
Amazon Bedrock Agent용 Knowledge Bases 배포¶
Amazon Bedrock용 Knowledge Bases와 통합되는 에이전트를 수동으로 생성하고 등록할 수도 있습니다.
먼저 Amazon Bedrock용 Knowledge Bases 문서를 참조하여 지식 베이스 AWS 콘솔에서 지식 베이스를 생성합니다. modelRegion과 동일한 지역에 생성합니다.
다음으로 에이전트 AWS 콘솔에서 Agent를 수동으로 생성합니다. 설정은 대부분 기본값으로 유지하고, Agent 프롬프트에는 아래 예제를 참조하여 프롬프트를 입력합니다. 작업 그룹은 설정하지 않고 진행하여 이전 단계에서 생성한 지식 베이스를 등록하고 아래 예제를 참조하여 프롬프트를 입력합니다.
Agent 프롬프트 예제: 당신은 지시에 응답하는 어시스턴트입니다. 지시에 따라 정보를 검색하고 내용을 바탕으로 적절히 응답하세요. 정보에 언급되지 않은 것에 대해서는 답변하지 마세요. 여러 번 검색할 수 있습니다.
Knowledge Base 프롬프트 예제: 키워드로 검색하여 정보를 얻습니다. 연구, X에 대해 묻기, 요약과 같은 작업에 사용할 수 있습니다. 대화에서 검색 키워드를 추측하세요. 검색 결과에는 관련성이 낮은 내용이 포함될 수 있으므로 답변할 때는 관련성이 높은 내용만 참조하세요. 여러 번 실행할 수 있습니다.
생성된 Agent에서 Alias를 생성하고 agentId와 aliasId를 복사하여 다음 형식으로 추가합니다. displayName을 UI에 표시할 이름으로 설정합니다. 또한 agentEnabled를 true로 설정합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
agentEnabled: true,
agents: [
{
displayName: 'Knowledge Base',
agentId: 'XXXXXXXXX',
aliasId: 'YYYYYYYY',
},
],
},
};
// cdk.json
{
"context": {
"agentEnabled": true,
"agents": [
{
"displayName": "Knowledge Base",
"agentId": "XXXXXXXXX",
"aliasId": "YYYYYYYY"
}
]
}
}
Agents 인라인 표시¶
기본적으로 Agents는 "Agent Chat" 사용 사례 내에서 선택할 수 있습니다. 인라인 표시 옵션을 활성화하면 "Agent Chat" 사용 사례가 더 이상 표시되지 않고 사용 가능한 모든 Agents가 다른 사용 사례처럼 표시됩니다. 유효한 Agents가 있을 때 inlineAgents를 true로 설정합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
inlineAgents: true,
},
};
// cdk.json
{
"context": {
"inlineAgents": true
}
}
리서치 에이전트 유스케이스 활성화¶
리서치 에이전트는 웹 검색 및 AWS 문서 검색을 활용한 고급 리서치 기능을 제공합니다.
전제 조건¶
- Brave Search API 키 (필수): AWS Marketplace에서 획득
- Tavily API 키 (선택 사항): 추가 검색 기능을 사용하는 경우
Tip
Brave Search API 키 획득 방법은 리서치 에이전트 배포 가이드를 참조하세요.
parameter.ts 설정 예시¶
const envs: Record<string, Partial<StackInput>> = {
dev: {
researchAgentEnabled: true,
researchAgentBraveApiKey: 'YOUR_BRAVE_API_KEY',
researchAgentTavilyApiKey: '', // 선택 사항
},
};
cdk.json 설정 예시¶
{
"context": {
"researchAgentEnabled": true,
"researchAgentBraveApiKey": "YOUR_BRAVE_API_KEY",
"researchAgentTavilyApiKey": ""
}
}
자세한 절차는 리서치 에이전트 배포 가이드를 참조하세요.
MCP Chat 사용 사례 활성화¶
Warning
MCP Chat 사용 사례는 사용 중단되었습니다. MCP 활용을 위해서는 AgentCore 사용 사례를 사용하세요. MCP 채팅 사용 사례는 v6에서 완전히 제거될 예정입니다.
MCP (Model Context Protocol)는 LLM 모델을 외부 데이터 및 도구와 연결하는 프로토콜입니다.
GenU에서는 Strands Agents를 사용하여 MCP 호환 도구를 실행하는 채팅 사용 사례를 제공합니다.
MCP 채팅 사용 사례를 활성화하려면 docker 명령을 실행할 수 있어야 합니다.
parameter.ts 편집
const envs: Record<string, Partial<StackInput>> = {
dev: {
mcpEnabled: true,
},
};
// cdk.json
{
"context": {
"mcpEnabled": true
}
}
사용할 MCP 서버는 packages/cdk/mcp-api/mcp.json에 정의됩니다. 기본적으로 정의된 것 외에 다른 도구를 추가하려면 mcp.json을 수정하세요.
하지만 현재 MCP 서버와 그 구성에는 다음과 같은 제약이 있습니다:
- MCP 서버는 AWS Lambda에서 실행되므로 파일 쓰기가 불가능합니다. (
/tmp에 쓰기는 가능하지만 파일을 검색할 수 없습니다.) - MCP 서버는
uvx또는npx로 실행 가능해야 합니다. - MCP 클라이언트는 stdio만 사용할 수 있습니다.
- 현재 멀티모달 요청은 지원되지 않습니다.
- API 키를 동적으로 얻어 환경 변수로 설정하는 메커니즘이 아직 구현되지 않았습니다.
- 사용자가 사용할 MCP 서버를 선택하는 메커니즘이 아직 구현되지 않았습니다. (현재 mcp.json에 정의된 모든 도구가 사용됩니다.)
- mcp.json에서
command,args,env를 구성할 수 있습니다. 구체적인 예제는 다음과 같습니다:
{
"mcpServers": {
"SERVER_NAME": {
"command": "uvx",
"args": ["SERVER_ARG"]
"env": {
"YOUR_API_KEY": "xxx"
}
}
}
}
Flow Chat 사용 사례 활성화¶
Flow Chat 사용 사례에서는 생성된 Flows를 호출할 수 있습니다.
flows 배열을 추가하거나 편집합니다.
Amazon Bedrock Flows AWS 콘솔에서 Flows를 수동으로 생성합니다. 그런 다음 Alias를 생성하고 생성된 Flow의 flowId, aliasId, flowName을 추가합니다. description에는 사용자 입력을 유도하는 설명을 작성합니다. 이 설명은 Flow 채팅 텍스트 상자에 표시됩니다. 예제는 다음과 같습니다:
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
flows: [
{
flowId: 'XXXXXXXXXX',
aliasId: 'YYYYYYYYYY',
flowName: 'WhatIsItFlow',
description:
'This flow searches the web for any keyword and returns an explanation. Please enter text',
},
],
},
};
// cdk.json
{
"context": {
"flows": [
{
"flowId": "XXXXXXXXXX",
"aliasId": "YYYYYYYYYY",
"flowName": "WhatIsItFlow",
"description": "This flow searches the web for any keyword and returns an explanation. Please enter text"
},
{
"flowId": "ZZZZZZZZZZ",
"aliasId": "OOOOOOOOOO",
"flowName": "RecipeFlow",
"description": "Creates a recipe based on the given JSON.\nPlease enter like {\"dish\": \"curry rice\", \"people\": 3}."
},
{
"flowId": "PPPPPPPPPP",
"aliasId": "QQQQQQQQQQQ",
"flowName": "TravelPlanFlow",
"description": "Creates a travel plan based on the given array.\nPlease enter like [{\"place\": \"Tokyo\", \"day\": 3}, {\"place\": \"Osaka\", \"day\": 2}]."
}
]
}
}
AgentCore 사용 사례 활성화¶
AgentCore에서 생성된 에이전트와 통합하는 사용 사례입니다. (실험적: 예고 없이 주요 변경사항이 있을 수 있습니다)
createGenericAgentCoreRuntime을 활성화하면 기본 AgentCore Runtime이 배포됩니다.
기본적으로 modelRegion에 배포되지만 agentCoreRegion을 지정하여 이를 재정의할 수 있습니다.
AgentCore에서 사용 가능한 기본 에이전트는 mcp.json에 정의된 MCP 서버를 활용할 수 있습니다.
기본적으로 정의된 MCP 서버는 AWS 관련 MCP 서버와 현재 시간 관련 MCP 서버입니다.
자세한 내용은 여기 문서를 참조하세요.
MCP 서버를 추가할 때는 앞서 언급한 mcp.json에 추가하세요.
그러나 uvx 이외의 방법으로 시작하는 MCP 서버는 Dockerfile 재작성과 같은 개발 작업이 필요합니다.
agentCoreExternalRuntimes를 사용하면 외부에서 생성된 AgentCore Runtime을 사용할 수 있습니다.
각 항목에는 다음 필드를 지정할 수 있습니다.
name(필수): 런타임의 식별자. AgentCore Runtime의 이름은 영숫자와 언더스코어만 사용할 수 있습니다.arn(필수): AgentCore Runtime의 ARN.display_name(선택): UI에 표시되는 이름.name을 변경하지 않고 한국어 등 더 알기 쉬운 표시명을 설정할 수 있습니다.description(필수): 에이전트의 설명. 에이전트 목록 화면과 채팅 화면 상단에 표시되어 사용자가 각 에이전트의 역할을 한눈에 파악할 수 있습니다.
AgentCore 사용 사례를 활성화하려면 docker 명령을 실행할 수 있어야 합니다.
Warning
x86_64 CPU(Intel, AMD 등)를 사용하는 Linux 머신에서는 cdk 배포 전에 다음 명령을 실행하세요:
docker run --privileged --rm tonistiigi/binfmt --install arm64
위 명령을 실행하지 않으면 다음 오류가 발생합니다:
배포 과정에서 AgentCore Runtime에서 사용하는 ARM 기반 컨테이너 이미지가 빌드됩니다. x86_64 CPU에서 ARM 컨테이너 이미지를 빌드할 때 CPU 아키텍처 차이로 인해 오류가 발생합니다.
ERROR: failed to solve: process "/bin/sh -c apt-get update -y && apt-get install curl nodejs npm graphviz -y" did not complete successfully: exit code: 255
AgentCoreStack: fail: docker build --tag cdkasset-64ba68f71e3d29f5b84d8e8d062e841cb600c436bb68a540d6fce32fded36c08 --platform linux/arm64 . exited with error code 1: #0 building with "default" instance using docker driver
이 명령을 실행하면 호스트 Linux 커널에 임시 구성 변경이 이루어집니다. Binary Format Miscellaneous (binfmt_misc)에 QEMU 에뮬레이터 사용자 정의 핸들러를 등록하여 ARM 컨테이너 이미지 빌드를 가능하게 합니다. 구성은 재부팅 후 원래 상태로 돌아가므로 재배포 전에 명령을 다시 실행해야 합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
createGenericAgentCoreRuntime: true,
agentCoreRegion: 'us-west-2',
agentCoreExternalRuntimes: [
{
name: 'AgentCore1',
display_name: '고객 지원 에이전트',
description: '고객 문의에 응대하는 에이전트입니다.',
arn: 'arn:aws:bedrock-agentcore:us-west-2:<account>:runtime/agent-core1-xxxxxxxx',
},
],
},
};
// cdk.json
{
"context": {
"createGenericAgentCoreRuntime": true,
"agentCoreRegion": "us-west-2",
"agentCoreExternalRuntimes": [
{
"name": "AgentCore1",
"display_name": "고객 지원 에이전트",
"description": "고객 문의에 응대하는 에이전트입니다.",
"arn": "arn:aws:bedrock-agentcore:us-west-2:<account>:runtime/agent-core1-xxxxxxxx"
}
]
}
}
Note
AgentCore 사용 사례 설정을 활성화한 후 다시 비활성화하려면 createGenericAgentCoreRuntime: false로 설정하고 재배포하면 AgentCore 사용 사례가 비활성화되지만 AgentCoreStack 자체는 남아있습니다. 관리 콘솔을 열고 agentCoreRegion의 CloudFormation에서 AgentCoreStack 스택을 삭제하여 완전히 제거할 수 있습니다.
AgentCore Runtime 네트워크 설정¶
AgentCore Runtime은 다음 네트워크 모드에서 작동할 수 있습니다:
PUBLIC(기본값): 퍼블릭 네트워크에서 작동PRIVATE: VPC 내 프라이빗 네트워크에서 작동
네트워크 설정은 Generic Runtime과 AgentBuilder Runtime 모두에 적용됩니다.
VPC 모드 사용 사례:
- AgentCore Runtime에서 사내 시스템이나 프라이빗 데이터베이스에 액세스해야 하는 경우
- 예를 들어, VPC 내의 다른 AWS 서비스(RDS, ElastiCache 등)와 직접 통신하고 싶은 경우
VPC 모드를 사용할 때는 다음 매개변수를 설정하세요:
agentCoreVpcId: 사용할 VPC IDagentCoreSubnetIds: 사용할 서브넷 ID 목록
Note
agentCoreVpcId와 agentCoreSubnetIds를 모두 설정하면 AgentCore Runtime이 프라이빗 네트워크 모드로 배포됩니다. 둘 다 미설정(null)인 경우 퍼블릭 네트워크 모드로 배포됩니다.
Important
가용 영역(AZ) 지원: AgentCore Runtime은 리전별로 지원되는 AZ가 제한되어 있습니다. 서브넷은 반드시 지원되는 AZ 내에 배치해야 합니다. 자세한 내용은 AWS 공식 문서를 확인하세요.
인터넷 액세스: AgentCore Runtime에서 MCP 서버 설치에는 인터넷 액세스가 필요합니다. 프라이빗 서브넷이 연결 대상인 경우 NAT Gateway 등 인터넷 도달 경로를 설정하세요.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
createGenericAgentCoreRuntime: true,
agentBuilderEnabled: true,
agentCoreVpcId: 'vpc-xxxxxxxxx',
agentCoreSubnetIds: ['subnet-xxxxxxxxx', 'subnet-yyyyyyyyy'],
},
};
// cdk.json
{
"context": {
"createGenericAgentCoreRuntime": true,
"agentBuilderEnabled": true,
"agentCoreVpcId": "vpc-xxxxxxxxx",
"agentCoreSubnetIds": ["subnet-xxxxxxxxx", "subnet-yyyyyyyyy"]
}
}
Warning
VPC 모드를 사용할 때, 예를 들어 PRIVATE에서 PUBLIC으로의 변경으로 인해 AgentCore Runtime 삭제 시 보안 그룹이 자동 삭제되지 않습니다. AgentCore Runtime이 생성하는 AWS 관리형 ENI가 보안 그룹을 참조하기 때문에 CloudFormation에서는 삭제할 수 없습니다. AgentCore Runtime 삭제 후 관리형 ENI가 자동 삭제될 때까지 기다린 다음 수동으로 보안 그룹을 삭제하세요. 삭제가 필요한 보안 그룹 ID는 CloudFormation 출력에 표시됩니다.
Voice Chat 사용 사례 활성화¶
Note
음성 채팅의 응답 속도는 애플리케이션의 지역(GenerativeAiUseCasesStack이 배포된 지역)에 크게 영향을 받습니다. 응답에 지연이 있는 경우 사용자가 애플리케이션의 지역과 물리적으로 가까운 곳에 있는지 확인하세요.
speechToSpeechModelIds에 하나 이상의 모델을 정의하면 활성화됩니다.
speechToSpeechModelIds에 대해서는 Amazon Bedrock 모델 변경을 참조하세요.
기본값은 packages/cdk/lib/stack-input.ts를 참조하세요.
Image Generation 사용 사례 활성화¶
imageGenerationModelIds에 하나 이상의 모델을 정의하면 활성화됩니다.
imageGenerationModelIds에 대해서는 Amazon Bedrock 모델 변경을 참조하세요.
기본값은 packages/cdk/lib/stack-input.ts를 참조하세요.
Video Generation 사용 사례 활성화¶
videoGenerationModelIds에 하나 이상의 모델을 정의하면 활성화됩니다.
videoGenerationModelIds에 대해서는 Amazon Bedrock 모델 변경을 참조하세요.
기본값은 packages/cdk/lib/stack-input.ts를 참조하세요.
Video Analysis 사용 사례 활성화¶
비디오 분석 사용 사례에서는 비디오 이미지 프레임과 텍스트를 입력하여 LLM이 이미지 내용을 분석하도록 합니다. 비디오 분석 사용 사례를 활성화하는 직접적인 옵션은 없지만 매개변수에서 멀티모달 모델이 활성화되어야 합니다.
2025/03 기준으로 멀티모달 모델은 다음과 같습니다:
"anthropic.claude-3-5-sonnet-20241022-v2:0",
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-opus-20240229-v1:0",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0",
"global.anthropic.claude-sonnet-4-20250514-v1:0",
"us.anthropic.claude-opus-4-1-20250805-v1:0",
"us.anthropic.claude-opus-4-20250514-v1:0",
"us.anthropic.claude-sonnet-4-20250514-v1:0",
"us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"us.anthropic.claude-3-5-sonnet-20240620-v1:0",
"us.anthropic.claude-3-opus-20240229-v1:0",
"us.anthropic.claude-3-sonnet-20240229-v1:0",
"us.anthropic.claude-3-haiku-20240307-v1:0",
"eu.anthropic.claude-sonnet-4-20250514-v1:0",
"eu.anthropic.claude-3-7-sonnet-20250219-v1:0",
"eu.anthropic.claude-3-5-sonnet-20240620-v1:0",
"eu.anthropic.claude-3-sonnet-20240229-v1:0",
"eu.anthropic.claude-3-haiku-20240307-v1:0",
"apac.anthropic.claude-sonnet-4-20250514-v1:0",
"apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
"apac.anthropic.claude-3-haiku-20240307-v1:0",
"apac.anthropic.claude-3-sonnet-20240229-v1:0",
"apac.anthropic.claude-3-5-sonnet-20240620-v1:0",
"apac.anthropic.claude-3-5-sonnet-20241022-v2:0",
"us.meta.llama4-maverick-17b-instruct-v1:0",
"us.meta.llama4-scout-17b-instruct-v1:0",
"us.meta.llama3-2-90b-instruct-v1:0",
"us.meta.llama3-2-11b-instruct-v1:0",
"us.mistral.pixtral-large-2502-v1:0",
"eu.mistral.pixtral-large-2502-v1:0",
"amazon.nova-pro-v1:0",
"amazon.nova-lite-v1:0",
"us.amazon.nova-premier-v1:0",
"us.amazon.nova-pro-v1:0",
"us.amazon.nova-lite-v1:0",
"eu.amazon.nova-pro-v1:0",
"eu.amazon.nova-lite-v1:0",
"apac.amazon.nova-pro-v1:0",
"apac.amazon.nova-lite-v1:0"
이 중 최소 하나는 modelIds에 정의되어야 합니다.
자세한 내용은 Amazon Bedrock 모델 변경을 참조하세요.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelIds: ['anthropic.claude-3-sonnet-20240229-v1:0'],
},
};
// cdk.json
{
"context": {
"modelIds": ["anthropic.claude-3-sonnet-20240229-v1:0"]
}
}
프롬프트 최적화 도구 활성화¶
프롬프트 최적화 도구는 입력 프롬프트를 지정된 모델에 최적화된 형태로 변환합니다. 프롬프트 최적화 도구를 활성화하는 직접적인 옵션은 없지만 매개변수 설정이 다음 두 조건을 충족해야 합니다:
modelRegion: Amazon Bedrock 프롬프트 최적화가 지원되는 지역modelIds: Amazon Bedrock 프롬프트 최적화에서 지원하는 모델이 최소 하나 지정됨
프롬프트 최적화 지원 상태는 이 링크를 참조하세요.
특정 사용 사례 숨기기¶
다음 옵션으로 사용 사례를 숨길 수 있습니다. 지정하지 않거나 false로 설정하면 사용 사례가 표시됩니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
hiddenUseCases: {
generate: true, // 텍스트 생성 숨기기
summarize: true, // 요약 숨기기
writer: true, // 글쓰기 숨기기
translate: true, // 번역 숨기기
webContent: true, // 웹 콘텐츠 추출 숨기기
image: true, // 이미지 생성 숨기기
video: true, // 비디오 생성 숨기기
videoAnalyzer: true, // 비디오 분석 숨기기
diagram: true, // 다이어그램 생성 숨기기
meetingMinutes: true, // 회의록 생성 숨기기
voiceChat: true, // 음성 채팅 숨기기
},
},
};
// cdk.json
{
"context": {
"hiddenUseCases": {
"generate": true,
"summarize": true,
"writer": true,
"translate": true,
"webContent": true,
"image": true,
"video": true,
"videoAnalyzer": true,
"diagram": true,
"meetingMinutes": true,
"voiceChat": true
}
}
}
Use Case Builder 구성¶
Use Case Builder는 기본적으로 활성화되어 있으며 배포 후 화면에 표시되는 "Builder Mode" 옵션에서 액세스할 수 있습니다. Use Case Builder를 비활성화하려면 매개변수 useCaseBuilderEnabled에 false를 지정합니다. (기본값은 true)
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
useCaseBuilderEnabled: false,
},
};
// cdk.json
{
"context": {
"useCaseBuilderEnabled": false
}
}
Amazon Bedrock 모델 변경¶
parameter.ts 또는 cdk.json에서 modelRegion, modelIds, imageGenerationModelIds, videoGenerationModelIds, speechToSpeechModelIds를 사용하여 모델 지역과 모델을 지정합니다. modelIds, imageGenerationModelIds, videoGenerationModelIds, speechToSpeechModelIds의 경우 지정된 지역에서 사용 가능한 모델 중에서 사용하려는 모델 목록을 지정합니다. AWS 문서에서 모델 목록과 지역별 모델 지원을 제공합니다.
이 솔루션은 교차 지역 추론 모델도 지원합니다. 교차 지역 추론 모델은 {us|eu|apac}.{model-provider}.{model-name}으로 표현되며 {us|eu|apac} 접두사가 modelRegion에 지정된 지역과 일치해야 합니다.
(예) modelRegion이 us-east-1인 경우 us.anthropic.claude-3-5-sonnet-20240620-v1:0은 가능하지만 eu.anthropic.claude-3-5-sonnet-20240620-v1:0은 불가능합니다.
이 솔루션은 다음 텍스트 생성 모델을 지원합니다:
"anthropic.claude-3-5-sonnet-20241022-v2:0",
"anthropic.claude-3-5-haiku-20241022-v1:0",
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-opus-20240229-v1:0",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0",
"global.anthropic.claude-sonnet-4-20250514-v1:0",
"us.anthropic.claude-opus-4-1-20250805-v1:0",
"us.anthropic.claude-opus-4-20250514-v1:0",
"us.anthropic.claude-sonnet-4-20250514-v1:0",
"us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"us.anthropic.claude-3-5-haiku-20241022-v1:0",
"us.anthropic.claude-3-5-sonnet-20240620-v1:0",
"us.anthropic.claude-3-opus-20240229-v1:0",
"us.anthropic.claude-3-sonnet-20240229-v1:0",
"us.anthropic.claude-3-haiku-20240307-v1:0",
"eu.anthropic.claude-sonnet-4-20250514-v1:0",
"eu.anthropic.claude-3-7-sonnet-20250219-v1:0",
"eu.anthropic.claude-3-5-sonnet-20240620-v1:0",
"eu.anthropic.claude-3-sonnet-20240229-v1:0",
"eu.anthropic.claude-3-haiku-20240307-v1:0",
"apac.anthropic.claude-sonnet-4-20250514-v1:0",
"apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
"apac.anthropic.claude-3-haiku-20240307-v1:0",
"apac.anthropic.claude-3-sonnet-20240229-v1:0",
"apac.anthropic.claude-3-5-sonnet-20240620-v1:0",
"apac.anthropic.claude-3-5-sonnet-20241022-v2:0",
"deepseek.v3-v1:0",
"us.deepseek.r1-v1:0",
"qwen.qwen3-235b-a22b-2507-v1:0",
"qwen.qwen3-32b-v1:0",
"qwen.qwen3-coder-480b-a35b-v1:0",
"qwen.qwen3-coder-30b-a3b-v1:0",
"us.writer.palmyra-x5-v1:0",
"us.writer.palmyra-x4-v1:0",
"amazon.titan-text-premier-v1:0",
"us.meta.llama4-maverick-17b-instruct-v1:0",
"us.meta.llama4-scout-17b-instruct-v1:0",
"us.meta.llama3-3-70b-instruct-v1:0",
"us.meta.llama3-2-90b-instruct-v1:0",
"us.meta.llama3-2-11b-instruct-v1:0",
"us.meta.llama3-2-3b-instruct-v1:0",
"us.meta.llama3-2-1b-instruct-v1:0",
"meta.llama3-1-405b-instruct-v1:0",
"meta.llama3-1-70b-instruct-v1:0",
"meta.llama3-1-8b-instruct-v1:0",
"meta.llama3-70b-instruct-v1:0",
"meta.llama3-8b-instruct-v1:0",
"cohere.command-r-plus-v1:0",
"cohere.command-r-v1:0",
"mistral.mistral-large-2407-v1:0",
"mistral.mistral-large-2402-v1:0",
"mistral.mistral-small-2402-v1:0",
"us.mistral.pixtral-large-2502-v1:0",
"eu.mistral.pixtral-large-2502-v1:0",
"anthropic.claude-v2:1",
"anthropic.claude-v2",
"anthropic.claude-instant-v1",
"mistral.mixtral-8x7b-instruct-v0:1",
"mistral.mistral-7b-instruct-v0:2",
"amazon.nova-pro-v1:0",
"amazon.nova-lite-v1:0",
"amazon.nova-micro-v1:0",
"us.amazon.nova-premier-v1:0",
"us.amazon.nova-pro-v1:0",
"us.amazon.nova-lite-v1:0",
"us.amazon.nova-micro-v1:0",
"eu.amazon.nova-pro-v1:0",
"eu.amazon.nova-lite-v1:0",
"eu.amazon.nova-micro-v1:0",
"apac.amazon.nova-pro-v1:0",
"apac.amazon.nova-lite-v1:0",
"apac.amazon.nova-micro-v1:0",
"openai.gpt-oss-120b-1:0",
"openai.gpt-oss-20b-1:0"
이 솔루션은 다음 음성-음성 모델을 지원합니다:
amazon.nova-sonic-v1:0
이 솔루션은 다음 이미지 생성 모델을 지원합니다:
"amazon.nova-canvas-v1:0",
"amazon.titan-image-generator-v2:0",
"amazon.titan-image-generator-v1",
"stability.sd3-large-v1:0",
"stability.sd3-5-large-v1:0",
"stability.stable-image-core-v1:0",
"stability.stable-image-core-v1:1",
"stability.stable-image-ultra-v1:0",
"stability.stable-image-ultra-v1:1",
"stability.stable-diffusion-xl-v1",
이 솔루션은 다음 비디오 생성 모델을 지원합니다:
"amazon.nova-reel-v1:0",
"amazon.nova-reel-v1:1",
"luma.ray-v2:0"
지정한 모델이 지정된 지역에서 활성화되어 있는지 확인하세요.
여러 지역의 모델 동시 사용¶
기본적으로 GenU는 modelRegion의 모델을 사용합니다. 특정 지역에서만 사용 가능한 최신 모델을 사용하려면 modelIds, imageGenerationModelIds, videoGenerationModelIds, speechToSpeechModelIds에서 {modelId: '<model name>', region: '<region code>'}를 지정하여 지정된 지역에서 해당 특정 모델을 호출할 수 있습니다.
> 모니터링 대시보드와 여러 지역의 모델을 모두 사용하는 경우, 기본 대시보드 설정은 기본 지역(modelRegion) 외부의 모델에 대한 프롬프트 로그를 표시하지 않습니다.
단일 대시보드에서 모든 지역의 프롬프트 로그를 보려면 다음과 같은 추가 구성이 필요합니다:
- 각 지역의 Amazon Bedrock 설정에서 "모델 호출 로깅"을 수동으로 활성화
- CloudWatch 대시보드에 위젯을 추가하여 각 지역의 로그를 집계
예제: 도쿄 지역을 기본으로 사용하면서 버지니아 북부 및 오레곤 지역의 최신 모델도 사용¶
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelRegion: 'ap-northeast-1',
modelIds: [
{
modelId: 'us.anthropic.claude-3-7-sonnet-20250219-v1:0',
region: 'us-east-1',
},
'apac.anthropic.claude-3-5-sonnet-20241022-v2:0',
'anthropic.claude-3-5-sonnet-20240620-v1:0',
{
modelId: 'us.anthropic.claude-3-5-haiku-20241022-v1:0',
region: 'us-east-1',
},
'apac.amazon.nova-pro-v1:0',
'apac.amazon.nova-lite-v1:0',
'apac.amazon.nova-micro-v1:0',
{ modelId: 'us.deepseek.r1-v1:0', region: 'us-east-1' },
{ modelId: 'us.writer.palmyra-x5-v1:0', region: 'us-west-2' },
{
modelId: 'us.meta.llama4-maverick-17b-instruct-v1:0',
region: 'us-east-1',
},
{
modelId: 'us.meta.llama4-scout-17b-instruct-v1:0',
region: 'us-east-1',
},
{ modelId: 'us.mistral.pixtral-large-2502-v1:0', region: 'us-east-1' },
],
imageGenerationModelIds: [
'amazon.nova-canvas-v1:0',
{ modelId: 'stability.sd3-5-large-v1:0', region: 'us-west-2' },
{ modelId: 'stability.stable-image-core-v1:1', region: 'us-west-2' },
{ modelId: 'stability.stable-image-ultra-v1:1', region: 'us-west-2' },
],
videoGenerationModelIds: [
'amazon.nova-reel-v1:0',
{ modelId: 'luma.ray-v2:0', region: 'us-west-2' },
],
speechToSpeechModelIds: [
{ modelId: 'amazon.nova-sonic-v1:0', region: 'us-east-1' },
],
},
};
{
"context": {
"modelRegion": "ap-northeast-1",
"modelIds": [
{
"modelId": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"region": "us-east-1"
},
"apac.anthropic.claude-3-5-sonnet-20241022-v2:0",
"anthropic.claude-3-5-sonnet-20240620-v1:0",
{
"modelId": "us.anthropic.claude-3-5-haiku-20241022-v1:0",
"region": "us-east-1"
},
"apac.amazon.nova-pro-v1:0",
"apac.amazon.nova-lite-v1:0",
"apac.amazon.nova-micro-v1:0",
{
"modelId": "us.deepseek.r1-v1:0",
"region": "us-east-1"
},
{
"modelId": "us.writer.palmyra-x5-v1:0",
"region": "us-west-2"
},
{
"modelId": "us.meta.llama4-maverick-17b-instruct-v1:0",
"region": "us-east-1"
},
{
"modelId": "us.meta.llama4-scout-17b-instruct-v1:0",
"region": "us-east-1"
},
{
"modelId": "us.mistral.pixtral-large-2502-v1:0",
"region": "us-east-1"
}
],
"imageGenerationModelIds": [
"amazon.nova-canvas-v1:0",
{
"modelId": "stability.sd3-5-large-v1:0",
"region": "us-west-2"
},
{
"modelId": "stability.stable-image-core-v1:1",
"region": "us-west-2"
},
{
"modelId": "stability.stable-image-ultra-v1:1",
"region": "us-west-2"
}
],
"videoGenerationModelIds": [
"amazon.nova-reel-v1:0",
{
"modelId": "luma.ray-v2:0",
"region": "us-west-2"
}
],
"speechToSpeechModelIds": [
{
"modelId": "amazon.nova-sonic-v1:0",
"region": "us-east-1"
}
]
}
}
예제: us-east-1 (버지니아)에서 Amazon Bedrock 모델 사용¶
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelRegion: 'us-east-1',
modelIds: [
'anthropic.claude-3-5-sonnet-20240620-v1:0',
'anthropic.claude-3-sonnet-20240229-v1:0',
'anthropic.claude-3-haiku-20240307-v1:0',
'amazon.nova-pro-v1:0',
'amazon.nova-lite-v1:0',
'amazon.nova-micro-v1:0',
'amazon.titan-text-premier-v1:0',
'meta.llama3-70b-instruct-v1:0',
'meta.llama3-8b-instruct-v1:0',
'cohere.command-r-plus-v1:0',
'cohere.command-r-v1:0',
'us.mistral.pixtral-large-2502-v1:0',
'mistral.mistral-large-2402-v1:0',
],
imageGenerationModelIds: [
'amazon.nova-canvas-v1:0',
'amazon.titan-image-generator-v2:0',
'amazon.titan-image-generator-v1',
'stability.stable-diffusion-xl-v1',
],
videoGenerationModelIds: ['amazon.nova-reel-v1:1'],
speechToSpeechModelIds: ['amazon.nova-sonic-v1:0'],
},
};
// cdk.json
{
"context": {
"modelRegion": "us-east-1",
"modelIds": [
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0",
"amazon.nova-pro-v1:0",
"amazon.nova-lite-v1:0",
"amazon.nova-micro-v1:0",
"amazon.titan-text-premier-v1:0",
"meta.llama3-70b-instruct-v1:0",
"meta.llama3-8b-instruct-v1:0",
"cohere.command-r-plus-v1:0",
"cohere.command-r-v1:0",
"mistral.mistral-large-2402-v1:0"
],
"imageGenerationModelIds": [
"amazon.nova-canvas-v1:0",
"amazon.titan-image-generator-v2:0",
"amazon.titan-image-generator-v1",
"stability.stable-diffusion-xl-v1"
],
"videoGenerationModelIds": ["amazon.nova-reel-v1:1"],
"speechToSpeechModelIds": ["amazon.nova-sonic-v1:0"]
}
}
예제: us-west-2 (오레곤)에서 Amazon Bedrock 모델 사용¶
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelRegion: 'us-west-2',
modelIds: [
'anthropic.claude-3-5-sonnet-20241022-v2:0',
'anthropic.claude-3-5-haiku-20241022-v1:0',
'anthropic.claude-3-5-sonnet-20240620-v1:0',
'anthropic.claude-3-opus-20240229-v1:0',
'anthropic.claude-3-sonnet-20240229-v1:0',
'anthropic.claude-3-haiku-20240307-v1:0',
'meta.llama3-1-70b-instruct-v1:0',
'meta.llama3-1-8b-instruct-v1:0',
'cohere.command-r-plus-v1:0',
'cohere.command-r-v1:0',
'mistral.mistral-large-2407-v1:0',
],
imageGenerationModelIds: [
'amazon.titan-image-generator-v2:0',
'amazon.titan-image-generator-v1',
'stability.sd3-large-v1:0',
'stability.sd3-5-large-v1:0',
'stability.stable-image-core-v1:0',
'stability.stable-image-core-v1:1',
'stability.stable-image-ultra-v1:0',
'stability.stable-image-ultra-v1:1',
'stability.stable-diffusion-xl-v1',
],
},
};
// cdk.json
{
"context": {
"modelRegion": "us-west-2",
"modelIds": [
"anthropic.claude-3-5-sonnet-20241022-v2:0",
"anthropic.claude-3-5-haiku-20241022-v1:0",
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-opus-20240229-v1:0",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0",
"meta.llama3-1-70b-instruct-v1:0",
"meta.llama3-1-8b-instruct-v1:0",
"cohere.command-r-plus-v1:0",
"cohere.command-r-v1:0",
"mistral.mistral-large-2407-v1:0"
],
"imageGenerationModelIds": [
"amazon.titan-image-generator-v2:0",
"amazon.titan-image-generator-v1",
"stability.sd3-large-v1:0",
"stability.sd3-5-large-v1:0",
"stability.stable-image-core-v1:0",
"stability.stable-image-core-v1:1",
"stability.stable-image-ultra-v1:0",
"stability.stable-image-ultra-v1:1",
"stability.stable-diffusion-xl-v1"
]
}
}
예제: us (버지니아 북부 또는 오레곤)에서 Amazon Bedrock의 교차 지역 추론 모델 사용¶
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelRegion: 'us-west-2',
modelIds: [
'us.anthropic.claude-3-7-sonnet-20250219-v1:0',
'us.anthropic.claude-3-5-haiku-20241022-v1:0',
'us.anthropic.claude-3-haiku-20240307-v1:0',
'us.deepseek.r1-v1:0',
'us.writer.palmyra-x5-v1:0',
'us.writer.palmyra-x4-v1:0',
'us.meta.llama4-maverick-17b-instruct-v1:0',
'us.meta.llama4-scout-17b-instruct-v1:0',
'us.meta.llama3-2-11b-instruct-v1:0',
'us.meta.llama3-2-3b-instruct-v1:0',
'us.meta.llama3-2-1b-instruct-v1:0',
'us.amazon.nova-premier-v1:0',
'us.amazon.nova-pro-v1:0',
'us.amazon.nova-lite-v1:0',
'us.amazon.nova-micro-v1:0',
'cohere.command-r-plus-v1:0',
'cohere.command-r-v1:0',
'mistral.mistral-large-2407-v1:0',
],
imageGenerationModelIds: [
'amazon.titan-image-generator-v2:0',
'amazon.titan-image-generator-v1',
'stability.sd3-large-v1:0',
'stability.sd3-5-large-v1:0',
'stability.stable-image-core-v1:0',
'stability.stable-image-core-v1:1',
'stability.stable-image-ultra-v1:0',
'stability.stable-image-ultra-v1:1',
'stability.stable-diffusion-xl-v1',
],
},
};
// cdk.json
{
"context": {
"modelRegion": "us-west-2",
"modelIds": [
"us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"us.anthropic.claude-3-5-haiku-20241022-v1:0",
"us.anthropic.claude-3-haiku-20240307-v1:0",
"us.deepseek.r1-v1:0",
"us.writer.palmyra-x5-v1:0",
"us.writer.palmyra-x4-v1:0",
"us.meta.llama4-maverick-17b-instruct-v1:0",
"us.meta.llama4-scout-17b-instruct-v1:0",
"us.meta.llama3-2-11b-instruct-v1:0",
"us.meta.llama3-2-3b-instruct-v1:0",
"us.meta.llama3-2-1b-instruct-v1:0",
"us.amazon.nova-premier-v1:0",
"us.amazon.nova-pro-v1:0",
"us.amazon.nova-lite-v1:0",
"us.amazon.nova-micro-v1:0",
"cohere.command-r-plus-v1:0",
"cohere.command-r-v1:0",
"mistral.mistral-large-2407-v1:0"
],
"imageGenerationModelIds": [
"amazon.titan-image-generator-v2:0",
"amazon.titan-image-generator-v1",
"stability.sd3-large-v1:0",
"stability.sd3-5-large-v1:0",
"stability.stable-image-core-v1:0",
"stability.stable-image-core-v1:1",
"stability.stable-image-ultra-v1:0",
"stability.stable-image-ultra-v1:1",
"stability.stable-diffusion-xl-v1"
]
}
}
예제: ap-northeast-1 (도쿄)에서 Amazon Bedrock 모델 사용¶
parameter.ts 편집
// parameter.ts
const envs: Record<string, StackInput> = {
dev: {
modelRegion: 'ap-northeast-1',
modelIds: [
'anthropic.claude-3-5-sonnet-20240620-v1:0',
'anthropic.claude-3-haiku-20240307-v1:0',
],
imageGenerationModelIds: ['amazon.nova-canvas-v1:0'],
videoGenerationModelIds: ['amazon.nova-reel-v1:0'],
},
};
// cdk.json
{
"context": {
"modelRegion": "ap-northeast-1",
"modelIds": [
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0"
],
"imageGenerationModelIds": ["amazon.nova-canvas-v1:0"],
"videoGenerationModelIds": ["amazon.nova-reel-v1:0"]
}
}
Amazon SageMaker를 사용한 사용자 정의 모델 사용¶
Amazon SageMaker 엔드포인트에 배포된 대화형 언어 모델을 사용할 수 있습니다. Text Generation Inference (TGI) Hugging Face LLM 추론 컨테이너를 사용하는 SageMaker 엔드포인트를 지원합니다. TGI의 Message API를 사용하므로 TGI는 버전 1.4.0 이상이어야 하며, 모델은 Chat Template(tokenizer.config에 정의된 chat_template)을 지원해야 합니다. 현재 텍스트 모델만 지원됩니다.
TGI 컨테이너를 사용하여 SageMaker 엔드포인트에 모델을 배포하는 방법은 현재 두 가지입니다.
SageMaker JumpStart로 AWS에서 사전 준비된 모델 배포
SageMaker JumpStart는 원클릭 배포를 위해 패키지된 OSS 대화형 언어 모델을 제공합니다. SageMaker Studio의 JumpStart 화면에서 모델을 열고 "Deploy" 버튼을 클릭하여 배포할 수 있습니다.
SageMaker SDK를 사용하여 몇 줄의 코드로 배포
AWS와 Hugging Face의 파트너십 덕분에 SageMaker SDK를 사용하여 Hugging Face의 모델 ID를 지정하기만 하면 모델을 배포할 수 있습니다.
모델의 Hugging Face 페이지에서 Deploy > Amazon SageMaker를 선택하면 모델 배포를 위한 코드를 볼 수 있습니다. 이 코드를 복사하여 실행하면 모델이 배포됩니다. (모델에 따라 인스턴스 크기나 SM_NUM_GPUS와 같은 매개변수를 조정해야 할 수 있습니다. 배포가 실패하면 CloudWatch Logs에서 로그를 확인할 수 있습니다.)
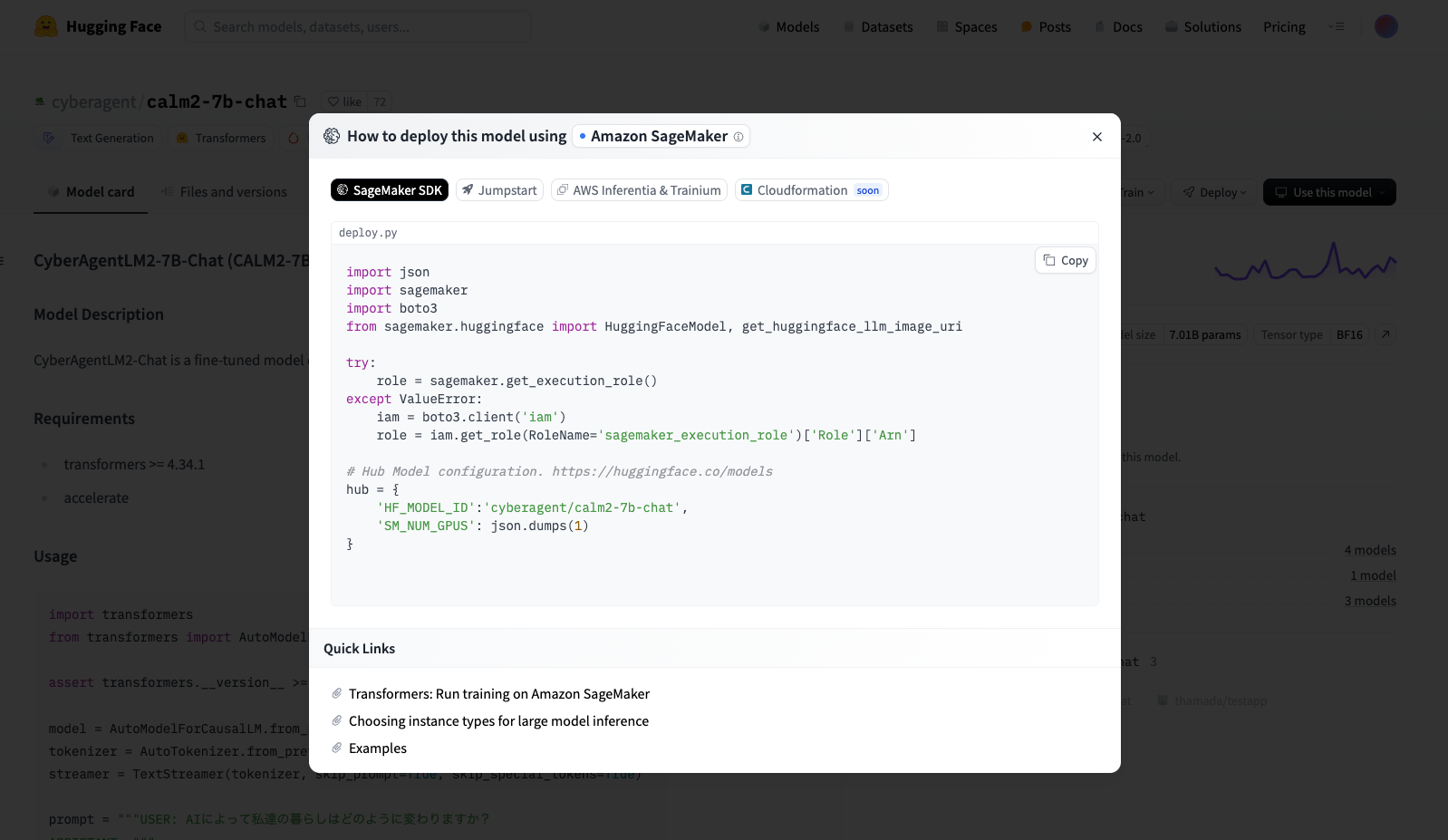
배포된 모델을 호출하도록 GenU 구성¶
대상 솔루션에서 배포된 SageMaker 엔드포인트를 사용하려면 다음과 같이 지정합니다:
endpointNames는 SageMaker 엔드포인트 이름의 목록입니다. 선택적으로 각 엔드포인트에 대해 지역을 지정할 수 있습니다.
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
modelRegion: 'us-east-1',
endpointNames: [
'<SageMaker Endpoint Name>',
{
modelIds: '<SageMaker Endpoint Name>',
region: '<SageMaker Endpoint Region>',
},
],
},
};
// cdk.json
{
"context": {
"modelRegion": "<SageMaker Endpoint Region>",
"endpointNames": [
"<SageMaker Endpoint Name>",
{
"modelIds": "<SageMaker Endpoint Name>",
"region": "<SageMaker Endpoint Region>"
}
]
}
}
보안 관련 설정¶
자체 가입 비활성화¶
selfSignUpEnabled를 false로 설정합니다. (기본값은 true)
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
selfSignUpEnabled: false,
},
};
// cdk.json
{
"context": {
"selfSignUpEnabled": false
}
}
가입용 이메일 도메인 제한¶
allowedSignUpEmailDomains에 허용된 도메인 목록을 지정합니다 (기본값은 null).
값을 문자열 목록으로 지정하고 각 문자열에 "@"를 포함하지 마세요. 사용자의 이메일 도메인이 허용된 도메인 중 하나와 일치하면 가입할 수 있습니다. null을 지정하면 제한이 없어 모든 도메인이 허용됩니다. []를 지정하면 모든 도메인이 금지되어 어떤 이메일 주소도 등록할 수 없습니다.
구성되면 허용되지 않은 도메인의 사용자가 웹 가입 화면에서 "계정 생성"을 시도할 때 오류가 발생하여 GenU에 가입할 수 없습니다. 또한 AWS Management Console의 Cognito 서비스 화면에서 "사용자 생성"을 시도해도 오류가 발생합니다.
이는 Cognito에 이미 생성된 사용자에게는 영향을 주지 않습니다. 가입하거나 생성하려는 새 사용자에게만 적용됩니다.
구성 예제
amazon.com도메인의 이메일 주소로만 가입을 허용하는 예제
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
allowedSignUpEmailDomains: ['amazon.com'],
},
};
// cdk.json
{
"context": {
"allowedSignUpEmailDomains": ["amazon.com"] // null에서 허용된 도메인을 지정하여 활성화
}
}
amazon.com또는amazon.jp도메인의 이메일 주소로 가입을 허용하는 예제
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
allowedSignUpEmailDomains: ['amazon.com', 'amazon.jp'],
},
};
// cdk.json
{
"context": {
"allowedSignUpEmailDomains": ["amazon.com", "amazon.jp"] // null에서 허용된 도메인을 지정하여 활성화
}
}
AWS WAF 제한 활성화¶
IP 주소 제한¶
IP 주소로 웹 앱 액세스를 제한하려면 AWS WAF IP 주소 제한을 활성화할 수 있습니다. allowedIpV4AddressRanges에 허용된 IPv4 CIDR을 배열로 지정하고 allowedIpV6AddressRanges에 허용된 IPv6 CIDR을 배열로 지정할 수 있습니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
allowedIpV4AddressRanges: ['192.168.0.0/24'],
allowedIpV6AddressRanges: ['2001:0db8::/32'],
},
};
// cdk.json
{
"context": {
"allowedIpV4AddressRanges": ["192.168.0.0/24"], // null에서 허용된 CIDR 목록을 지정하여 활성화
"allowedIpV6AddressRanges": ["2001:0db8::/32"] // null에서 허용된 CIDR 목록을 지정하여 활성화
}
}
지리적 제한¶
원산지 국가별로 웹 앱 액세스를 제한하려면 AWS WAF 지리적 제한을 활성화할 수 있습니다. allowedCountryCodes에 허용된 국가를 국가 코드 배열로 지정할 수 있습니다.
국가 코드는 Wikipedia의 ISO 3166-2를 참조하세요.
"IP 주소 제한"도 구성된 경우 "허용된 IP 주소에 포함된 소스 IP 주소 AND 허용된 국가에서의 액세스"만 허용됩니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
allowedCountryCodes: ['JP'],
},
};
// cdk.json
{
"context": {
"allowedCountryCodes": ["JP"] // null에서 허용된 국가 목록을 지정하여 활성화
}
}
allowedIpV4AddressRanges, allowedIpV6AddressRanges, allowedCountryCodes 중 하나를 지정하고 npm run cdk:deploy를 다시 실행하면 WAF 스택이 us-east-1에 배포됩니다 (AWS WAF V2는 현재 CloudFront와 함께 사용할 때 us-east-1만 지원). us-east-1에서 CDK를 사용한 적이 없다면 배포 전에 다음 명령을 실행하여 부트스트랩하세요:
npx -w packages/cdk cdk bootstrap --region us-east-1
SAML 인증¶
Google Workspace 또는 Microsoft Entra ID (이전 Azure Active Directory)와 같은 IdP에서 제공하는 SAML 인증 기능과 통합할 수 있습니다. 자세한 통합 절차는 다음과 같습니다:
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
samlAuthEnabled: true,
samlCognitoDomainName:
'your-preferred-name.auth.ap-northeast-1.amazoncognito.com',
samlCognitoFederatedIdentityProviderName: 'EntraID',
},
};
// cdk.json
{
"context": {
"samlAuthEnabled": true,
"samlCognitoDomainName": "your-preferred-name.auth.ap-northeast-1.amazoncognito.com",
"samlCognitoFederatedIdentityProviderName": "EntraID"
}
}
- samlAuthEnabled:
true로 설정하면 SAML 전용 인증 화면으로 전환됩니다. Cognito 사용자 풀을 사용한 기존 인증은 더 이상 사용할 수 없습니다. - samlCognitoDomainName: Cognito의 App integration에 설정할 Cognito 도메인 이름을 지정합니다.
- samlCognitoFederatedIdentityProviderName: Cognito의 Sign-in experience에 설정할 Identity Provider 이름을 지정합니다.
가드레일¶
Converse API를 사용할 때 (즉, 텍스트 출력을 생성하는 생성형 AI 모델) 가드레일을 적용할 수 있습니다. 이를 구성하려면 guardrailEnabled를 true로 변경하고 재배포합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
guardrailEnabled: true,
},
};
// cdk.json
{
"context": {
"guardrailEnabled": true
}
}
기본 가드레일은 일본어 대화에서 효과가 입증된 민감한 정보 필터를 적용합니다. 사용자 정의 단어 필터와 민감한 정보 필터용 정규 표현식도 작동하는 것을 확인했으므로 필요에 따라 packages/cdk/lib/construct/guardrail.ts를 수정하세요. 자세한 내용은 Amazon Bedrock용 가드레일과 CfnGuardrail을 참조하세요.
Note
가드레일을 활성화한 후 비활성화하려면 guardrailEnabled: false로 설정하고 재배포합니다. 이렇게 하면 생성형 AI 호출 시 가드레일이 비활성화되지만 가드레일 자체는 남아있습니다. 관리 콘솔을 열고 modelRegion의 CloudFormation에서 GuardrailStack 스택을 삭제하여 완전히 제거할 수 있습니다. 가드레일이 남아있어도 비용이 발생하지 않지만 사용하지 않는 리소스는 삭제하는 것이 좋습니다.
비용 관련 설정¶
Kendra 인덱스 자동 생성 및 삭제 일정 설정¶
GenerativeAiUseCasesDashboardStack에서 생성된 Kendra 인덱스를 미리 정해진 일정에 따라 자동으로 생성하고 삭제하는 설정을 구성합니다. 이는 Kendra 인덱스 가동 시간에 따라 발생하는 사용료를 줄이는 데 도움이 됩니다. Kendra 인덱스를 생성한 후 이 저장소에서 기본적으로 생성된 S3 데이터 소스와 자동으로 동기화됩니다.
이 기능은 ragEnabled가 true이고 kendraIndexArn이 null인 경우에만 효과적입니다 (즉, 외부에서 생성된 Kendra 인덱스에서는 작동하지 않습니다).
다음 예제와 같이 구성합니다:
kendraIndexScheduleEnabled를true로 설정하면 일정 설정이 활성화되고false로 설정하면 해당 배포부터 일정이 비활성화됩니다.kendraIndexScheduleCreateCron과kendraIndexScheduleDeleteCron을 사용하여 Cron 형식으로 생성 및 삭제 시작 시간을 지정합니다.- Cron 형식에 대한 자세한 내용은 이 문서를 참조하세요. 하지만 EventBridge 사양을 준수하기 위해 시간을 UTC로 지정하세요. 현재 minute, hour, month, weekDay만 지정할 수 있습니다. 이러한 항목은 반드시 지정해야 하며 다른 항목은 지정해도 무시됩니다.
null로 설정하면 생성/삭제가 실행되지 않습니다. 하나만null로 설정하거나 (하나만 구성) 둘 다null로 설정할 수 있습니다 (아무것도 실행하지 않음).
아래 예제는 JST 월-금 오전 8시에 인덱스 생성을 시작하고 JST 월-금 오후 8시에 삭제를 시작하도록 구성합니다.
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
kendraIndexScheduleEnabled: true,
kendraIndexScheduleCreateCron: {
minute: '0',
hour: '23',
month: '*',
weekDay: 'SUN-THU',
},
kendraIndexScheduleDeleteCron: {
minute: '0',
hour: '11',
month: '*',
weekDay: 'MON-FRI',
},
},
};
// cdk.json
{
"context": {
"kendraIndexScheduleEnabled": true,
"kendraIndexScheduleCreateCron": {
"minute": "0",
"hour": "23",
"month": "*",
"weekDay": "SUN-THU"
},
"kendraIndexScheduleDeleteCron": {
"minute": "0",
"hour": "11",
"month": "*",
"weekDay": "MON-FRI"
}
}
}
Kendra 인덱스가 삭제되어도 RAG 기능은 계속 켜져 있습니다. 웹 애플리케이션(GenU)에서 RAG 관련 메뉴가 계속 표시됩니다. RAG 채팅을 실행할 때 인덱스가 존재하지 않아 오류가 발생하며 "인덱스 생성/삭제 일정을 확인하세요"라는 오류 메시지가 표시됩니다.
일정 관리에는 EventBridge 규칙이 사용되고 프로세스 제어에는 Step Functions가 사용됩니다. EventBridge 규칙을 수동으로 비활성화하여 일정을 중지할 수 있습니다. Step Functions 상태 머신을 수동으로 실행하여 인덱스를 생성하거나 삭제할 수도 있습니다.
Note
- 인덱스 재생성 후에는 기본 S3 데이터 소스만 추가됩니다.
- 인덱스 생성 후 다른 데이터 소스를 추가한 경우, 인덱스가 삭제될 때 함께 삭제되며 인덱스가 재생성될 때 재생성되지 않으므로 다시 추가해야 합니다.
- 이 저장소의 CDK 내에서 데이터 소스를 추가한 경우, 데이터 소스는 생성되지만 동기화되지 않습니다. CDK로 추가된 데이터 소스를 동기화하려면 수동으로 동기화하거나 코드를 수정하여 Step Functions 상태 머신의 대상으로 추가하세요.
- Kendra 인덱스 생성 시작부터 사용 가능해질 때까지 시간이 걸립니다. 구체적으로 인덱스 생성과 데이터 소스 동기화에 시간이 걸립니다. 따라서 RAG 채팅을 사용하기 시작할 특정 시간이 있다면 그보다 일찍 시작 시간을 설정하세요. 이는 리소스 가용성, 데이터 소스 유형, 문서 크기/수에 따라 달라지므로 정확한 가동 시간 설정이 필요한 경우 실제 소요 시간을 확인하세요.
- 대략적인 가이드라인으로 인덱스 생성에 약 30분, 수백 개의 텍스트 파일이 있는 S3 데이터 소스 동기화에 약 10분이 걸립니다 (이는 추정치입니다). (이를 기준으로 40분 일찍 설정하게 됩니다.)
- 외부 서비스를 데이터 소스로 사용할 때는 필요한 시간이 크게 달라질 수 있으므로 특히 주의하세요. API 호출 제한도 염두에 두세요.
- 이는 설정된 시간 외에 인덱스가 중지된다는 것을 보장하지 않으며, 단순히 일정에 따라 시작/종료를 실행합니다. 배포 및 일정 타이밍에 주의하세요.
- 예를 들어, 오후 9시에 오후 8시에 삭제하는 설정을 배포하면 그 시점에서는 삭제되지 않고 다음 날 오후 8시에 삭제가 시작됩니다.
- 스택을 생성할 때 (GenerativeAiUseCasesStack이 존재하지 않을 때 cdk:deploy 실행),
ragEnabled가true이면 Kendra 인덱스가 생성됩니다. 일정 시간이 설정되어 있어도 인덱스가 생성됩니다. 인덱스는 다음 삭제 일정 시간까지 생성된 상태로 유지됩니다. - 현재 시작/종료 오류를 알리는 기능은 없습니다.
- 인덱스가 재생성될 때마다 IndexId와 DataSourceId가 변경됩니다. 다른 서비스에서 이를 참조하는 경우 이러한 변경사항에 적응해야 합니다.
태그 설정 방법¶
GenU는 비용 관리 및 기타 목적을 위한 태그를 지원합니다. 기본적으로 태그의 키 이름은 GenU로 설정되지만, tagKey를 지정하여 사용자 정의 태그 키를 사용할 수 있습니다. 설정 방법의 예시는 다음과 같습니다:
cdk.json에서 설정:
// cdk.json
...
"context": {
"tagKey": "MyProject", // 사용자 정의 태그 키 (선택사항, 기본값은 "GenU")
"tagValue": "dev",
...
parameter.ts에서 설정:
...
tagKey: "MyProject", // 사용자 정의 태그 키 (선택사항, 기본값은 "GenU")
tagValue: "dev",
...
그러나 일부 리소스에서는 태그를 사용할 수 없습니다:
- 교차 지역 추론 모델 호출
- 음성 채팅 모델 호출
When managing costs using tags, you need to enable “Cost allocation tags” by following these steps.
- Open the “Billing and Cost Management” console.
- Open “Cost Allocation Tags” in the left menu.
- Activate the tag with the tag key “GenU” from “User-defined cost allocation tags.”
모니터링 대시보드 활성화¶
입력/출력 토큰 수와 최근 프롬프트를 집계하는 대시보드를 생성합니다. 이 대시보드는 GenU에 내장되지 않고 Amazon CloudWatch 대시보드입니다. Amazon CloudWatch 대시보드는 관리 콘솔에서 볼 수 있습니다. 대시보드를 보려면 관리 콘솔에 로그인하고 대시보드를 볼 수 있는 권한이 있는 IAM 사용자를 생성해야 합니다.
dashboard를 true로 설정합니다. (기본값은 false)
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
dashboard: true,
},
};
// cdk.json
{
"context": {
"dashboard": true
}
}
변경 후 npm run cdk:deploy로 재배포하여 변경사항을 적용합니다. modelRegion에 지정된 지역에 GenerativeAiUseCasesDashboardStack이라는 스택이 배포됩니다. 출력 값은 다음 단계에서 사용됩니다.
다음으로 Amazon Bedrock 로그 출력을 구성합니다. Amazon Bedrock 설정을 열고 Model invocation logging을 활성화합니다. Select the logging destinations에서 CloudWatch Logs only를 선택합니다. (S3에도 출력하려면 Both S3 and CloudWatch Logs를 선택할 수도 있습니다.) Log group name에는 npm run cdk:deploy 중에 출력된 GenerativeAiUseCasesDashboardStack.BedrockLogGroup을 지정합니다. (예: GenerativeAiUseCasesDashboardStack-LogGroupAAAAAAAA-BBBBBBBBBBBB) 임의의 이름으로 새 Service role을 생성합니다. Model invocation logging 설정은 modelRegion으로 지정된 지역에서 구성해야 합니다.
구성 후 npm run cdk:deploy 중에 출력된 GenerativeAiUseCasesDashboardStack.DashboardUrl을 엽니다.
Note
모니터링 대시보드를 활성화한 후 비활성화하려면 dashboard: false로 설정하고 재배포합니다. 이렇게 하면 모니터링 대시보드가 비활성화되지만 GenerativeAiUseCasesDashboardStack 자체는 남아있습니다. 완전히 제거하려면 관리 콘솔을 열고 modelRegion의 CloudFormation에서 GenerativeAiUseCasesDashboardStack 스택을 삭제하세요.
사용자 정의 도메인 사용¶
웹사이트 URL에 사용자 정의 도메인을 사용할 수 있습니다. 동일한 AWS 계정의 Route53에 공개 호스팅 영역이 이미 생성되어 있어야 합니다. 공개 호스팅 영역에 대해서는 다음을 참조하세요: 공개 호스팅 영역 작업 - Amazon Route 53
동일한 AWS 계정에 공개 호스팅 영역이 없는 경우 AWS ACM SSL 인증서 검증을 위한 DNS 레코드를 수동으로 추가하거나 이메일 검증을 사용할 수도 있습니다. 이러한 방법을 사용하려면 사용자 정의를 위한 CDK 문서를 참조하세요: aws-cdk-lib.aws_certificatemanager 모듈 · AWS CDK
다음 값을 설정합니다:
hostName... 웹사이트의 호스트명. A 레코드는 CDK에서 생성되므로 미리 생성할 필요가 없습니다domainName... 사전 생성된 공개 호스팅 영역의 도메인 이름hostedZoneId... 사전 생성된 공개 호스팅 영역의 ID
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
hostName: 'genai',
domainName: 'example.com',
hostedZoneId: 'XXXXXXXXXXXXXXXXXXXX',
},
};
// cdk.json
{
"context": {
"hostName": "genai",
"domainName": "example.com",
"hostedZoneId": "XXXXXXXXXXXXXXXXXXXX"
}
}
다른 AWS 계정에서 Bedrock 사용¶
Note
Flow Chat 사용 사례와 프롬프트 최적화 도구는 다른 AWS 계정 사용을 지원하지 않으며 실행 중 오류가 발생할 수 있습니다.
다른 AWS 계정에서 Bedrock을 사용할 수 있습니다. 전제 조건으로 GenU의 초기 배포가 완료되어야 합니다.
다른 AWS 계정에서 Bedrock을 사용하려면 해당 계정에 하나의 IAM 역할을 생성해야 합니다. IAM 역할의 이름은 임의로 지정할 수 있지만, 다른 계정에서 생성된 IAM 역할의 Principal에 다음 IAM 역할 이름들(GenU 배포 중에 생성됨)을 지정해야 합니다:
GenerativeAiUseCasesStack-APIPredictTitleServiceGenerativeAiUseCasesStack-APIPredictServiceGenerativeAiUseCasesStack-APIPredictStreamServiceGenerativeAiUseCasesStack-APIGenerateImageServiceGenerativeAiUseCasesStack-APIGenerateVideoServiceGenerativeAiUseCasesStack-APIListVideoJobsServiceGenerativeAiUseCasesStack-SpeechToSpeechTaskServiceGenerativeAiUseCasesStack-RagKnowledgeBaseRetrieve(Knowledge Base 사용 시에만)GenerativeAiUseCasesStack-APIGetFileDownloadSigned(Knowledge Base 사용 시에만)
Principal 지정 방법에 대한 자세한 내용은 다음을 참조하세요: AWS JSON 정책 요소: Principal
Principal 구성 예제 (다른 계정에서 설정)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIPredictTitleServiceXXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIPredictServiceXXXXXXXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIPredictStreamServiceXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIGenerateImageServiceXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIGenerateVideoServiceXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIListVideoJobsServiceXX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-SpeechToSpeechTaskService-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-RagKnowledgeBaseRetrieveX-XXXXXXXXXXXX",
"arn:aws:iam::111111111111:role/GenerativeAiUseCasesStack-APIGetFileDownloadSignedU-XXXXXXXXXXXX"
]
},
"Action": "sts:AssumeRole"
}
]
}
정책 구성 예제 (다른 계정에서 설정)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowBedrockInvokeModel",
"Effect": "Allow",
"Action": [
"bedrock:Invoke*",
"bedrock:Rerank",
"bedrock:GetInferenceProfile",
"bedrock:GetAsyncInvoke",
"bedrock:ListAsyncInvokes",
"bedrock:GetAgent*",
"bedrock:ListAgent*"
],
"Resource": ["*"]
},
{
"Sid": "AllowS3PutObjectToVideoTempBucket",
"Effect": "Allow",
"Action": ["s3:PutObject"],
"Resource": ["arn:aws:s3:::<video-temp-bucket-name>/*"]
},
{
"Sid": "AllowBedrockRetrieveFromKnowledgeBase",
"Effect": "Allow",
"Action": ["bedrock:RetrieveAndGenerate*", "bedrock:Retrieve*"],
"Resource": [
"arn:aws:bedrock:<region>:<account-id>:knowledge-base/<knowledge-base-id>"
]
},
{
"Sid": "AllowS3GetPresignedUrl",
"Effect": "Allow",
"Action": ["s3:GetObject*"],
"Resource": ["arn:aws:s3:::<knowledge-base-datasource-bucket-name>/*"]
}
]
}
다음 매개변수를 설정합니다:
crossAccountBedrockRoleArn... 다른 계정에서 미리 생성된 IAM 역할의 ARN
Knowledge Base를 사용할 때는 다음 추가 매개변수가 필요합니다:
ragKnowledgeBaseEnabled... Knowledge Base를 활성화하려면true로 설정ragKnowledgeBaseId... 다른 계정에서 미리 생성된 Knowledge Base ID- Knowledge Base는
modelRegion에 존재해야 합니다
Agent Chat 사용 사례를 사용할 때는 다음 추가 매개변수가 필요합니다:
agents... Bedrock Agent 구성 목록으로 다음 속성을 가집니다:displayName... 에이전트의 표시 이름agentId... 다른 계정에서 미리 생성된 Agent IDaliasId... 다른 계정에서 미리 생성된 Agent Alias ID
parameter.ts 편집
// parameter.ts
const envs: Record<string, Partial<StackInput>> = {
dev: {
crossAccountBedrockRoleArn:
'arn:aws:iam::AccountID:role/PreCreatedRoleName',
// Knowledge Base 사용 시에만
ragKnowledgeBaseEnabled: true,
ragKnowledgeBaseId: 'YOUR_KNOWLEDGE_BASE_ID',
// 에이전트 사용 시에만
agents: [
{
displayName: 'YOUR AGENT NAME',
agentId: 'YOUR_AGENT_ID',
aliasId: 'YOUR_AGENT_ALIAS_ID',
},
],
},
};
// cdk.json
{
"context": {
"crossAccountBedrockRoleArn": "arn:aws:iam::AccountID:role/PreCreatedRoleName",
// Knowledge Base 사용 시에만
"ragKnowledgeBaseEnabled": true,
"ragKnowledgeBaseId": "YOUR_KNOWLEDGE_BASE_ID",
// 에이전트 사용 시에만
"agents": [
{
"displayName": "YOUR AGENT NAME",
"agentId": "YOUR_AGENT_ID",
"aliasId": "YOUR_AGENT_ALIAS_ID"
}
]
}
}
설정을 변경한 후 npm run cdk:deploy를 실행하여 변경사항을 적용합니다.
동일한 계정에서 여러 환경 배포¶
동일한 계정에서 여러 환경을 배포할 때는 서로 다른 스택 이름으로 배포해야 합니다.
env를 설정하면 각 스택 이름에 접미사로 추가되어 별도의 환경으로 배포됩니다.
env는 parameter.ts의 환경 결정에도 사용되며, env로 지정된 환경이 parameter.ts에 존재하면 parameter.ts의 값으로 모든 매개변수가 덮어쓰여집니다. env로 지정된 환경이 parameter.ts에 존재하지 않으면 cdk.json의 context에 있는 매개변수로 애플리케이션이 배포됩니다.
다음 값을 설정합니다:
env... 환경 이름 (기본값: "" (빈 문자열))
// cdk.json
{
"context": {
"env": "<환경 이름>"
}
}
또는 배포할 때 명령에서 context를 지정할 수 있습니다:
npm run cdk:deploy -- -c env=<환경 이름>
구성 예제
// cdk.json
{
"context": {
"env": "dev"
}
}
폐쇄 네트워크 환경에서 GenU 사용¶
폐쇄 네트워크 환경에서 GenU를 사용하려면 폐쇄 네트워크 모드로 GenU를 배포해야 합니다. 폐쇄 네트워크 모드로 GenU를 배포하는 방법에 대한 지침은 여기를 참조하세요.