Vector Storage
Alternative Reference
If you looking to benchmark multiple LLMs and RAG engines in a simple way, you should checkout aws-samples/aws-genai-llm-chatbot. That project focuses more on experimentation with models and vector stores, while this project focuses more on building an extendable 3-tier application.
Currently, Galileo offers a single implementation for the storage of RAG vector embeddings: Aurora PostgreSQL Serverless with pgvector.
Postgres Table Naming
To support multiple embedding models and vector sizes, the current implementation creates a database table name based on normalized model id and vector size. If you change the embedding model, or vector size, it will create a new database table. Currently there is no support for choosing which database table to use at runtime, you must deploy the updates and re-index the data into the new table. We are working on a more scalable solution for this.
Getting data into the vector store
There is an indexing pipeline included in the Corpus stack which is a AWS Step Function state machine that is capable of processing a large amount of files in parallel (40k+ files). The pipeline supports incremental and bulk updates, and is configured to index all files in the "processed bucket" included in the corpus stack.
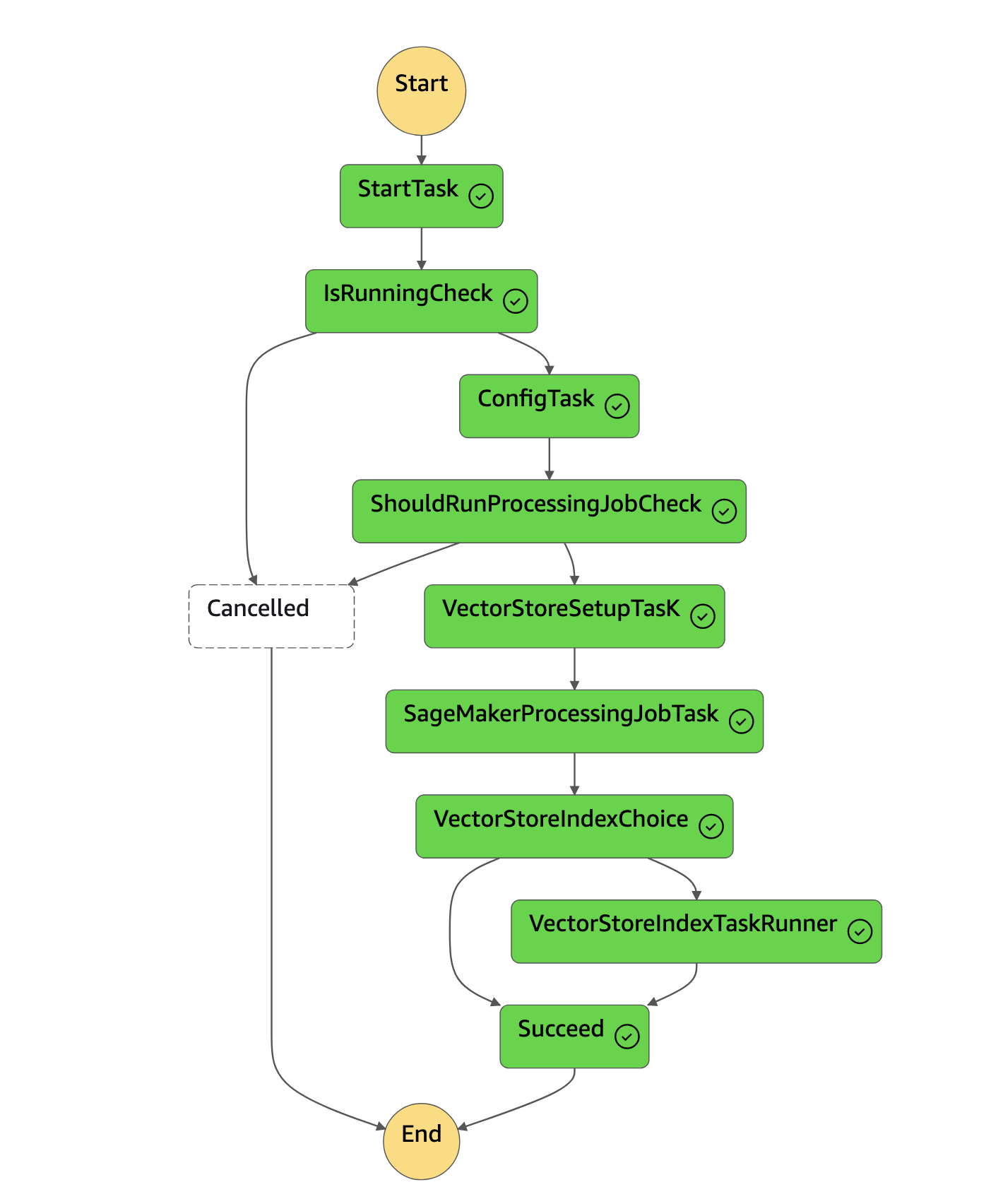 The "processed bucket" is the destination for objects that have already been processed, and expected to contain only raw text files with metadata defined on the objects. For data transformation, it is expected to have custom ETL processes for the data which will end up in this bucket.
The "processed bucket" is the destination for objects that have already been processed, and expected to contain only raw text files with metadata defined on the objects. For data transformation, it is expected to have custom ETL processes for the data which will end up in this bucket.
Example Only
This is very much an example architecture for data ingestion at scale, and is expected to be replaced or modified to support your specific use case. Rather than attempting to force your implementation into the current process, it is recommended to replace this based on your needs. As we learn more about the patterns customers are using, we will work on extending this to support more real world use cases.
Manual Process
Currently the state machine must be manually triggered. It also supports scheduling which is disabled by default, which can be configured in the corpus stack (demo/infra/src/application/corpus/index.ts) properties.
Data import flow
Using the CLI's Document Uploader, the document import flow is as follows:
sequenceDiagram
actor User
participant CLI
participant S3 as S3<br/>bucket
participant SFN as Indexing<br/>Workflow
participant VectorStore as Vector<br/>Store
participant SMJob as Sagemaker<br/>Processing Job
participant SMEmb as Sagemaker Endpoint<br/>Embedding model
autonumber
User ->> CLI: document upload
CLI ->> CLI: prepare data
CLI ->> S3: upload documents<br/>(with metadata)
CLI -->> User: trigger workflow?
User ->> CLI: yes
CLI -->> SFN: start execution
SFN ->> SFN: config workflow
SFN ->> S3: query changeset
S3 -->> SFN: objects
SFN ->> VectorStore: initialize<br/>vector store
SFN ->> SMJob: start processing job
activate SMJob
loop For each document
SMJob ->> SMEmb: toVector(document)
SMEmb -->> SMJob: vector
SMJob ->> VectorStore: upsert(vector)
end
SMJob -->> SFN: resume<br/>(processing job finished)
deactivate SMJob
alt Indexing on?
SFN ->> VectorStore: create/update<br/>index
end
Sample Dataset
The current sample dataset (US Supreme Court Cases), is defined as a stack which uses the CDK S3 Deployment construct to batch deploy data into the "processed bucket" with respective metadata. Additionally the sample data set stack will automatically trigger the state machine for indexing.
Being Deprecated
We are working on completely refactoring the way we handle sample data, and enable easy testing of other local data via the cli. Expect this to change very soon.
FAQs
How to load sample data for a demo?
If you deploy via the cli, you can choose to load the supplied sample dataset. To load your own data, run pnpm galileo-cli document upload --help to use the provided helper.
You can also manually add files to the S3 bucket provided with metadata, and then run the corpus state machine to perform indexing.
Embeddings
This project supports multiple embedding models through the CLI or the demo/infra/config.json file. Each embedding model is uniquely identified by a model reference key (a.b.a modelRefKey), which is a human-readable phrase composed of ASCII characters and digits.
In the following example, two embedding models are configured in the demo/infra/config.json file. One model utilizes the intfloat/multilingual-e5-base model, while the other employs the sentence-transformers/all-mpnet-base-v2 model.
<trimmed>
"rag": {
"managedEmbeddings": {
"instanceType": "ml.g4dn.xlarge",
"embeddingsModels": [
{
"uuid": "multilingual-e5-base",
"modelId": "intfloat/multilingual-e5-base",
"dimensions": 768,
"modelRefKey": "English",
"default": true
},
{
"uuid": "all-mpnet-base-v2",
"modelId": "sentence-transformers/all-mpnet-base-v2",
"dimensions": 768,
"modelRefKey": "Vietnamese"
}
],
"autoscaling": {
"maxCapacity": 5
}
},
},
<trimmed>
Embedding is handled by a SageMaker Endpoint that supports multiple models with a custom script. Through configuration, you can deploy multiple models for direct testing, and the application will use the specified model for runtime when the modelRefKey is provided in the embeddings request. If the modelRefKey is not provided, the default (or first) model will be used to serve the embeddings request.
Supports all AutoModels from transformers package.
packages/galileo-cdk/src/ai/llms/models/managed-embeddingspackages/galileo-cdk/src/ai/llms/models/managed-embeddings/custom.asset/code/inference.pydemo/infra/src/application/corpus
How to change embedding model for Chat?
In the Chat settings panel, navigate to the Semantic Search tab. From the Embedding Model dropdown list, select the desired embedding model.
How to change embedding model for indexing pipeline?
When submitting documents to indexing pipeline, you need to provide modelRefKey which is used to indicate which embedding model to use.
How to change document chunking?
Chunk size and overlap are not configurable via cli or config at this time, you will need to edit the source code.
demo/corpus/logic/src/env.tscontains the default env varsdemo/infra/src/application/corpus/index.tscontains env var overrides for the state machine
CHUNK_SIZE: "1000",
CHUNK_OVERLAP: "200",
How to filter data and improve search results?
Currently the backend support filtering, however the UI does not have controls for filtering yet. You will need to customize the UI and chat message api calls to support filtering at this time.
Pipeline StateMachine
See demo/infra/src/application/corpus/pipeline/types.ts for all configuration options.
How to start indexing objects in S3?
Just start an execution of the Pipeline StateMachine from the StepFunction console with the default payload. It will auto-detect new/modified files and will index them, or if everything is new it will bulk index everything. If you change the embedding model and run execution, it will create a new database table and index for the new embeddings.
How do I force BULK re-indexing?
If you want to force re-indexing everything, use the following payload.
{
"IndexingStrategy": "BULK",
"SubsequentExecutionDelay": 0,
"ModifiedSince": 1
}
How to test indexing on a small sample set?
You can limit the number of files that are processed with the following payload.
{
"MaxInputFilesToProcess": 1000,
"IndexingStrategy": "MODIFIED",
"SubsequentExecutionDelay": 0,
"TargetContainerFilesCount": 500,
"ModifiedSince": 1
}
Process the first 1000 files, across 2 containers
How do I override environment variables?
You can override environment variables from the payload as well (make sure all keys and values are string):
{
"IndexingStrategy": "BULK",
"SubsequentExecutionDelay": 0,
"ModifiedSince": 1,
"Environment": { "CHUNK_SIZE": "2000", "CHUNK_OVERLAP": "400" }
}
Bulk reindexing with custom chunksize
How to reset vector store data?
The state machine can be executed with the following payload to delete the database table data (TRUNCATE), reset the index, and force bulk re-indexing.
{
"VectorStoreManagement": {
"PurgeData": true,
"CreateIndexes": false
}
}