How RAG (Retrieval Augmented Generation) Applications Work
This will not be new information if your are familiar with retrieval augmented generation (RAG) flows. The goal of Galileo is not to re-invent RAG applications, instead it focuses on repeatability, reusability, experimentation, and scalability.
There are three key components of RAG flows:
- Chat History: the dialog between end-user and the AI
- Corpus: the knowledge base the AI should use
- Inference: the actual LLM performing the task
It is pretty straightforward, but when you consider statelessness of LLM, token limitation, quality and robustness of corpus dataset, size of corpus, developer experience of changing models, variations of prompt formatting between models, and much more, it quickly starts to become very complex.
Chat Experience
The key to conversational chat is persistence of the context between dialogs, basically the ability to infer the meaning of a word like this based on chat history.

Generic RAG flow
Here is what that looks like at a high-level in the backend:
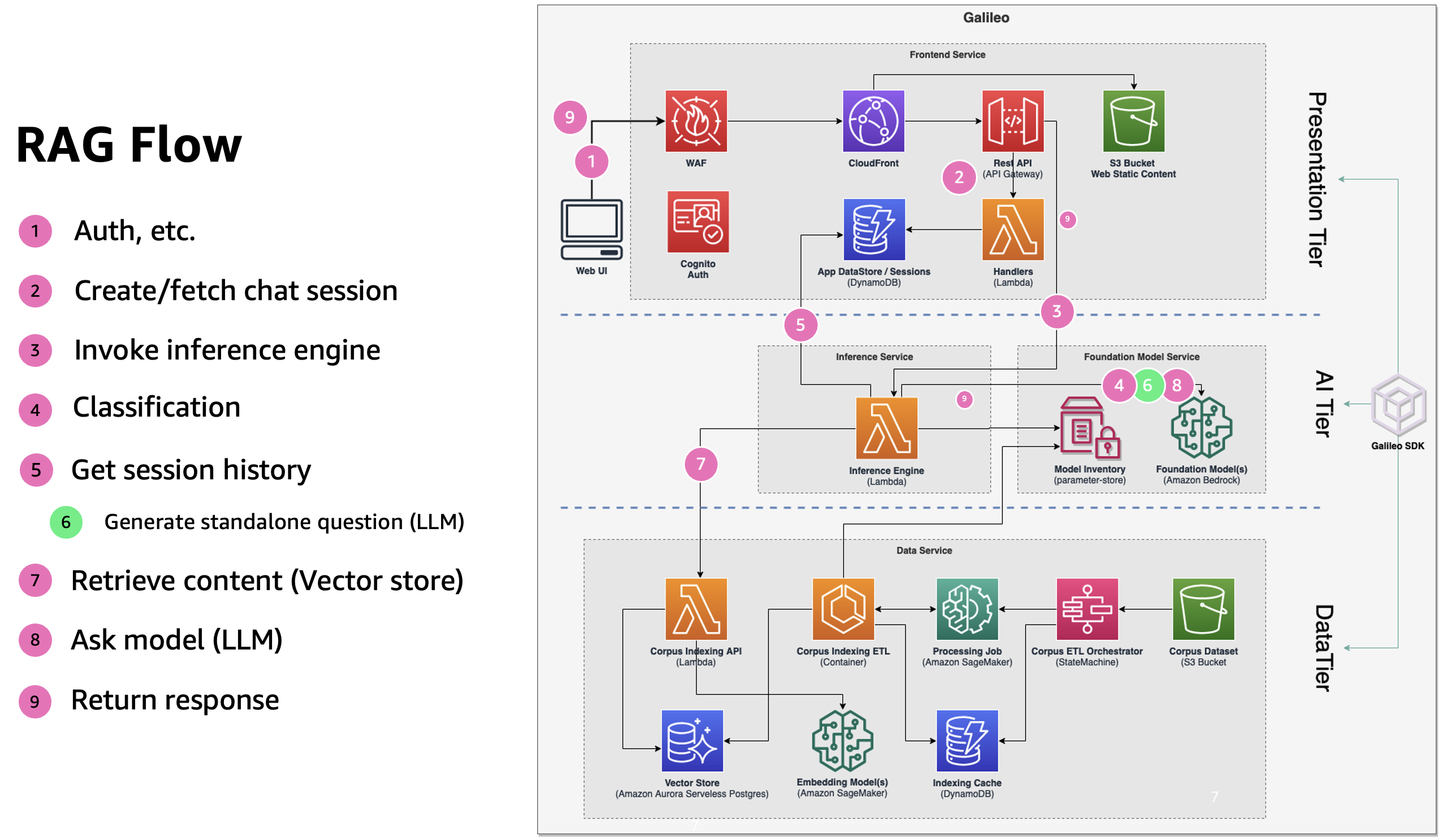
Chat data flow
Here is the detailed flow for a question-answer (once authenticated with the system):
sequenceDiagram
actor User
box Presentation Tier
participant WebUI
participant API as RestAPI
end
box Data Tier
participant DDB as ChatDB
participant Config
participant VectorStore as Vector<br/>Store
end
box AI Tier
participant Engine as InferenceEngine
participant LLMClassify as LLM<br/>(classify)
participant LLMCondense as LLM<br/>(condense)
participant LLMQA as LLM<br/>(standalone question)
end
autonumber
User ->> WebUI: question
WebUI ->> API: createChatMessage(question)
API ->> Engine: createChatMessage(question)
Engine ->> DDB: saveMessage(question)
alt Classification
rect
Engine ->> Config: getClassificationPrompt
Config -->> Engine: classifyPrompt
Engine ->> LLMClassify: invokeLLM(<br/>question, classifyPrompt)
LLMClassify -->> Engine: classificationJSON
end
end
alt Condense (use message history)
rect
Engine ->> Config: getCondensePrompt
Config -->> Engine: prompt
Engine ->> DDB: getChatHistory
DDB -->> Engine: messages
Engine ->> LLMCondense: invokeLLM(question, messages)
LLMCondense -->> Engine: question
end
end
Engine ->> VectorStore: semanticSearch(question)
VectorStore -->> Engine: sources
Engine ->> Config: getQAPrompt
Config -->> Engine: prompt
Engine ->> Engine: buildLLMRequest(<br/>prompt, question,<br/>sources, classificationJSON?)
Engine ->> LLMQA: invokeLLM(request)
LLMQA -->> Engine: answer
Engine ->> DDB: saveMessage(answer)
Engine -->> API: answer
API -->> WebUI: answer
WebUI -->> User: answer