Sample AWS IDP Pipeline
Overview
Section titled “Overview”An AI-powered IDP prototype that transforms unstructured data into actionable insights. Analyzes documents, videos, audio files, and images with hybrid search (vector + keyword), knowledge graph traversal, and a conversational AI interface. Built as an Nx monorepo with AWS CDK, featuring real-time workflow status notifications.
Features
Section titled “Features”-
Intelligent Document Processing (IDP)
- Document analysis with Bedrock Data Automation (BDA)
- OCR processing with PaddleOCR (Lambda CPU + SageMaker GPU)
- Audio/video transcription via AWS Transcribe
- Automatic file type detection and preprocessing pipeline routing
-
- Per-segment deep analysis with Claude Sonnet 4.6 Vision ReAct Agent
- Video analysis with TwelveLabs Pegasus 1.2 + Amazon Nova Lite 2
- Document summarization with Claude Sonnet 4.6 / Haiku 4.5
- 1024-dimensional vector embeddings with Nova Embed
-
- LanceDB vector search + Full-Text Search (FTS)
- Kiwi Korean morphological analyzer for keyword extraction
- Result reranking with Bedrock Cohere Rerank v3.5
-
Knowledge Graph
- Neptune DB Serverless for entity and relationship storage
- LLM-based entity extraction and relationship mapping (auto-built during analysis)
- Graph traversal to discover related pages across documents
- Project-level and document-level graph visualization
-
AI Chat (Agent Core)
- IDP Agent on Bedrock Agent Core
- Tool invocation via MCP Gateway (search, graph, artifact management)
- S3-based session management for conversation continuity
- Custom agents with project-specific system prompts
-
Real-time Notifications
- Real-time status updates via WebSocket API + ElastiCache Redis
- Workflow event detection through DynamoDB Streams
- Live updates for step progress, artifact changes, and session state
-
Supported File Formats
File Type Supported Formats Documents PDF, DOCX, DOC, TXT, MD Images PNG, JPG, JPEG, GIF, TIFF, WebP Videos MP4, MOV, AVI, MKV, WebM Audio MP3, WAV, FLAC, M4A Presentations PPTX, PPT Spreadsheets XLSX, XLS, CSV CAD DXF Web .webreq (URL crawling)
Architecture
Section titled “Architecture”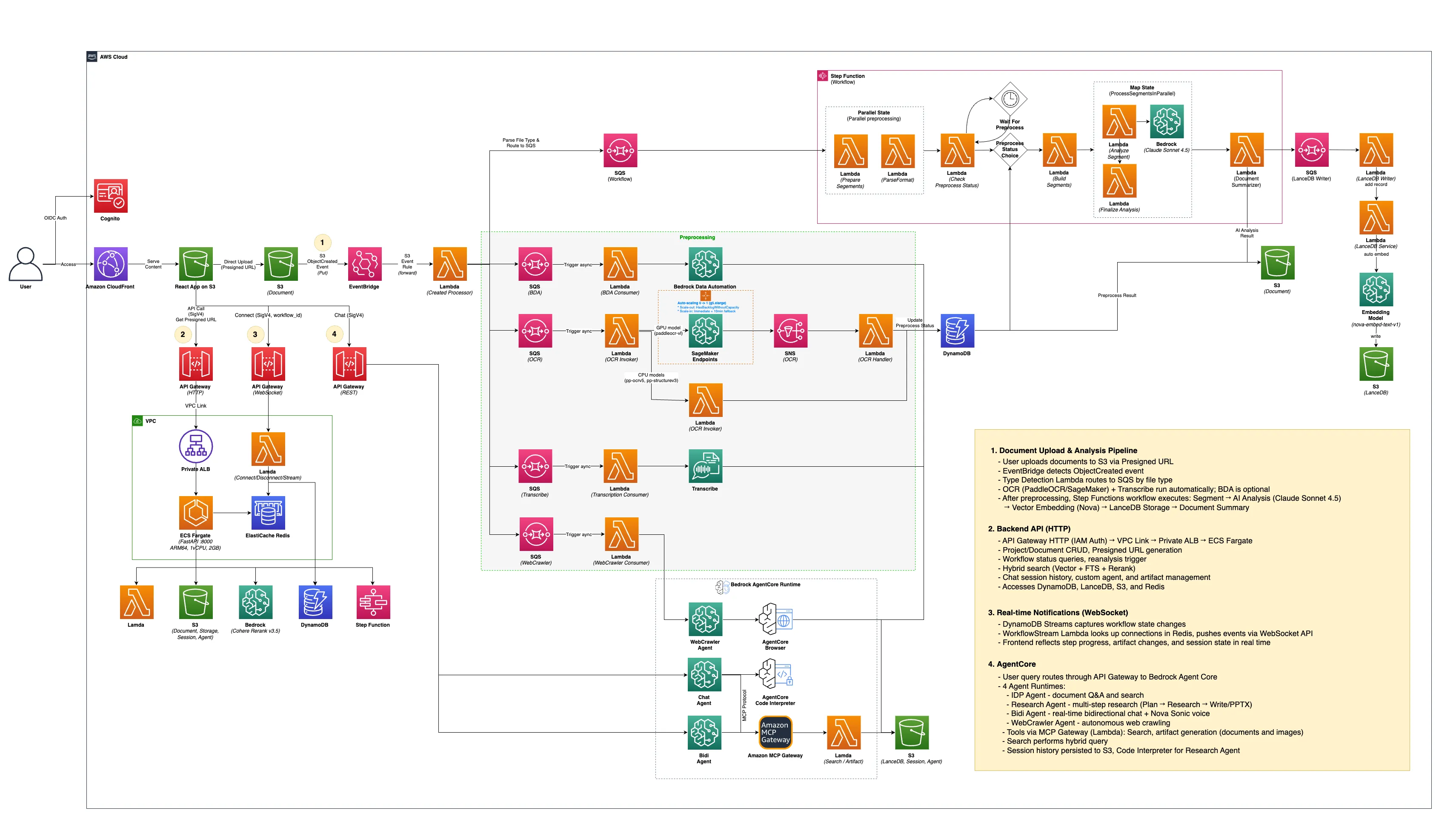
CDK Stack Structure
Section titled “CDK Stack Structure”@idp-v2/infra (14 stacks)+-- VpcStack - VPC (10.0.0.0/16, 2 AZ, NAT Gateway)+-- NeptuneStack - Neptune DB Serverless (knowledge graph)+-- StorageStack - S3 buckets, DynamoDB tables, ElastiCache Redis+-- EventStack - S3 EventBridge, SQS queues, file type detection Lambda+-- OcrStack - PaddleOCR (Lambda CPU + SageMaker GPU)+-- BdaStack - Bedrock Data Automation consumer+-- TranscribeStack - AWS Transcribe consumer+-- WorkflowStack - Step Functions workflow (Distributed Map)+-- WebsocketStack - WebSocket API, real-time notifications+-- McpStack - MCP Gateway (search, graph, artifact tools)+-- WorkerStack - WebSocket message processing+-- AgentStack - Bedrock Agent Core (IDP Agent)+-- WebcrawlerStack - Web crawling agent (Bedrock Agent Core)'-- ApplicationStack - Backend (ECS Fargate), Frontend (CloudFront), CognitoCore Workflows
Section titled “Core Workflows”1. Document Upload & Analysis Pipeline
Section titled “1. Document Upload & Analysis Pipeline”When a user uploads a document to S3 via Presigned URL, EventBridge detects the ObjectCreated event. The Type Detection Lambda identifies the file type and routes it to SQS. Preprocessing runs in parallel (OCR, BDA, Transcribe), and after completion, the Step Functions workflow performs segmentation, AI analysis, vector embedding, knowledge graph building, and document summarization.
S3 Upload (Presigned URL) -> EventBridge (ObjectCreated) -> Type Detection Lambda +- OCR Queue -> PaddleOCR (Lambda/SageMaker) -- optional +- BDA Queue -> Bedrock Data Automation -- optional +- Transcribe Queue -> AWS Transcribe -- optional +- WebCrawler Queue -> Bedrock Agent Core -- automatic (.webreq) '- Workflow Queue -> Step Functions
-> Step Functions Workflow Segment Prep -> Wait for Preprocess -> Format Parser -> Build Segments -> Distributed Map (max 30) +- Segment Analyzer (Claude Sonnet 4.6 Vision / Pegasus 1.2 / Nova Lite 2) '- Analysis Finalizer -> SQS -> LanceDB Writer -> Document Summarizer (Claude Sonnet 4.6) -> Vector Embedding (Nova 1024d) -> LanceDB -> Graph Builder (Entity Extraction) -> Neptune DB (entities, relationships)2. Real-time Notifications (WebSocket)
Section titled “2. Real-time Notifications (WebSocket)”When workflow progress is recorded in DynamoDB, DynamoDB Streams detects the changes. The WorkflowStream Lambda inside the VPC looks up active connections in Redis, then pushes events through the WebSocket API so the frontend reflects status in real time.
DynamoDB Streams (state change detection) -> WorkflowStream Lambda (VPC) -> Redis (connection lookup) -> WebSocket API -> Frontend +- Step progress +- Artifact changes '- Session state updates3. AI Chat (Agent Core)
Section titled “3. AI Chat (Agent Core)”User queries are routed through API Gateway to Bedrock Agent Core. The IDP Agent invokes tools via MCP Gateway, performing hybrid search with the Search Tool, graph traversal with the Graph Tool, and managing outputs with the Artifact Tool. Session history is persisted to S3 to maintain conversation context.
User Query -> API Gateway REST (SigV4) -> Bedrock Agent Core Runtime '- IDP Agent (Claude Sonnet 4.6) -> MCP Gateway +- Search Tool Lambda -> LanceDB Service -> Hybrid Search (Vector + FTS) +- Graph Tool Lambda -> Graph Service -> Neptune (graph traversal) +- Artifact Tool Lambda -> S3 '- Code Interpreter -> Python execution -> S3 (Session Load/Save)4. Backend API (HTTP)
Section titled “4. Backend API (HTTP)”API Gateway HTTP (IAM Auth) connects through VPC Link to a Private ALB, then to ECS Fargate running FastAPI. It handles all data access including project/document management, workflow queries, hybrid search, chat sessions, custom agents, knowledge graph, and artifact management.
API Gateway HTTP (IAM Auth) -> VPC Link -> Private ALB -> ECS Fargate (FastAPI) +- DynamoDB -- Project/document CRUD, workflow status +- LanceDB -- Hybrid search (Vector + FTS) via Lambda invoke +- Neptune -- Knowledge graph queries +- Bedrock -- Cohere Rerank v3.5 +- S3 -- Presigned URL, sessions (DuckDB), agents, artifacts +- Redis -- Query cache +- Step Functions -- Reanalysis trigger '- Lambda -- QA RegeneratorKey Design Decisions
Section titled “Key Design Decisions”| Decision | Rationale |
|---|---|
| Step Functions payload -> DynamoDB intermediate storage | Bypass Step Functions 256KB payload limit |
| Only segment indices passed in workflow | Support for 3000+ page documents |
| LanceDB + S3 Express One Zone | Low-latency storage optimized for vector search |
| Neptune DB Serverless | Knowledge graph for entity relationships, scales to zero when idle |
| PaddleOCR dual backend (Lambda + SageMaker) | CPU models on Lambda (no cold start), GPU model (VL) on SageMaker |
| SageMaker Auto-scaling 0->1 | Cost optimization (Scale-to-zero when idle) |
| ElastiCache Redis | WebSocket connection state management (faster than DynamoDB TTL) |
| DuckDB for direct S3 queries | Query session/agent data without copying |
| VPC Link + Private ALB | Keep backend unexposed to the internet |
| Distributed Map (max 30 concurrency) | Balance between parallelism and Lambda concurrency limits |
Getting Started
Section titled “Getting Started”Prerequisites
Section titled “Prerequisites”- Node.js v18+
- pnpm v8+
- Python 3.12
- AWS CLI (credentials configured)
- AWS CDK v2
- mise (task management)
Installation
Section titled “Installation”# Clone the repositorygit clone https://github.com/aws-samples/sample-aws-idp-pipeline.gitcd sample-aws-idp-pipeline
# Install dependenciespnpm install
# Set up environment variablescp .env.local.example .env.local# Edit .env.local to configure your AWS profile and regionLocal Development
Section titled “Local Development”# Frontend dev serverpnpm nx serve @idp-v2/frontend
# Run agent locallypnpm nx serve idp_v2.idp_agentDeployment
Section titled “Deployment”Quick Deploy: Deploy the entire pipeline with a single script using CloudShell + CodeBuild. See Quick Deploy Guide.
Deploy with mise (Recommended)
Section titled “Deploy with mise (Recommended)”# Install mise (macOS)brew install mise
# Deploy with stack selection (via fzf)mise run deploy
# Build allpnpm build:allDirect CDK Deployment
Section titled “Direct CDK Deployment”# CDK bootstrap (first time only)pnpm nx synth @idp-v2/infra
# Deploy all stackspnpm nx deploy @idp-v2/infra
# Hotswap deploy (dev)pnpm nx deploy @idp-v2/infra --hotswap
# Destroy resourcespnpm nx destroy @idp-v2/infraCommon Commands
Section titled “Common Commands”# Buildpnpm build:all # Build all packagespnpm nx build @idp-v2/infra # Build single package
# Testpnpm nx test @idp-v2/infra # Run testspnpm nx test @idp-v2/infra --update # Update snapshots
# Lintpnpm nx lint @idp-v2/infra # Lintpnpm nx lint @idp-v2/infra --configuration=fix # Auto-fixSupported Models
Section titled “Supported Models”AI Analysis Models
Section titled “AI Analysis Models”| Model | Purpose | Description |
|---|---|---|
| Claude Sonnet 4.6 | Segment analysis / Agent | Vision ReAct Agent, deep document analysis |
| Claude Sonnet 4.6 | Document summarization | Overall document summary generation |
| Claude Haiku 4.5 | Search summarization | Lightweight model for search result organization |
| TwelveLabs Pegasus 1.2 | Video visual analysis | Direct video understanding and scene analysis |
| Amazon Nova Lite 2 | Video script extraction | Large-context STT-based video script extraction |
| Nova Embed Text v2 | Vector embeddings | 1024-dimensional multimodal embeddings |
| Cohere Rerank v3.5 | Search reranking | Hybrid search result optimization |
Preprocessing Models
Section titled “Preprocessing Models”| Model | Purpose | Description |
|---|---|---|
| PP-OCRv5 / PP-StructureV3 | OCR (CPU) | Lambda container, general-purpose text extraction |
| PaddleOCR-VL | OCR (GPU) | SageMaker g5.xlarge, Vision-Language model, Auto-scaling 0->1 |
| Bedrock Data Automation | Document analysis | Async document structure analysis (optional) |
| AWS Transcribe | Speech-to-text | Audio/video text conversion |
MCP Tools
Section titled “MCP Tools”| Tool | Description |
|---|---|
| search_documents | Hybrid search across project documents (Vector + FTS + Rerank) |
| graph_search | Knowledge graph traversal to discover related pages |
| link_documents / unlink_documents | Manual document relationship management |
| overview | Project document overview and summaries |
| save/load/edit_markdown | Create and edit markdown artifacts |
| create_pdf, extract_pdf_text/tables | PDF generation and extraction |
| create_docx, extract_docx_text/tables | Word document generation and extraction |
| generate_image | AI image generation |
| code_interpreter | Python code execution sandbox |
Project Structure
Section titled “Project Structure”sample-aws-idp-pipeline/+-- packages/| +-- agents/ # AI agents| | '-- idp-agent/ # IDP Agent (Strands SDK)| +-- backend/app/ # FastAPI backend| | +-- main.py| | +-- config.py| | +-- ddb/ # DynamoDB modules| | +-- routers/ # API routers| | '-- services/ # Business logic| +-- common/constructs/src/ # Reusable CDK constructs| +-- frontend/src/ # React SPA| | +-- routes/ # Page routes| | '-- components/ # React components| +-- lambda/ # MCP tool Lambdas| | +-- search-mcp/ # Search tool (hybrid search + summarize)| | '-- graph-mcp/ # Graph tool (Neptune traversal)| '-- infra/src/| +-- stacks/ # 14 CDK stacks| +-- functions/ # Python Lambda functions| | +-- step-functions/ # Workflow functions| | +-- container/ # Container Lambda (LanceDB + Graph services)| | +-- shared/ # Shared modules| | +-- websocket/ # WebSocket handlers| | '-- lancedb-writer/ # LanceDB writer| '-- lambda-layers/ # Lambda layers+-- docs/ # Documentation (Astro)'-- README.mdTech Stack
Section titled “Tech Stack”Infrastructure (TypeScript)
Section titled “Infrastructure (TypeScript)”- AWS CDK 2.230.x + Nx 22.x
- AWS Step Functions (workflow orchestration)
- AWS Lambda + Lambda Layers
- API Gateway HTTP / REST / WebSocket
Backend (Python)
Section titled “Backend (Python)”- FastAPI (ECS Fargate, ARM64)
- LanceDB + S3 Express One Zone (vector storage)
- Neptune DB Serverless (knowledge graph)
- DynamoDB (One Table Design)
- Kiwi (Korean morphological analyzer)
- DuckDB (direct S3 queries)
Frontend (TypeScript)
Section titled “Frontend (TypeScript)”- React 19 + TanStack Router
- Tailwind CSS
- AWS SDK (S3 upload)
- Cognito OIDC authentication
- WebSocket client
AI / ML
Section titled “AI / ML”- Bedrock Agent Core (Strands SDK, ReAct pattern)
- Bedrock Claude Sonnet 4.6 / Haiku 4.5
- Bedrock Nova Embed (1024 dimensions)
- Bedrock Cohere Rerank v3.5
- TwelveLabs Pegasus 1.2 (video visual analysis)
- Amazon Nova Lite 2 (video script extraction)
- PaddleOCR (Lambda CPU + SageMaker GPU)
- AWS Transcribe