Mental model
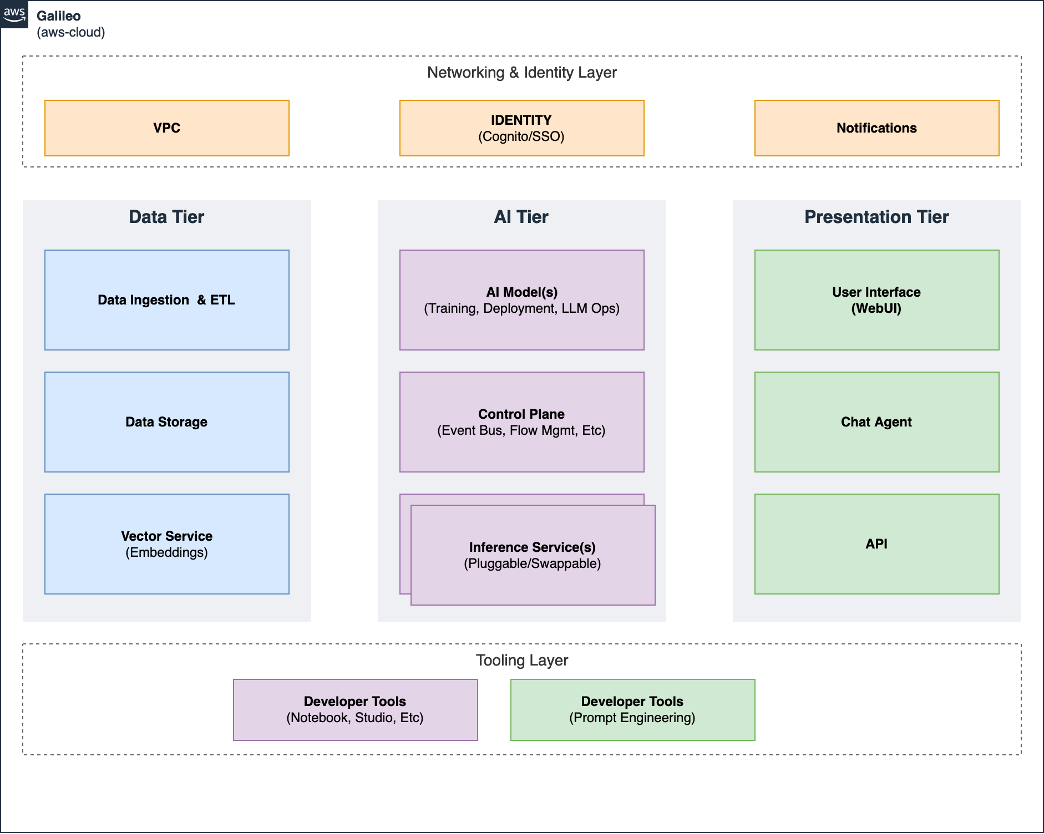
The mental model for the Galileo Generative AI Reference Sample is designed as a multi-tier architecture:
- Data Tier: This tier is responsible for data ingestion, storage, and transformation (ETL), and provide an API for querying data and performing operations against the data.
- AI Tier: This tier involves the core machine learning model development, training, tuning, and deployment (ML Ops), and all inferences.
- Presentation Tier: This tier manages user interaction, result presentation, and integration with other systems. Users can input queries or requests and receive responses generated by the AI model. The presentation tier can consist of web interfaces, mobile apps, or any other user-facing interface. The Client-side Chat Agent and similar prompt session management is core this to layer.
- Networking & Identity Layer: Shared layer for networking and identity resources, such as VPC and Cognito.
- Tooling Layer: This tier has the supporting tooling necessary for developers to build Generative AI applications. The tooling tier consists of supporting interfaces for developers (Notebooks, IDE tools, etc) and specific interfaces for generative AI (Prompt engineering etc).
The high-level components shown illustrates the adapted three-tier architecture we used to form the mental model when designing the architecture for this sample.
Data Tier
This tier is responsible for data ingestion, storage, and transformation (ETL), including the Vector Store for embeddings.
Data processing and transformation: Depending on the application, there might be additional components for data processing and transformation. For example, in natural language processing tasks, text preprocessing, entity extraction, or semantic analysis modules may be required to enhance the AI processing and improve the accuracy of the generated responses.
AI Tier
This tier involves the core machine learning model development, training, tuning, and deployment stages, along with all inference related services, and a control plane to choreograph more complex use cases.
This tier is where the generative AI model resides. It performs the main processing and generates responses based on the user inputs received from the presentation tier. The AI model can be a large language model, a stable diffusion image generation model, or a deep learning model specifically designed for a particular task, such as image generation or music composition. The AI processing tier involves complex algorithms, machine learning models, and compute infrastructure to perform the AI processing efficiently.
Inference Engine: The inference engine is responsible for running the trained AI model to generate responses in real-time. It takes user inputs, processes them using the AI model, and produces the corresponding output. You can optimize this component for high-performance inference to handle concurrent user requests efficiently.
Presentation Tier (Application)
The presentation tier is similar to a traditional three-tier architecture. It handles the user interface and interaction with the system. Users can input queries or requests and receive responses generated by the AI model. The presentation tier can consist of web interfaces, mobile apps, or any other user-facing interface.